6 リスト

本格的にプログラムを書き始める前に理解しておく必要がある事柄がもう少しあります。リスト型とタプル型のデータ型です。リストとタプルは複数の値を保持できるので、これらを使うと大量のデータを扱うプログラムを書きやすくなります。リストの中にリストを入れることができるので、階層構造のデータを扱えます。
本章では、リストの基礎を説明します。特定のデータ型と結びついた関数である、メソッドの説明をします。シーケンス型(リスト、タプル、文字列)について簡単に解説し、その異同を確認します。次章では、辞書型のデータ型を紹介します。
リスト型
リスト は複数の値を順番に保持する値です。リスト値 という語は、リスト自体(ほかの値と同じように変数に格納したり関数に渡したりできます)を指し示すのであって、リスト値の中に入っている値を指し示すのではありません。リスト値は['cat', 'bat', 'rat', 'elephant']のような形をしています。文字列値がクォーテーションマーク(')で囲まれるのと同じように、リストは開き角かっこ([)で始まり閉じ角かっこ(])で終わります。
リストの中に入っている値を要素(アイテム)と呼びます。要素はカンマで分割されます(カンマ区切り)。対話型シェルで次のように入力してみてください。
>>> [1, 2, 3] # 3つの整数のリスト
[1, 2, 3]
>>> ['cat', 'bat', 'rat', 'elephant'] # 4つの文字列のリスト
['cat', 'bat', 'rat', 'elephant']
>>> ['hello', 3.1415, True, None, 42] # いろいろな値のリスト
['hello', 3.1415, True, None, 42]
❶ >>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam
['cat', 'bat', 'rat', 'elephant']
変数spamには一つの値が代入されています(❶)。リスト値です。リスト値は他の値を含みます。
[]は中に値が入っていない空リストです。''が空文字列であるのと似ています。
インデックス
spamという名前の変数に['cat', 'bat', 'rat', 'elephant']というリストが格納されているとします。Pythonのspam[0]というコードは'cat'に評価され、spam[1]は'bat'に評価されます。リストに続く角かっこ内の整数はインデックスと呼ばれます。リストの最初の値はインデックス0で、2番目の値がインデックス1、3番目の値がインデックス2です。図6-1はspamに代入されたリスト値をインデックスとともに示しています。インデックスは0から始まりますから、最後のインデックスはリストのサイズより1小さくなります。4つの要素のリストの最後のインデックスは3です。

図 6-1:変数spamに格納されたリストとインデックスの対応
インデックスを試してみるために、次の式を対話型シェルに入力してください。変数spamにリストを代入するところから始めます。
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[0]
'cat'
>>> spam[1]
'bat'
>>> spam[2]
'rat'
>>> spam[3]
'elephant'
>>> ['cat', 'bat', 'rat', 'elephant'][3]
'elephant'
❶ >>> 'Hello, ' + spam[0]
❷ 'Hello, cat'
>>> 'The ' + spam[1] + ' ate the ' + spam[0] + '.'
'The bat ate the cat.'
式'Hello, ' + spam[0](❶)が'Hello, ' + 'cat'に評価されます。spam[0]が'cat'に評価されるからです。この式はさらに文字列'Hello, cat'に評価されます(❷)。
リストに入っている要素の個数を超えるインデックスを使うと、PythonはIndexError というエラーメッセージを表示します。
>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[10000]
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
spam[10000]
IndexError: list index out of range
リストの中にリストを入れることもできます。次のように、インデックスを複数書けば、リストの中のリストにアクセスできます。
>>> spam = [['cat', 'bat'], [10, 20, 30, 40, 50]]
>>> spam[0]
['cat', 'bat']
>>> spam[0][1]
'bat'
>>> spam[1][4]
50
最初のインデックスがどのリスト値かを指定し、2つ目のインデックスがそのリスト値の中の値を指し示します。例えば、spam[0][1]は'bat'になります。最初のリスト値の中の2番目の値です。
負の数のインデックス
インデックスは0から始まって増えていきますが、負の整数をインデックスに使うこともできます。対話型シェルで次のように入力してみてください。
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[-1] # 最後のインデックス
'elephant'
>>> spam[-3] # 最後から3番目のインデックス
'bat'
>>> 'The ' + spam[-1] + ' is afraid of the ' + spam[-3] + '.'
'The elephant is afraid of the bat.'
-1という整数はリストの最後のインデックスで、-2は最後から2番目のインデックスです。
スライス
インデックスでリストから1つの値を取り出せるように、スライスでリストから複数の値を新しいリストの形式で取り出せます。スライスは、インデックスと同じように、角カッコの中で指定しますが、コロンの前後に2つの数値が入ります。インデックスとスライスの違いは次のとおりです。
- spam[2]はリストのインデックスです(角かっこの中に整数が1つ)
- spam[1:4]はリストのスライスです(角かっこの中に整数が2つ)
スライスでは、最初の整数がスライスを開始するインデックスで、2つ目の整数がスライスを終了するインデックスです。スライスにより作られたリストは、2つ目の整数のインデックスが指す値まで元のリストを切り取りますが、その値は含みません。対話型シェルで次のように入力してみてください。
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[0:4]
['cat', 'bat', 'rat', 'elephant']
>>> spam[1:3]
['bat', 'rat']
>>> spam[0:-1]
['cat', 'bat', 'rat']
短縮記法として、コロンの片側あるいは両側のインデックスを省略できます。
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[:2]
['cat', 'bat']
>>> spam[1:]
['bat', 'rat', 'elephant']
>>> spam[:]
['cat', 'bat', 'rat', 'elephant']
最初のインデックス(コロンの左側)を省略すると、0を指定したのと同じになり、リストの最初からになります。2つ目のインデックス(コロンの右側)を省略すると、リストの長さを指定したのと同じになり、リストの最後までになります。
len()関数
len()関数にリスト値を渡すと、そのリストに入っている値の個数を返します。対話型シェルで次のように入力してみてください。
>>> spam = ['cat', 'dog', 'moose']
>>> len(spam)
3
これはこの関数が文字列値の文字数をカウントするのに似ています。
値の更新
通常、spam = 42のように、代入文の左側には変数名が来ます。リストのインデックスを使って、そのインデックスの値を変更することもできます。
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[1] = 'aardvark'
>>> spam
['cat', 'aardvark', 'rat', 'elephant']
>>> spam[2] = spam[1]
>>> spam
['cat', 'aardvark', 'aardvark', 'elephant']
>>> spam[-1] = 12345
>>> spam
['cat', 'aardvark', 'aardvark', 12345]
この例で、spam[1] = 'aardvark'は「リストspamのインデックス1の値に文字列'aardvark'を代入する」という意味になります。-1のような負の数をインデックスに指定して値を更新することもできます。
結合と繰り返し
+演算子と*演算子でリストの結合と繰り返しをできます。
>>> [1, 2, 3] + ['A', 'B', 'C']
[1, 2, 3, 'A', 'B', 'C']
>>> ['X', 'Y', 'Z'] * 3
['X', 'Y', 'Z', 'X', 'Y', 'Z', 'X', 'Y', 'Z']
>>> spam = [1, 2, 3]
>>> spam = spam + ['A', 'B', 'C']
>>> spam
[1, 2, 3, 'A', 'B', 'C']
+演算子は2つのリストを結合して新しいリスト値を作ります。*演算子はリストを整数回繰り返して結合します。
del文
del文はリストのインデックスを指定してその値を削除します。削除された値よりあとにある値はすべてインデックスが1つ繰り上がります。対話型シェルで次のように入力してみてください。
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> del spam[2]
>>> spam
['cat', 'bat', 'elephant']
>>> del spam[2]
>>> spam
['cat', 'bat']
del文は「非代入」文のように変数自体を削除するのにも使えます。変数を削除してから使おうとすると、もうその変数は存在しなくなっているので、NameErrorエラーが発生します。実務的には、変数自体を削除する必要はまずありませんが、リストから値を削除するのにdel文は使えます。
リストの操作
プログラムを書き始めた頃には、一連の値を格納する変数をバラバラに作りたくなるかもしれません。例えば、自分が飼っているネコの名前を格納しようと、次のようなコードを書くかもしれません。
cat_name_1 = 'Zophie'
cat_name_2 = 'Pooka'
cat_name_3 = 'Simon'
cat_name_4 = 'Lady Macbeth'
これはよろしくないコードです。一つには、ネコの数が変わった場合に(飼っているネコが増える可能性があります)、変数を用意した数以上のネコの名前を保持することができません。また、このプログラムにはほとんど同じコードの繰り返しが多いという問題もあります。このことを確認するために、次のコードをallMyCats1.pyという名前で保存してください。
print('Enter the name of cat 1:')
cat_name_1 = input()
print('Enter the name of cat 2:')
cat_name_2 = input()
print('Enter the name of cat 3:')
cat_name_3 = input()
print('Enter the name of cat 4:')
cat_name_4 = input()
print('The cat names are:')
print(cat_name_1 + ' ' + cat_name_2 + ' ' + cat_name_3 + ' ' + cat_name_4)
複数の繰り返しのような変数を使わずに、リスト値を含む1つの変数を使うことができます。例えば、以下のようにallMyCats1.pyプログラムを改良します。この新しいバージョンでは、1つのリストを使い、何匹のネコの名前でも保持できます。新しいファイルエディタウィンドウで、次のコードをallMyCats2.pyという名前で保存してください。
cat_names = []
while True:
print('Enter the name of cat ' + str(len(cat_names) + 1) +
' (Or enter nothing to stop.):')
name = input()
if name == '':
break
cat_names = cat_names + [name] # リストの結合
print('The cat names are:')
for name in cat_names:
print(' ' + name)
このプログラムを実行すると、次のように出力されます。
Enter the name of cat 1 (Or enter nothing to stop.):
Zophie
Enter the name of cat 2 (Or enter nothing to stop.):
Pooka
Enter the name of cat 3 (Or enter nothing to stop.):
Simon
Enter the name of cat 4 (Or enter nothing to stop.):
Lady Macbeth
Enter the name of cat 5 (Or enter nothing to stop.):
The cat names are:
Zophie
Pooka
Simon
Lady Macbeth
リストを使えばデータが構造化され、繰り返しのような変数を使う場合よりも柔軟にデータを処理できます。
forループとリスト
第3章では、forループを使ってコードのブロックを指定した回数だけ実行する方法を学習しました。技術的には、forループはコードブロックをリスト中の要素の個数回だけ繰り返し実行します。例えば、次のコードを実行してください。
for i in range(4):
print(i)
このプログラムの出力は次のようになります。
0
1
2
3
range(4)が返す値は、[0, 1, 2, 3]と似たシーケンス値(連続値)です。以下のプログラムは上のプログラムと同じ出力になります。
for i in [0, 1, 2, 3]:
print(i)
このforループは、変数iにリスト[0, 1, 2, 3]の値を順番に設定して節を実行します。
Pythonでは、forループでrange(len(some_list))を使ってリストのインデックスを反復処理することがよくあります。対話型シェルで次のように入力してみてください。
>>> supplies = ['pens', 'staplers', 'flamethrowers', 'binders']
>>> for i in range(len(supplies)):
... print('Index ' + str(i) + ' in supplies is: ' + supplies[i])
...
Index 0 in supplies is: pens
Index 1 in supplies is: staplers
Index 2 in supplies is: flamethrowers
Index 3 in supplies is: binders
for ループでrange(len(supplies))を使うと、ループ中のコードでインデックス(i)とそのインデックスに対応する値(supplies[i])の両方にアクセスできるので便利です。何と言っても、range(len(supplies))はリストsuppliesの中に入っている要素の個数に関わらずすべてのインデックスを反復処理できます。
in演算子とnot in演算子
in演算子とnot in演算子を使うと、ある値がリストの中に入っているかどうかを判定できます。他の演算子と同様に、inとnot inは式中の2つの値の間で使います。探す値と探すリストの間で使います。その式はブール値に評価されます。対話型シェルに以下のコードを入力して確かめてみましょう。
>>> 'howdy' in ['hello', 'hi', 'howdy', 'heyas']
True
>>> spam = ['hello', 'hi', 'howdy', 'heyas']
>>> 'cat' in spam
False
>>> 'howdy' not in spam
False
>>> 'cat' not in spam
True
以下のプログラムは、ユーザーが入力したペットの名前がリストの中にあるかどうかを判定します。新しいファイルエディタウィンドウを開いて、以下のコードをmyPets.pyという名前で保存してください。
my_pets = ['Zophie', 'Pooka', 'Fat-tail']
print('Enter a pet name:')
name = input()
if name not in my_pets:
print('I do not have a pet named ' + name)
else:
print(name + ' is my pet.')
出力は次のようになります。
Enter a pet name:
Footfoot
I do not have a pet named Footfoot
not in演算子はnotブール演算子と別物であることに注意してください。
多重代入
多重代入は、技術的にはタプルアンパックと呼ばれますが、複数の変数にリストの値を1行で代入する短縮記法です。次のようにする代わりに
>>> cat = ['fat', 'gray', 'loud']
>>> size = cat[0]
>>> color = cat[1]
>>> disposition = cat[2]
次のようにできるということです。
>>> cat = ['fat', 'gray', 'loud']
>>> size, color, disposition = cat
変数の個数とリストの要素数は一致しなければなりません。一致しなければValueErrorエラーが発生します。
>>> cat = ['fat', 'gray', 'loud']
>>> size, color, disposition, name = cat
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
size, color, disposition, name = cat
ValueError: not enough values to unpack (expected 4, got 3)
多重代入を使うと複数行で代入するよりもコードが短く読みやすくなります。
リストの要素の数え上げ
forループでリストの要素のインデックスを取得するのに、range(len(some_list))の代わりに、enumerate()関数を呼び出すこともできます。ループの反復ごとに、enumerate()は、リストの要素のインデックスと要素そのものの2つの値を返します。例えば、このコードは「forループとリスト」で紹介したコードと同じ動きをします。
>>> supplies = ['pens', 'staplers', 'flamethrowers', 'binders']
>>> for index, item in enumerate(supplies):
... print('Index ' + str(index) + ' in supplies is: ' + item)
...
Index 0 in supplies is: pens
Index 1 in supplies is: staplers
Index 2 in supplies is: flamethrowers
Index 3 in supplies is: binders
ループで要素と要素のインデックスの両方が必要な場合に、enumerate()関数が役立ちます。
ランダム選択と順序
randomモジュールにはリストを引数に取る関数がいくつかあります。random.choice()関数はリストから要素をランダムに選んで返します。以下の式を対話型シェルに入力してみてください。
>>> import random
>>> pets = ['Dog', 'Cat', 'Moose']
>>> random.choice(pets)
'Cat'
>>> random.choice(pets)
'Cat'
>>> random.choice(pets)
'Dog'
random.choice(some_list)はsome_list[random.randint(0, len(some_list) – 1]を簡単に書いたものだと考えられます。
random.shuffle()関数はリストの要素の順番をその場でシャッフルします。以下の式を対話型シェルに入力してみてください。
>>> import random
>>> people = ['Alice', 'Bob', 'Carol', 'David']
>>> random.shuffle(people)
>>> people
['Carol', 'David', 'Alice', 'Bob']
>>> random.shuffle(people)
>>> people
['Alice', 'David', 'Bob', 'Carol']
この関数は、新しいリストを返すのではなく、リストをその場で変更します。
累算代入演算子(複合代入演算子)
文字列に対して使える+演算子と*演算子は、リストに対しても使えます。ちょっと寄り道して累算代入演算子の説明をします。変数に値を代入するときにその変数を使うことはよくあります。例えば、変数spamに42を代入してから、その値を1増やす場合に、次のようなコードを書くでしょう。
>>> spam = 42
>>> spam = spam + 1
>>> spam
43
+=累算代入演算子(イコール記号のあとに通常の演算子を書きます)を使えば同じ内容を短く書けます。
>>> spam = 42
>>> spam += 1
>>> spam
43
+、-、*、/、%の累算代入演算子を表6-1にまとめました。
累算代入演算子 |
同等の代入文 |
|---|---|
spam += 1 |
spam = spam + 1 |
spam -= 1 |
spam = spam - 1 |
spam *= 1 |
spam = spam * 1 |
spam /= 1 |
spam = spam / 1 |
spam %= 1 |
spam = spam % 1 |
+=演算子は文字列の結合やリストの結合ができますし、*=演算子は文字列の繰り返しやリストの繰り返しができます。以下の式を対話型シェルに入力してみてください。
>>> spam = 'Hello,'
>>> spam += ' world!' # spam = spam + 'world!'と同じ
>>> spam
'Hello, world!'
>>> bacon = ['Zophie']
>>> bacon *= 3 # bacon = bacon * 3と同じ
>>> bacon
['Zophie', 'Zophie', 'Zophie']
多重代入と同じように、累算代入演算子はコードを短くて読みやすくする短縮記法です。
メソッド
メソッドは、値について呼び出される関数のことです。例えば、spamにリスト値が格納されているとしたら、spam.index('hello')のようにそのリスト値についてindex()リストメソッド(すぐあとで説明します)を呼び出せます。値とドット(.)に続けてメソッド名を書きます。
それぞれのデータ型には所定のメソッドがあります。リスト型だと、リストの中に入っている値の検索、追加、削除、その他の操作をできるメソッドがあります。メソッドは値と必然的に結びついている関数であると捉えることができます。リスト値がspamに格納されている先ほどの例で言うと、index(spam, 'hello')のように関数を呼び出すと考えることができます(実際にこのような呼び出し方はできず、あくまでも考え方です)。index()はリストメソッドであって関数ではありませんから、spam.index('hello')と呼び出します。リスト値についてindex()を呼び出すと、Pythonはindex()をリストメソッドとして扱います。以下ではリストメソッドについて説明します。
値の検索
リスト値には値を渡せるindex()メソッドがあります。その値がリストの中に存在すれば、その値のインデックスを返します。その値がリストの中に存在しなければ、ValueErrorエラーが発生します。以下の式を対話型シェルに入力してみてください。
>>> spam = ['hello', 'hi', 'howdy', 'heyas']
>>> spam.index('hello')
0
>>> spam.index('heyas')
3
>>> spam.index('howdy howdy howdy')
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
spam.index('howdy howdy howdy')
ValueError: 'howdy howdy howdy' is not in list
その値がリストの中に複数存在すれば、最初に見つかった値のインデックスを返します。
>>> spam = ['Zophie', 'Pooka', 'Fat-tail', 'Pooka']
>>> spam.index('Pooka')
1
index()は3ではなく1を返します。
値の追加
リストに新しい値を追加するには、append()メソッドとinsert()メソッドを使います。append()メソッドはリストの最後に値を追加します。
>>> spam = ['cat', 'dog', 'bat']
>>> spam.append('moose')
>>> spam
['cat', 'dog', 'bat', 'moose']
insert()メソッドは、リストのどこにでも値を追加することができます。insert()の第一引数は値を挿入するインデックスで、第二引数は挿入する値です。以下の式を対話型シェルに入力してみてください。
>>> spam = ['cat', 'dog', 'bat']
>>> spam.insert(1, 'chicken')
>>> spam
['cat', 'chicken', 'dog', 'bat']
これは、spam = spam.append('moose')やspam = spam.insert(1, 'chicken')のような代入文ではないことに注意してください。append()とinsert()の返り値はNoneですので、それを新しい変数の値として格納することはないでしょう。これらのメソッドはリストをその場で変更します。「ミュータブルとイミュータブル」で詳しく説明します。
データ型ごとにメソッドがあります。append()とinsert()はリストメソッドで、リスト値についてのみ呼び出せます。文字列値や整数値について呼び出すことはできません。そのようなことをしようとするとどうなるか、対話型シェルで以下のコードを入力して確かめてみます。
>>> eggs = 'hello'
>>> eggs.append('world')
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
eggs.append('world')
AttributeError: 'str' object has no attribute 'append'
>>> bacon = 42
>>> bacon.insert(1, 'world')
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
bacon.insert(1, 'world')
AttributeError: 'int' object has no attribute 'insert'
AttributeErrorエラーメッセージが表示されます。
値の削除
remove()メソッドはリストから削除したい値を引数に取ります。
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam.remove('bat')
>>> spam
['cat', 'rat', 'elephant']
リストの中に存在しない値を削除しようとすると、ValueErrorエラーが発生します。例えば、対話型シェルで次のように入力して、エラーメッセージが表示されるのを確認してください。
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam.remove('chicken')
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
spam.remove('chicken')
ValueError: list.remove(x): x not in list
リストの中に複数回登場する値については、最初の値のみが削除されます。
>>> spam = ['cat', 'bat', 'rat', 'cat', 'hat', 'cat']
>>> spam.remove('cat')
>>> spam
['bat', 'rat', 'cat', 'hat', 'cat']
リストから削除したい値のインデックスがわかっている場合はdel文を使い、値をもとに削除したい場合はremove()メソッドを使います。
値の並べ替え
数値のリストまたは文字列のリストについては、sort()メソッドで並べ替えできます。対話型シェルで次のように入力してみてください。
>>> spam = [2, 5, 3.14, 1, -7]
>>> spam.sort()
>>> spam
[-7, 1, 2, 3.14, 5]
>>> spam = ['Ants', 'Cats', 'Dogs', 'Badgers', 'Elephants']
>>> spam.sort()
>>> spam
['Ants', 'Badgers', 'Cats', 'Dogs', 'Elephants']
数値については小さい順、文字列についてはアルファベット順に並べ替えます。reverseキーワード引数(名前付きパラメータ)にTrueを渡すと、値を逆順に並べ替えられます。
>>> spam.sort(reverse=True)
>>> spam
['Elephants', 'Dogs', 'Cats', 'Badgers', 'Ants']
sort()メソッドについては次の3点に注意してください。第一に、リストをその場で並べ替えますので、spam = spam.sort()のように返り値を変数に格納しないでください。
第二に、数値と文字列値が混在しているリストを並べ替えることはできません。どのように並べ替えたらよいかわからないからです。以下のコードを対話型シェルに入力すると、 TypeErrorエラーが発生します。
>>> spam = [1, 3, 2, 4, 'Alice', 'Bob']
>>> spam.sort()
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
spam.sort()
TypeError: '<' not supported between instances of 'str' and 'int'
第三に、文字列については、正確に言うと、アルファベット順ではなくASCII順に並べ替えます。大文字は小文字の後に来るので、小文字のaは大文字のZの後に来ます。例えば、次のように対話型シェルに入力してください。
>>> spam = ['Alice', 'ants', 'Bob', 'badgers', 'Carol', 'cats']
>>> spam.sort()
>>> spam
['Alice', 'Bob', 'Carol', 'ants', 'badgers', 'cats']
アルファベット順に値を並べ替えたければ、sort()メソッドを呼び出すときに、キーワード引数keyにstr.lowerを渡してください。
>>> spam = ['a', 'z', 'A', 'Z']
>>> spam.sort(key=str.lower)
>>> spam
['a', 'A', 'z', 'Z']
この引数は、リストの中に入っている値を変更しませんが、あたかもすべて小文字であるかのように扱います。
値を逆の順番にする
リストの中に入っている要素の順番を逆にする必要があれば、reverse()リストメソッドを呼び出します。以下の式を対話型シェルに入力してみてください。
>>> spam = ['cat', 'dog', 'moose']
>>> spam.reverse()
>>> spam
['moose', 'dog', 'cat']
sort()リストメソットと同様に、reverse()はリストを返しません。ですので、spam = spam.reverse()ではなくspam.reverse()と書きます。
短絡ブール演算子
ブール演算子には見逃しやすい振る舞いがあります。and演算子でつながれた値のどちらか一方でもFalseなら式全体がFalseになり、or演算子でつながれた値のどちらか一方でもTrueなら式全体がTrueになることを思い出してください。False and spamという式があるとすると、変数spamがTrueだろうがFalseだろうが関係なく、式全体はFalseになります。同じことはTrue or spamにも言え、spamの値に関係なく式全体はTrueになります。
Pythonは(他のプログラミング言語でもたいていそうですが)、この事実を利用してブール演算子の右側を調べずにコードを少しでも速く実行できるように最適化します。これは短絡と呼ばれます。多くの場合、Pythonが式全体を評価しなくても(数マイクロ秒速くなることを別として)振る舞いに変わりありません。ただし、この短絡という性質が違いをもたらす場合があります。リストの最初の要素が'cat'かどうかを調べる次のプログラムを見てください。
spam = ['cat', 'dog']
if spam[0] == 'cat':
print('A cat is the first item.')
else:
print('The first item is not a cat.')
このプログラムはA cat is the first item.と表示します。しかし、リストspamが空だと、spam[0]がIndexError: list Index out of rangeエラーを引き起こします。これを修正するために、短絡を活用してif文の条件を調整します。
spam = []
if len(spam) > 0 and spam[0] == 'cat':
print('A cat is the first item.')
else:
print('The first item is not a cat.')
このプログラムがエラーを発生させることはありません。len(spam) > 0 がFalseだと(リストspamが空だと)、短絡and演算子は、IndexErrorエラーを発生させるspam[0] == 'cat'のコードを無視します。and演算子やor演算子を使うときには、この短絡を頭の片隅に置いておいてください。
短いプログラム:リストを使った魔法の8ボール
リストを使うと、第4章のmagic8Ball.pyプログラムをもっとエレガントに書くことができます。ほぼ同じelif文を何度も書かずに一つのリストを作成します。 新しいファイルエディタウィンドウを開いて、以下のコードをmagic8Ball2.pyという名前で保存してください。
import random
messages = ['It is certain',
'It is decidedly so',
'Yes definitely',
'Reply hazy try again',
'Ask again later',
'Concentrate and ask again',
'My reply is no',
'Outlook not so good',
'Very doubtful']
print('Ask a yes or no question:')
input('>')
print(messages[random.randint(0, len(messages) - 1)])
このプログラムを実行すると、第4章のmagic8Ball.pyと同じ動作をします。
random.randint(0, len(messages) - 1)を呼び出してランダムな数値を生成し、その数値をインデックスに使います。messagesのサイズが変わっても同じように動作します。つまり、0からlen(messages) - 1までのランダムな数値を生成します。このアプローチでは、コードの他の行を変更せずにリストmessagesへのメッセージの追加や削除が簡単にできます。あとでコードを変更するときに変更しなければならない行が少なければ、それだけバグを混入する可能性も少なくなります。
リストからランダムに要素を選択することはよくありますから、random.randint(0, len(messages) – 1)と同じ動作をするrandom.choice(messages)関数が存在します。
シーケンス型
順序付けられた値を表すのはリストに限られません。例えば、文字列を文字のリストだと考えれば、文字列とリストは似ています。Pythonのシーケンス型には、リスト、文字列、range()関数の返り値であるrangeオブジェクト、タプル(すぐあとの「タプル型」で説明します)が含まれます。リストでできることは文字列その他のシーケンス型でもできます。それを確かめるために、以下のように対話型シェルで試してみましょう。
>>> name = 'Zophie'
>>> name[0]
'Z'
>>> name[-2]
'i'
>>> name[0:4]
'Zoph'
>>> 'Zo' in name
True
>>> 'z' in name
False
>>> 'p' not in name
False
>>> for i in name:
... print('* * * ' + i + ' * * *')
...
* * * Z * * *
* * * o * * *
* * * p * * *
* * * h * * *
* * * i * * *
* * * e * * *
インデックスによる取得、スライス、forループ、len()関数、in演算子とnot in演算子といった、リストでできる操作をシーケンス型の値ではすべて行うことができます。
ミュータブルとイミュータブル
リストと文字列には大きな違いが一つあります。リスト値はミュータブルです。つまり、値の追加、削除、更新ができます。これに対し、文字列はイミュータブルで、変更できません。文字列に文字を再代入しようとしたら、TypeErrorエラーが発生します。以下の対話型シェルで確認してください。
>>> name = 'Zophie a cat'
>>> name[7] = 'the'
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
name[7] = 'the'
TypeError: 'str' object does not support item assignment
文字列を「変化」させる正しいやり方は、スライスと結合を用いて新しい文字列を組み立てるというやり方です。
>>> name = 'Zophie a cat'
>>> new_name = name[0:7] + 'the' + name[8:12]
>>> name
'Zophie a cat'
>>> new_name
'Zophie the cat'
[0:7]と[8:12]で変化させない文字を取得しています。元の'Zophie a cat'という文字列に手を加えていないことに注意してください。文字列はイミュータブルです。
リスト値はミュータブルで変更できるのですが、次のコードの2行目はリストeggsを変更していません。
>>> eggs = ['A', 'B', 'C']
>>> eggs = ['x', 'y', 'z']
>>> eggs
['x', 'y', 'z']
eggsの中に入っている値は変更されていません。そうではなく、全く新しい別のリスト値(['x', 'y', 'z'])が古いリスト値(['A', 'B', 'C'])に置き換わっています。
元のリストeggsの中に入っている値を['x', 'y', 'z']に変更する場合は、del文とappend()メソッドを使い、このように行います。
>>> eggs = ['A', 'B', 'C']
>>> del eggs[2]
>>> del eggs[1]
>>> del eggs[0]
>>> eggs.append('x')
>>> eggs.append('y')
>>> eggs.append('z')
>>> eggs
['x', 'y', 'z']
この例では、変数eggsが同じリスト値のままです。上書きされたのではなく変更されました。リストのその場での変更です。
ミュータブルとイミュータブルを区別することに意義が感じられないかもしれませんが、「参照」で関数の引数に取ったときの違いを説明します。 その前にイミュータブルなリストであるタプル型を紹介します。
タプル型
タプル型とリスト型には2つの違いしかありません。1つ目の違いは、タプルは角かっこではなく丸かっこで作成するという点です。対話型シェルで次のように入力してみてください。
>>> eggs = ('hello', 42, 0.5)
>>> eggs[0]
'hello'
>>> eggs[1:3]
(42, 0.5)
>>> len(eggs)
3
2つ目の違いは、リストはミュータブルであるのに対し、タプルは文字列と同じようにイミュータブルだという点です。値の変更、追加、削除はできません。 以下のコードを対話型シェルに入力すると、TypeErrorエラーが発生します。
>>> eggs = ('hello', 42, 0.5)
>>> eggs[1] = 99
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
eggs[1] = 99
TypeError: 'tuple' object does not support item assignment
要素を1つだけ持つタプルを作成する場合は、丸かっこ内の値のあとにカンマを入れてください。そうしないと、Pythonは値に丸かっこを付けたものだと解釈します(Pythonでは、他のプログラミング言語とは異なり、リストやタプルの最後の要素のあとにカンマを入れることができます)。type()関数を呼び出している、以下の対話型シェルの実行で確認してください。
>>> type(('hello',))
<class 'tuple'>
>>> type(('hello'))
<class 'str'>
タプルを使うと、そのシーケンス型では値の変更を意図していないことをコードの読み手に伝えられます。決して変更されないシーケンス型の値が必要な場合はタプルを使いましょう。リストではなくタプルを使えば、イミュータブルで変更されないために最適化されており、リストよりも少し速く実行できるという利点もあります。
リストとタプルの変換
str(42)が整数42の文字列表現である'42'を返すのと同じように、list()とtuple()はそれぞれ渡された値のリストとタプルを返します。以下のコードを対話型シェルに入力すると、返り値のデータ型が渡された値のデータ型と違っていることがわかります。
>>> tuple(['cat', 'dog', 5])
('cat', 'dog', 5)
>>> list(('cat', 'dog', 5))
['cat', 'dog', 5]
>>> list('hello')
['h', 'e', 'l', 'l', 'o']
タプルをミュータブルにしたければリストに変換します。
参照
変数は文字列や整数などの値を格納する箱にたとえられることがよくあります。しかし、この説明はPythonが実際に行っていることを単純化しています。値にくくりつけたネームタグというたとえのほうが適切です。以下の式を対話型シェルに入力してみてください。
❶ >>> spam = 42
❷ >>> eggs = spam
❸ >>> spam = 99
>>> spam
99
>>> eggs
42
変数spamに42を代入したときに、コンピュータのメモリに42という値を作成して、その参照を変数spamに格納しています。spamの値をコピーして変数eggsに代入したときには、その参照をコピーしています。変数spamとeggsの両方とも、コンピュータのメモリ内にある42という値を参照しています。ネームタグのたとえで言うと、同じ42 という値にspamというネームタグとeggsというネームタグを付けました。spamに新しく99という値を代入するとspamのネームタグの参照先が変わります。図6-2にその状況を示しました。
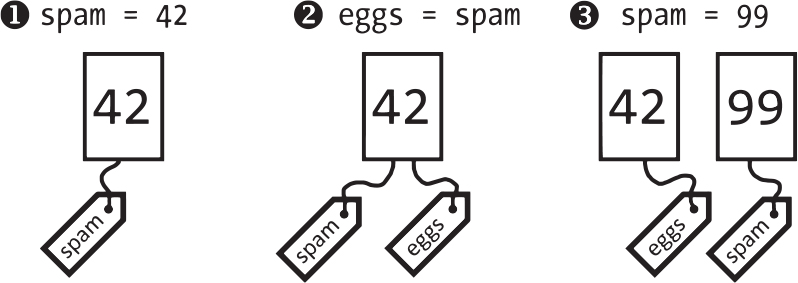
図 6-2:代入は値を書き換えず、参照を変えます
この変更はeggsに影響を与えません。依然として42 という値を参照しています。
しかし、リストはこのような動作にはなりません。リストはミュータブルで、その中に入っている値は変わることがあります。このことがわかる例を以下に示します。以下の内容を対話型シェルに入力してください。
❶ >>> spam = [0, 1, 2, 3]
❷ >>> eggs = spam # リスト自体ではなく参照がコピーされる
❸ >>> eggs[1] = 'Hello!' # リスト値の変更
>>> spam
[0, 'Hello!', 2, 3]
>>> eggs # 変数eggsは同じリストを参照している
[0, 'Hello!', 2, 3]
このコードの結果は奇妙に感じられるかもしれません。リストeggs にしか触れていないのにeggsとspamの両方のリストが変化しています。
リストを作ったときに(❶)、変数spamにそのリストへの参照を代入しました。次の行では、リストspamの中に入っている値ではなく、そのリストへの参照をeggsにコピーしました(❷)。リストは1つしかなく、spamとeggsの両方ともがそのリストを参照しています。背後に存在するリスト自体はコピーされていないので、リストは1つしかありません。ですので、eggsの最初の要素を変更したときに(❸)、spamが参照している同じリストの変更をしたことになります。図6-3にこの状況を示しました(訳注:下図では❶で「spam = 42」となっていますが、正しくは「spam = [0, 1, 2, 3]」です)。
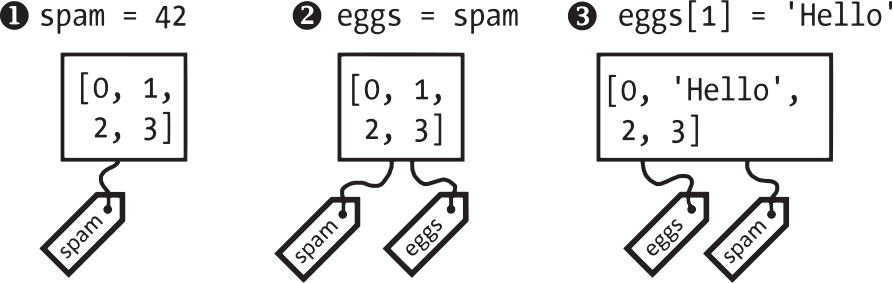
図 6-3:spamとeggsは同じリストを参照しているので、一方を変更すれば他方も変更されます
リストが直接一連の値を格納しているのではなく、一連の値の参照を格納しているので、事態はやや複雑です。「copy() 関数と deepcopy()関数」でさらに詳しく説明します。
技術的にPythonの変数は値の参照を格納しているのですが、変数が値を格納していると不用意に言ってしまうことがよくあります。次の2つのルールを覚えておいてください。
- Pythonでは、変数が値を格納することはなく、値への参照を格納します。
- Pythonでは、=代入演算子は参照をコピーするのであって、値をコピーするのではありません。
多くの場合、このような詳細を気にする必要はありませんが、時々驚かされることがあるので、Pythonの動作を正確に理解してください。
引数
引数がどのようにして関数に渡されるかを理解するのに、参照という概念は特に重要です。関数が呼び出されると、Pythonは引数への参照をパラメータ変数にコピーします。(第7章で説明する辞書や)リストのようなミュータブルな値であれば、関数内のコードが元の値をその場で変更することを意味します。この事実の帰結を確認するために、新しいファイルエディタウィンドウを開いて以下のコードをpassingReference.pyという名前で保存してください。
def eggs(some_parameter):
some_parameter.append('Hello')
spam = [1, 2, 3]
eggs(spam)
print(spam) # [1, 2, 3, 'Hello']を表示
eggs()を呼び出したときに、返り値にspamの新しい値を代入していないことに注意してください。そうではなく、直接リストをその場で変更しています。このプログラムを実行すると、[1, 2, 3, 'Hello']と表示します。
spamとsome_parameterは別々の参照ではありますが、同じリストを参照しています。そのため、関数呼び出しが終わっても、関数内でのappend('Hello')メソッドの呼び出しがリストに影響します。
この振る舞いを覚えておいてください。Pythonがリストや辞書をこのように扱うという事実を忘れると、予期せぬ振る舞いや混乱させられるようなバグにつながりかねません。
copy()関数とdeepcopy()関数
リストと辞書に関して参照を関数に渡すのが簡便ではありますが、渡されたリストや辞書が関数内で変更される場合に、その変更が元のリストや辞書に反映されてほしくないこともあるでしょう。この振る舞いに対処するために、Pythonにはcopy()関数とdeepcopy()関数を提供するcopyモジュールがあります。前者のcopy.copy()はリストや辞書のようなミュータブルな値のコピーを作成します。参照のコピーではありません。以下の式を対話型シェルに入力してみてください。
>>> import copy
>>> spam = ['A', 'B', 'C']
>>> cheese = copy.copy(spam) # リスト自体の複製を作成する
>>> cheese[1] = 42 # cheeseを変更
>>> spam # 変数spamは変更されていない
['A', 'B', 'C']
>>> cheese # 変数cheeseは変更されている
['A', 42, 'C']
変数spamとcheeseは別々のリストを参照しています。よって、cheeseのインデックス1に42を代入しても、その変数の中にある値しか変更されません。
変数が値を格納するのではなく値を参照するのと同じように、リストは値そのものではなく値への参照を保持します。図6-4をご覧ください。
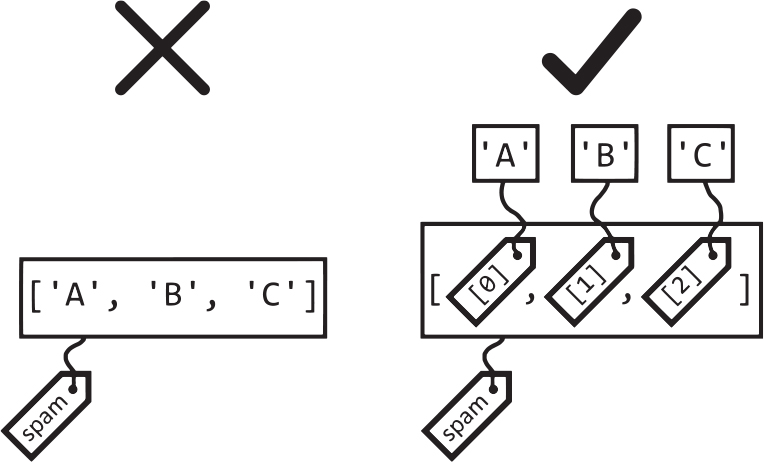
図 6-4:リストは値を直接保持するのではなく(左側)、値への参照を保持します(右側)
コピーしたいリストがその中にリストを保持しているときは(入れ子のリストになっているときは)、copy.copy()ではなくcopy.deepcopy()を使ってください。copy.deepcopy()関数は内側のリストもコピーします。
短いプログラム:マトリックスのスクリーンセーバー
ハッカーSF映画マトリックスの中で、コンピュータのモニターが光り輝く緑色の数字の羅列を表示する場面があります。ガラス窓をたたくデジタルの雨のように見えます。数字に意味はないのでしょうけれども、かっこいいです。趣味的に、Pythonで自前のマトリックススクリーンセイバーを作れます。以下のコードをmatrixscreensaver.pyという名前で保存してください。
import random, sys, time
WIDTH = 70 # 列数
try:
# 各列につき、カウンターが0なら数字の羅列は表示しない
# カウンターが0ではない場合は、
# その列に0または1を表示する回数になる
columns = [0] * WIDTH
while True:
# 各列をループ
for i in range(WIDTH):
if random.random() < 0.02:
# この列のカウンターを設定
# 数字の羅列は4から14の長さ
columns[i] = random.randint(4, 14)
# この列の出力
if columns[i] == 0:
# 空白部分を確認するには''を'.'に変更
print(' ', end='')
else:
# 0または1を出力
print(random.choice([0, 1]), end='')
columns[i] -= 1 # この列のカウンターを減らす
print() # 1行分の出力が終わったら改行
time.sleep(0.1) # 各行で0.1秒停止
except KeyboardInterrupt:
sys.exit() # Ctrl-Cが押されたら終了
このプログラムを実行すると、図6-5のように、1と0のバイナリの羅列が表示されます。
図 6-5:マトリックススクリーンセイバープログラム
前の章のグラフのスパイクやジグザグのプログラムと同様に、このプログラムは、CTRL-Cを押すと止められる無限ループ内でテキストを表示することにより、スクロールアニメーションを実現しています。このプログラムの主なデータ構造は、リストcolumnsです。出力の各列に対応する70個の整数を保持しています。columnsの中に入っている整数が0ならその列にスペースを表示します。整数が0より大きければ、ランダムに0または1を表示し、その整数を減らします。その整数が0に達したら、またその列にスペースを表示します。このプログラムでは、columnsの中に入っている整数に4から14の整数を設定します。これがバイナリの0と1の羅列を生み出します。
プログラムの各部を見ていきましょう。
import random, sys, time
WIDTH = 70 # 列数
choice()関数とrandint()関数を使うためにrandomモジュールを、exit()関数を使うためにsysモジュールを、sleep()関数を使うためにtimeモジュールをインポートしています。70列の出力にするために、WIDTHという名前の変数に70を設定しています。プログラムを実行するウィンドウサイズに応じて、この値を適当に変えてください。
変数WIDTHは、定数であることを示すために、すべて大文字の名前にしています。定数とは一度設定された後に変更されない変数のことです。定数を使うとコードが読みやすくなります。columns = [0] * 70と書くとコードをあとで読み返したときに70は何だろうと疑問に思うかもしれませんが、columns = [0] * WIDTHと書くとわかりやすいです。Pythonでは、定数の値を変更することができますが、すべて大文字の名前にしておくと、定数なので変更してはいけないと思い出しやすくなります。
大部分のプログラムはtryブロック内にあります。ユーザーがCTRL-Cを押すと送出されるKeyboardInterruptエラーを捕捉します。
try:
# 各列につき、カウンターが0なら数字の羅列は表示しない
# カウンターが0ではない場合は、
# その列に0または1を表示する回数になる
columns = [0] * WIDTH
変数columnsは整数0をWIDTH個含むリストです。それぞれの整数が、その列に0または1を出力するかしないかを決めます。
while True:
# 各列をループ
for i in range(WIDTH):
if random.random() < 0.02:
# この列のカウンターを設定
# 数字の羅列は4から14の長さ
columns[i] = random.randint(4, 14)
このプログラムを永遠に実行したいので、while True:の無限ループの中にコードを書きます。このループ内には、各列を繰り返し処理するforループがあります。ループ変数iは列のインデックスを表しています。0からWIDTHまでです(WIDTHは含まない)。columns[0]の値は左端の列で、columns[1]は左から2番目の列で…と続きます。
列ごとに、2パーセントの確率でcolumns[i]に4から14までの整数が設定されます。0.0から1.0までの浮動小数点数を返す関数であるrandom.random()の値と0.02を比べることにより、2パーセントの確率にしています。0と1の羅列の密度を増やしたり減らしたりしたい場合は、この値を増やしたり減らしたりしてください。ここでは各列の整数を4から14までのランダムな整数にします。
# この列の出力
if columns[i] == 0:
# 空白部分を確認するには''を'.'に変更
print(' ', end='')
else:
# 0または1を出力
print(random.choice([0, 1]), end='')
columns[i] -= 1 # この列のカウンターを減らす
forループの内側には、0または1の数字を表示するかスペースを表示するかを決めるプログラムもあります。columns[i]が0なら、スペースを表示します。それ以外の場合は、random.choice()関数にリスト[0, 1]を渡し、そのリストからランダムに値を選んで表示します。そして、columns[i]の整数値を減らし、スペースを表示することになる0に近づけます。
プログラムが表示するスペースを可視化したければ、' 'を'.'に変えてプログラムをもう一度実行してみたください。出力は次のようになります。
............................1.........................................
................0...........1......................1..................
................1...........0................1.....0..................
............1...0...........0.....0..........1.....0..................
............1.1.1...........0.....0..........1.....1..1...............
............0.0.0...........0.....1.........00.....1..1...............
elseブロックが終わると、forループブロックが終わります。
print() # 1行分の出力が終わったら改行
time.sleep(0.1) # 各行で0.1秒停止
except KeyboardInterrupt:
sys.exit() # Ctrl-Cが押されたら終了
forループが終わったら、print()を呼び出して改行を出力しています。それまでの各列についてのprint()の呼び出しはend=''キーワード引数を渡していたので改行を出力しませんでした。行が表示されるごとに、time.sleep(0.1)を呼び出して0.1秒停止します。
プログラムの最後の部分はexceptブロックです。ユーザーがCTRL-Cを押してKeyboardInterrupt例外が送出されると、プログラムは終了します。
まとめ
リストを使うと、処理する値の個数が変わっても同じ一つの変数で扱えるので便利です。本書の後半では、リストを使わなければ不可能に近い作業を行います。
リストはシーケンス型のミュータブルなデータです。リストの中に入っている値を変更できます。タプルと文字列は、同じくシーケンス型のデータですが、イミュータブルで値を変更できません。タプルや文字列を格納している変数そのものを新しいタプルや文字列で上書きすることはできますが、それはappend()メソッドやremove()メソッドがリストについて行うようにその場で既存の値を変更することとは異なります。
変数はリストの値を直接格納しているのではなく、リストへの参照を格納しています。リスト変数をコピーしたり関数呼び出しの引数として渡したりするときに、この点が重要になります。コピーされる値はリストへの参照ですので、そのリストに加えた変更は別の変数にも影響することに注意してください。copy()ないしdeepcopy()を使うと、コピー先の変数に格納されている値を変更してもコピー元のリストに影響しません。
練習問題
1. []は何ですか?
2. spamという名前の変数に格納されているリストの3番目の要素に'hello'という値を代入してください(spamは[2, 4, 6, 8, 10]のリストを格納しているとします)。
以下3問は、spamがリスト['a', 'b', 'c', 'd']を格納していることを前提に答えてください。
3. spam[int(int('3' * 2) // 11)]はどう評価されますか?
4. spam[-1]はどう評価されますか?
5. spam[:2]はどう評価されますか?
以下3問は、baconがリスト[3.14, 'cat', 11, 'cat', True]を格納していることを前提に答えてください。
6. bacon.index('cat')はどう評価されますか?
7. bacon.append(99)を実行すると、baconの中に入っている値はどうなりますか?
8. bacon.remove('cat')を実行するとbaconの中に入っている値はどうなりますか?
9. リストを結合する演算子と繰り返す演算子をそれぞれ答えてください。
10. リストメソッドのappend()とinsert()はどう違いますか?
11. リストから値を削除する方法を2つ挙げてください。
12. リストが文字列と似ている点を挙げてください。
13. リストとタプルの違いは何ですか?
14. 42という整数値を一つだけ持つタプルを作成してください。
15. リストからタプルを作成してください。また、タプルからリストを作成してください。
16. リスト値を格納している変数は実際にはリストを直接格納しているわけではありません。実際には何を格納していますか?
17. copy.copy()とcopy.deepcopy()の違いを答えてください。
練習プログラム
以下の練習プログラムを書いてください。
カンマコード
次のようなリスト値があるとします。
spam = ['apples', 'bananas', 'tofu', 'cats']リスト値を引数に取り、すべての要素をカンマで区切って、最後の区切りにはandを加える関数を作成してください。例えば、上記のspamリストをその関数に渡すと'apples, bananas, tofu, and cats'が返されます。このリストに限らず、どのリストを渡しても動作する関数を書いてください。空リスト[]を渡した場合も考慮してください。
連続コイン投げ
連続したコイン投げの実験をします。100回コインを投げて、表が出たらHを、裏が出たらT を記入します。T T T T H H H H T Tのような結果を得ます。100回のランダムなコイン投げの結果を書いてくださいと人間に頼むと、H T H T H H T H T Tのような表と裏の入れ替わりの多い結果を書きがちです。これは(人間にとっては)ランダムに見えますが、数学的にはランダムではありません。人間は6連続の表または裏をめったに書きませんが、本当にランダムなコイン投げだとそれが十分に起こり得ます。人間はランダムが苦手です。
ランダムに生成された100回分の表または裏の結果について、6連続の表または裏がどれくらいの頻度で出現するかを確かめるプログラムを書いてください。プログラムは2つの部分に分けられます。100個のランダムに選んだ'H'または'T'の値のリストを生成する部分と、6連続の表または裏があるかどうかを確かめる部分です。実験を10,000回行うループの中にその2つの部分のコードを入れてください。そうすれば、どれくらいのパーセンテージで6連続の表または裏を含むかを算出できます。ヒントとして、random.randint(0, 1)関数を呼び出すと、半々の確率で0または1を返します。
以下のテンプレートをご活用ください。
import random
number_of_streaks = 0
for experiment_number in range(10000): # 合計10,000回の実験を実行
# 100個の表または裏の値のリストを作成するコード
# 6連続の表または裏があるかどうかをチェックするコード
print('Chance of streak: %s%%' % (number_of_streaks / 100))
もちろん、これは推計に過ぎませんが、10,000回実験すればサンプルサイズとしては十分でしょう。数学の知識があればプログラムを書かずに正確な答えを出せるかもしれません(プログラマには数学が得意ではない人が多いです)。
forループでランダムに選んだ'H'または'T'を100回リストに追加してください。6連続の表または裏があるかどうかを判定するには、some_list[i:i + 6]のようなスライス(インデックスiから始まる6つの要素を含むリスト)を作成し、['H', 'H', 'H', 'H', 'H', 'H']または['T', 'T', 'T', 'T', 'T', 'T']と比較します。