17 PDFとWord文書

PDFとWordはテキストを保存する形式だと思われるかもしれませんが、フォントや色やレイアウトの情報を含むバイナリファイルです。そのため、単純なプレーンテキストファイルよりもずっと複雑です。ファイル名をopen()に渡すだけでは、プログラムからPDFやWordの読み書きはできません。幸い、PDFやWordの読み書きを簡単にしてくれるPythonのパッケージが存在します。本章では、そのようなパッケージのうち、PyPDFとPython-Docxを紹介します。
PDF文書
PDFはPortable Document Format(持ち運び可能な文書フォーマット)を表しファイル拡張子は.pdfです。PDFにはたくさんの機能がありますが、この節では、テキストの抽出、画像の抽出、既存のPDFファイルから新しいPDFファイル作成の、3つのよくある作業に絞ります。
PyPDFはPDFファイルの作成と変更を行うためのPythonパッケージです。付録Aの指示に従ってインストールしてください。パッケージが正しくインストールされたら、対話型シェルでimport pypdfを実行したときにエラーは表示されません。
PDFファイルは印刷用や閲覧用にテキストをレイアウトするのに適していますが、プレーンテキストへと解析するのは簡単ではありません。そのため、PyPDFはPDFからテキストを抽出する際に間違えることがありますし、PDFを開くことさえできない場合もあります。こうなるとどうしようもありません。PyPDFは一部のファイルについては機能しません。とは言うものの、個人的にはPyPDFが開けないPDFファイルに遭遇したことはないです。
テキストの抽出
PyPDFで作業を行うのに、再帰的アルゴリズムについての私の本The Recursive Book of Recursion (No Starch Press, 2022)から抜粋したサンプルのPDF(図17-1)を使ってください。

図 17-1:テキストを抽出するサンプルのPDFファイル
このRecursion_Chapter1.pdfファイルをhttps://
>>> import pypdf
❶ >>> reader = pypdf.PdfReader('Recursion_Chapter1.pdf')
❷ >>> len(reader.pages)
18
pypdfモジュールをインポートしてから、PDFのファイル名を渡してpypdf.PdfReader()を呼び出し、PDFを表すPdfReaderオブジェクトを取得します(❶)。このオブジェクトをreaderという名前の変数に保存します。
PdfReaderオブジェクトのpages属性は、PDFの個々のページを表すPageオブジェクトのリストのようなデータ構造をしています。Pythonのリストと同じように、このデータ構造をlen()関数に渡せます(❷)。このサンプルのPDFは18ページです。
このPDFからテキストを抽出してテキストファイルに出力するには、新しいファイルエディタタブを開いて以下のコードをextractpdftext.pyという名前で保存してください。
import pypdf
import pdfminer.high_level
PDF_FILENAME = 'Recursion_Chapter1.pdf'
TEXT_FILENAME = 'recursion.txt'
text = ''
try:
reader = pypdf.PdfReader(PDF_FILENAME)
❶ for page in reader.pages:
❷ text += page.extract_text()
except Exception:
❸ text = pdfminer.high_level.extract_text(PDF_FILENAME)
with open(TEXT_FILENAME, 'w', encoding='utf-8') as file_obj:
❹ file_obj.write(text)
テキストの抽出にpypdfモジュールを使いますが、そのモジュールでうまくいかないPDFファイルについては例外を送出し、pdfminerモジュールに委ねます。tryブロック内では、forループ(❶)でPDFファイルのPdfReaderオブジェクトのPageオブジェクトを反復処理します。Pageオブジェクトのextract_text()メソッドを呼び出すと文字列が返されるので、それを変数textに結合します(❷)。ループが終われば、textにはPDFの全テキストが一つの文字列として含まれます。
PDFファイルが一般的なフォーマットではなくPyPDFで読み取れなければ、pdfminer.high_levelという、本書のサードパーティーパッケージに含まれている古いモジュールを使います。このモジュールのextract_text()関数は、ページごとに処理するのではなく、PDFの内容を一つの文字列として取得します(❸)。
最後に、第10章で紹介したopen()関数とwrite()メソッドでその文字列をテキストファイルに書き込みます(❹)。
AIによる後処理
先ほど行ったテキスト抽出は完璧ではありません。PDFファイルのフォーマットは複雑であり、印刷のために設計されたものであって、機械が読めるようには設計されていません。抽出に問題がなかったとしても、テキストのレイアウトが固定されています。テキストの各行末には改行記号が含まれますし、単語が行をまたぐときのハイフンが残ります。例えば、先ほどのサンプルのPDFから抽出したテキストは、以下のとおりです。
1
WHAT IS RECURSION?
Recursion has an intimidating reputation.
It's considered hard to understand, but
at its core, it depends on only two things:
function calls and stack data structures.
Most new programmers trace through what a program does by follow -
ing the execution. It's an easy way to read code: you just put your finger
--snip--
ご覧のとおり、主観的に判断して処理しなければならない箇所がたくさんあります。
- PDFの段落はどこで始まりどこで終わるか
- ページ番号、ヘッダー、フッターを抽出したテキストに含めるかどうか
- PDFのデータ表をどのようにテキスト化するか
- 抽出したテキストにスペースをどれだけ入れるか
このテキストを整形するのは退屈な作業ですが、コードで簡単に自動化することはできません。しかし、ChatGPTなどの大規模言語モデル(LLM)のAIは、テキストの文脈を理解し、自動的に整形してくれます。抽出したテキストについて以下のプロンプトを使ってください。
以下のテキストは、再帰的アルゴリズムについての本のPDFを数ページ抽出したものです。このテキストを整形してください。段落を一行でまとめ、各ページのヘッダーとフッターを除去してください。また、単語が行をまたぐときにつけられたハイフンを取り除いてください。スペルや文法の修正はせず、言い換えをしないでください。テキストは以下です。
このプロンプトを試してみると、整形されて以下のテキストになりました。
WHAT IS RECURSION?
Recursion has an intimidating reputation. It's considered hard
to understand, but at its core, it depends on only two things:
function calls and stack data structures. Most new programmers
trace through what a program does by following the execution.
It's an easy way to read code: you just put your finger...
AIを使うときは必ず人間が出力をレビューしてください。例えば、LLMはテキストの冒頭の章番号の1を消してしまいました。これは私の意図に反しています。意図が誤解されないようにプロンプトを洗練させる余地があると思います。
LLMを利用できなければ、コード例つきで後処理のコツを示したPyPDFのドキュメント(https://
画像の抽出
PyPDFではPDF文書から画像を抽出することもできます。各Pageオブジェクトにはimages属性があり、そこにImageオブジェクトがリストのようなデータ構造で含まれています。そのImageオブジェクトのバイトを'wb'(バイナリ書き込み)モードで開いた画像ファイルに書き込めます。Imageオブジェクトにはname属性があり、画像の名前の文字列が入っています。以下はサンプルのPDFのすべてのページから画像を抽出するコードです。新しいファイルエディタタブを開いてextractpdfimages.pyという名前でコードを保存してください。
import pypdf
PDF_FILENAME = 'Recursion_Chapter1.pdf'
reader = pypdf.PdfReader(PDF_FILENAME)
❶ image_num = 0
❷ for i, page in enumerate(reader.pages):
print(f'Reading page {i+1} - {len(page.images)} images found...')
try:
❸ for image in page.images:
❹ with open(f'{image_num}_page{i+1}_{image.name}', 'wb') as file:
❺ file.write(image.data)
print(f'Wrote {image_num}_page{i+1}_{image.name}...')
❻ image_num += 1
except Exception as exc:
❼ print(f'Skipped page {i+1} due to error: {exc}')
このプログラムの出力は次のようになります。
Reading page 1 - 7 images found...
Wrote 0_page1_Im0.jpg...
Wrote 1_page1_Im1.png...
--snip--
Reading page 7 - 1 images found...
Skipped page 7 due to error: not enough image data
--snip--
Reading page 17 - 0 images found...
Reading page 18 - 0 images found...
PDF文書の画像には、Im0.jpg、Im1.pngといった一般的な名前がつけられます。image_numという名前のカウンター変数(❶)とページ番号を名前に付加して一意の名前にします。まず、PdfReaderオブジェクトのpages属性のPageオブジェクトを反復処理します。Pythonのenumerate()関数(❷)は整数のインデックスとリスト的なオブジェクトの要素を返すことを思い出してください。各Pageオブジェクトにはimagesオブジェクトがあり、これも反復処理します(❸)。
images属性のImageオブジェクトを反復処理する、入れ子の内側のforループでは、open()を呼び出してf文字列でファイル名を指定しています(❹)。このファイル名は、image_numカウンターの整数、ページ番号、Imageオブジェクトのname属性の文字列の3つから構成されています。PDFのページ番号は1から始まりますがiは0から始まるので、i+1でページ番号にしています。この名前は.pngや.jpgのファイル拡張子を含んでいます。open()関数に'wb'を渡してバイナリ書き込みモードで開きます。画像ファイルのバイトはImageオブジェクトのdata属性に格納されているので、これをwrite()メソッドに渡します(❺)。画像の書き込み後はimage_numを1増やします(❻)。
PDFファイルとPyPDFとの間に互換性がなければ、Pageオブジェクトのimages属性は例外を送出します。try文とexcept文でその例外を捕捉し、短いエラーメッセージを表示します(❼)。このようにして、あるページで問題が発生してもプログラム全体がクラッシュしないようにしています。
テキスト抽出と同様に、画像抽出も不完全です。例えば、PyPDFはサンプルのPDFファイルの画像をすべて検知できておらず、エラーメッセージが表示されます。他方で、意外なことに、PyPDFが背景やスペースの小さな空白の画像を抽出しています。PDFに関する作業を行う際は、出力が正しいかどうか人間が確認しなければなりません。
他のページからのPDFの作成
PyPDFにはPdfReaderと対になるPdfWriterがあり、これを使って新しいPDFファイルを作成できます。しかし、PyPDFでは、Pythonが任意のテキストをプレーンテキストに書き込めるようにテキストを自由にPDFに書き込むことはできません。PyPDFのPDF書き込み機能は、他のPDFファイルを利用した、コピー、挿入、除去、変形に限られています。以下の対話型シェルのコードを実行すると、サンプルのPDFの最初の5ページだけがコピーされた新しいPDFファイルが作成されます。
>>> import pypdf
❶ >>> writer = pypdf.PdfWriter()
❷ >>> writer.append('Recursion_Chapter1.pdf', (0, 5))
>>> with open('first_five_pages.pdf', 'wb') as file:
❸ ... writer.write(file)
...
(False, <_io.BufferedWriter name='first_five_pages.pdf'>)
まず、pypdf.PdfWriter()を呼び出してPdfWriterオブジェクトを作成します(❶)。writer変数に格納されたPdfWriterオブジェクトは0ページの空白のPDFを表します。次に、PdfWriterオブジェクトのappend()メソッドで'Recursion_Chapter1.pdf'というファイル名を指定し、サンプルのPDFの最初の5ページをコピーします(❷)。(同名ではありますがPdfWriterオブジェクトのappend()メソッドはリストメソッドのappend()とは異なります。)
このメソッドの第二引数はタプル(0, 5)です。PdfWriterオブジェクトにインデックス0のページ(PdfWriterオブジェクトの最初のページ)からインデックス5のページまで(インデックス5のページは含まない)をコピーすることを伝えます。PDFアプリケーションでは最初のページを1ページと表示しますが、PyPDFは0で最初のページを表します。
最後に、ファイル名と'wb'モードを指定してopen()を呼び出し、Fileオブジェクトのwrite()メソッドにそのPdfWriterオブジェクトを渡して、PdfWriterオブジェクトの内容をPDFに書き込みます(❸)。これで新しいPDFファイルが作成されます。
append()に渡すタプルには2つまたは3つの整数が含まれます。3つの整数が含まれる場合は、3番目の数値がステップ数を表します。これはrange()関数と同じですから、list(range())に2つまたは3つの整数を渡すことで、どのページがコピーされるかわかります。
>>> list(range(0, 5)) # (0, 5)を渡すとappend()はこのページをコピーする
[0, 1, 2, 3, 4]
>>> list(range(0, 5, 2)) # (0, 5, 2)を渡すとappend()はこのページをコピーする
[0, 2, 4]
append()メソッドはコピーするページ番号の整数のリストを取ることもできます。例えば、先ほどの対話型シェルの例を、次のように書くことができます。
>>> writer.append('Recursion_Chapter1.pdf', [0, 1, 2, 3, 4])このコードもPDF文書の最初の5ページをPdfWriterオブジェクトにコピーします。append()は引数のタプルとリストを異なるように解釈することに注意してください。タプル(0, 5)はインデックス0からインデックス5まで(インデックス5は含まない)をコピーするのに対し、リスト[0, 5]はインデックス0とインデックス5のページをコピーします。タプルとリストでこのような意味の違いを持たせるのは慣習的ではなく、他のPythonのライブラリで目にすることはないでしょうが、PyPDFではそのように設計されています。
append()メソッドはコピーしたページをPdfWriterオブジェクトの末尾に追加します。コピーしたページを末尾以外に挿入したい場合は、merge()メソッドを呼び出します。merge()メソッドは、挿入するページを指定するもう一つ引数を取ります。例えば、次のようにします。
>>> writer.merge(2, 'Recursion_Chapter1.pdf', (0, 5))このコードはインデックス0からインデックス5(インデックス5は含まない)をコピーし、writer変数に格納されたPdfWriterオブジェクトのインデックス2のページ(3ページ目)に挿入します。元のインデックス2のページ以降は、コピーされたページのあとに繰り下がります。
ページの回転
Pageオブジェクトのrotate()メソッドで、PDFのページを90度ずつ回転させることもできます。時計回りに回転させるなら90、180、270を、反時計回りに回転させるなら-90、-180、-270を、このメソッドの引数に渡します。たくさんのPDFがあり、理由はともかく向きが正しくないので回転させたいとしたら、このページの回転が役に立ちます。PDF文書の一部のページだけを回転させることもできます。PDFアプリにも回転機能があり、手動でPDFの向きを正しくすることができますが、PythonだとたくさんのPDFを回転させて面倒な作業を自動化できます。
例えば、対話型シェルに以下の内容を入力して、サンプルのPDFを回転させてみてください。
>>> import pypdf
>>> writer = pypdf.PdfWriter()
>>> writer.append('Recursion_Chapter1.pdf')
❶ >>> for i in range(len(writer.pages)):
... ❷ writer.pages[i].rotate(90)
...
{'/ArtBox': [21, 21, 525, 687], '/BleedBox': [12, 12, 534, 696],
--snip--
>>> with open('rotated.pdf', 'wb') as file:
... writer.write(file)
...
(False, <_io.BufferedWriter name='rotated.pdf'>)
新しいPdfWriterオブジェクトを作成して、サンプルのPDFのページをコピーします。それから、forループで各ページを反復処理します。len(writer.pages)を呼び出すとページ数が整数で返されます(❶)。式writer.pages[i]でforループの反復ごとにPageオブジェクトにアクセスし、rotate(90)メソッド呼び出しによりPdfWriterオブジェクトの当該ページを回転させます(❷)。
結果として出力されるPDFは、図17-2に示すように、すべてのページが時計回りに90度回転しています。

図 17-2:ページを時計回りに90度回転させたrotated.pdfファイル
PyPDFは90度の整数倍でしか回転させられません。
空白ページの挿入
insert _blank_page()メソッドとadd_blank_page()メソッドで、PdfWriterオブジェクトに空白ページを挿入したり追加したりできます。新しいページの大きさは前のページの大きさと同じになります。例えば、サンプルのPDFのコピーを作成して、末尾と3ページのあとに空白ページを挿入してみましょう。
>>> import pypdf
>>> writer = pypdf.PdfWriter()
>>> writer.append('Recursion_Chapter1.pdf')
❶ >>> writer.add_blank_page()
{'/Type': '/Page', '/Resources': {}, '/MediaBox': [0.0, 0.0,
546, 708], '/Parent': IndirectObject(1, 0, 2629126028624)}
❷ >>> writer.insert_blank_page(index=2)
{'/Type': '/Page', '/Parent': NullObject, '/Resources': {},
'/MediaBox': RectangleObject([0.0, 0.0, 546, 708])}
>>> with open('with_blanks.pdf', 'wb') as file:
... writer.write(file) # writerオブジェクトをPDFファイルに保存
...
(False, <_io.BufferedWriter name='with_blanks.pdf'>)
サンプルのPDFからすべてのページをPdfWriterオブジェクトにコピーしてから、add_blank_page()メソッドで空白ページを末尾に追加します。insert_blank_page()メソッドでインデックス2のページのあと(インデックスは0から始まるので3ページ目のあと)に空白ページを挿入します。このメソッドではindex名前付きパラメータを指定します。
このページを空白のままにしておくこともできれば、次の節で説明するように、あとで重ね合わせたり透かしを入れたりすることもできます。
透かしと重ね合わせ
PyPDFでは、あるページを別のページに重ね合わせることができます。ページにロゴやタイムスタンプや透かしを入れたりするのに便利です。スタンプやオーバーレイはページの既存の内容の上に重ね、透かしやアンダーレイはページの既存の内容の下に重ねます。
本書のオンライン素材からwatermark.pdfをダウンロードして、サンプルのPDFと同じ現在の作業ディレクトリの中に入れてください。そして、対話型シェルに次のように入力します。
>>> import pypdf
>>> writer = pypdf.PdfWriter()
>>> writer.append('Recursion_Chapter1.pdf')
❶ >>> watermark_page = pypdf.PdfReader('watermark.pdf').pages[0]
>>> for page in writer.pages:
❷ ... page.merge_page(watermark_page, over=False)
...
>>> with open('with_watermark.pdf', 'wb') as file:
... writer.write(file)
...
(False, <_io.BufferedWriter name='with_watermark.pdf'>)
この例では、新しいPdfWriterオブジェクトにサンプルのPDFのコピーを作成し、変数writerに格納します。透かしのPDFの最初のページのPageオブジェクトも取得し、変数watermark_pageに格納します。forループでPdfWriterオブジェクトのPageオブジェクトを反復処理し、merge_page()で透かしを入れます。(Pageオブジェクトのmerge_page()メソッドを、本章の最初のほうで紹介したPdfWriterオブジェクトのmerge()メソッドと混同しないようにしてください。)
merge_page()メソッドにはoverキーワード引数があります。この引数にTrueを渡すとスタンプ(オーバーレイ)になり、Falseを渡すと透かし(アンダーレイ)になります。
ループでPdfWriterオブジェクトのページを処理してから、with_watermark.pdfという名前で保存しています。図17-3は元の透かしのPDFと、透かしを入れたサンプルのPDFから2ページを示しています。

図 17-3:透かしのPDF(左側)と透かしを入れたページ(中央と右側)
2つのページを重ね合わせるなど、PDFに大きな変更を加えたいときにmerge_page()メソッドが役立ちます。
PDFの暗号化と復号
PDFは内容を暗号化して読めなくできます。暗号化はパスワードにより強度が変わりますから、いろいろな記号を使って辞書に載っていない14から16文字くらいのパスワードを設定します。PDFにはパスワードリセット機能がありませんから、パスワードを失念するとパスワードを当てられない限り永久に読めなくなることに注意してください。
PdfWriterオブジェクトのencrypt()メソッドは、パスワード文字列と暗号化アルゴリズムの2つを引数に取ります。'AES-256'が推奨される新しい暗号化アルゴリズムなので、ここではそれを使います。対話型シェルに以下の内容を入力し、サンプルのPDFの暗号化されたコピーを作成してください。
>>> import pypdf
>>> writer = pypdf.PdfWriter()
>>> writer.append('Recursion_Chapter1.pdf')
>>> writer.encrypt('swordfish', algorithm='AES-256')
>>> with open('encrypted.pdf', 'wb') as file:
... writer.write(file)
...
(False, <_io.BufferedWriter name='encrypted.pdf'>)
PdfWriterオブジェクトについてencrypt('swordfish', algorithm='AES-256')メソッドを呼び出すことで、そのPDFの内容を暗号化しています。この暗号化されたPDFをencrypted.pdfファイルに書き出したら、PyPDFを含めてどのようなPDFアプリでもパスワードのswordfishを入力しない限りそのファイルを開くことができません。(これは辞書に載っている語なのでまずいパスワードで、簡単に推測できます。)暗号化されたデータは、正しいパスワードで復号しなければランダムに見えます。正しくないパスワードで復号してもデータは使い物にならず、PDFアプリはパスワードをもう一度入力するように要求します。
PyPDFは暗号化されたPDFをパスワードで復号できます。対話型シェルに以下の内容を入力して、is_encrypted属性でそのPDFが暗号化されているかどうかを判定し、decrypt()で復号します。
>>> import pypdf
❶ >>> reader = pypdf.PdfReader('encrypted.pdf')
>>> writer = pypdf.PdfWriter()
❷ >>> reader.is_encrypted
True
❸ >>> reader.pages[0]
Traceback (most recent call last):
--snip--
pypdf.errors.FileNotDecryptedError: File has not been decrypted
❹ >>> reader.decrypt('an incorrect password').name
'NOT_DECRYPTED'
❺ >>> reader.decrypt('swordfish').name
'OWNER_PASSWORD'
❻ >>> writer.append(reader)
>>> with open('decrypted.pdf', 'wb') as file:
... writer.write(file)
...
(False, <_io.BufferedWriter name='decrypted.pdf'>)
これまでのPDFと同じように、暗号化されたPDFをPdfReaderオブジェクトにロードしています(❶)。PdfReaderオブジェクトにはis_encrypted属性があり、TrueまたはFalseが設定されています(❷)。pages属性にアクセスするなどしてPDFの内容を読み取ろうとすると(❸)、PyPDFは読み取ることができないのでFileNotDecryptedErrorを送出します。
PDFには、閲覧専用のユーザーパスワードと、印刷やコメントやテキスト抽出やその他の機能を使えるオーナーパスワードがあります。encrypt()の第一引数がユーザーパスワードに、第二引数がオーナーパスワードに対応します。encrypt()に一つしか引数を渡さなければ、PyPDFはユーザーパスワードとオーナーパスワードに同じそのパスワードを設定します。
PdfReaderオブジェクトを復号するには、decrypt()メソッドを呼び出してパスワード文字列を渡します。PasswordTypeメソッドを呼び出してパスワード文字列を渡します。そのオブジェクトのname属性が'NOT_DECRYPTED'であれば(❹)、パスワードが間違っています。name属性が'OWNER_PASSWORD'または'USER_PASSWORD'であれば、(❺)、正しいユーザーパスワードまたはオーナーパスワードです。
PdfWriterオブジェクトにPdfReaderオブジェクトのページを追加できるようになりました(❻)。復号したPDFをファイルに保存します。
プロジェクト12:たくさんのPDFから選択したページを結合する
数十のPDFファイルを一つのPDFファイルに結合する退屈な作業をしているとしましょう。各PDFの最初のページは表紙であり、最終成果物では表紙が不要です。PDFを結合する無料のプログラムはたくさんありますが、ファイル全体を結合することしかできないプログラムが多いです。結合したPDFに含めるページを調節できるPythonプログラムを書きましょう。
このプログラムには以下の内容が必要です。
- 現在の作業ディレクトリにあるPDFファイルをすべて見つけてアルファベット順に並べ替える
- 各PDFファイルについて、2ページ目以降を出力PDFにコピーする
- 出力PDFをファイルに保存する
コードには以下の内容が必要になります。
- os.listdir()を呼び出して現在の作業ディレクトリのすべてのファイルを見つけ、PDF以外のファイルを除去する(第11章でこの関数を扱いました)
- Pythonのsort()リストメソッドを呼び出してファイル名のアルファベット順に並べ替える
- 出力PDF用のPdfWriterオブジェクトを作成する
- 各PDFファイルを反復処理してPdfReaderオブジェクトを作成する
- PdfReaderオブジェクトから2ページ目以降を出力PDFにコピーする
- 出力PDFをファイルに書き出す
このプロジェクト用に新しいファイルエディタタブを開いてcombine_pdfs.pyという名前で保存してください。
ステップ1:すべてのPDFファイルを見つける
まず、現在の作業ディレクトリで.pdf拡張子のファイルをすべて見つけて並べ替えます。コードは次のようになります。
# combine_pdfs.py - 現在の作業ディレクトリにあるすべてのPDFファイルを
# 一つのPDFファイルに結合する
❶ import pypdf, os
# すべてのPDFファイル名を取得
pdf_filenames = []
for filename in os.listdir('.'):
if filename.endswith('.pdf'):
❷ pdf_files.append(filename)
❸ pdf_filenames.sort(key=str.lower)
❹ writer = pypdf.PdfWriter()
# TODO:すべてのPDFファイルを反復処理
# TODO: 2ページ目以降のすべてのページをコピー
# TODO:出力PDFをファイルに保存
このコードでは、pypdfモジュールとosモジュールをインポートしています(❶)。os.listdir('.')を呼び出すと現在の作業ディレクトリにあるすべてのファイルのリストが返されます。そのリストを反復処理して、.pdf拡張子のファイルをpdf_filenames変数のリストに追加します(❷)。次に、このリストを、sort()にkey=str.lowerキーワード引数を渡してアルファベット順に並べ替えます(❸)。技術的な理由により、sort()メソッドはZのような大文字をaのような小文字よりも前に並べ替えます。先ほど示したような引数を渡すと文字列を小文字で比較するのでそうした事態を防げます。結合したPDFのページを保持するPdfWriterオブジェクトを作成します(❹)。最後に、プログラムの残りの概要をコメントで書いています。
ステップ2:各PDFを開く
pdf_filenamesの各PDFファイルを開きます。以下のコードです。
# combine_pdfs.py - 現在の作業ディレクトリにあるすべてのPDFファイルを
# 一つのPDFファイルに結合する
import pypdf, os
--snip--
# すべてのPDFファイルを反復処理
for pdf_filename in pdf_filenames:
reader = pypdf.PdfReader(pdf_filename)
# 2ページ目以降のすべてのページをコピー
writer.append(pdf_filename, (1, len(reader.pages)))
# TODO:出力PDFをファイルに保存
それぞれのPDFファイル名につき、ループでPdfReaderオブジェクトを作成し、readerという名前の変数に格納します。ループ内のコードでlen(reader.pages)を呼び出すとそのPDFのページ数がわかります。この情報をappend()メソッド呼び出しで使い、2ページ目から最後のページまでコピーします(PyPDFでは最初のページのインデックスが0です)。その内容をwriterに格納されている同じPdfWriterオブジェクトに追加します。
ステップ3:結果を保存する
このforループが終われば、変数writerにはすべてのPDFのページを結合したPdfWriterオブジェクトが格納されているはずです。最後にこの内容をハードドライブのファイルに書き込みます。このようなコードです。
# combine_pdfs.py - 現在の作業ディレクトリにあるすべてのPDFファイルを
# 一つのPDFファイルに結合する
import pypdf, os
--snip--
# 出力PDFをファイルに保存
with open('combined.pdf', 'wb') as file:
writer.write(file)
open()に'wb'を渡して出力PDFファイルのcombined.pdfをバイナリ書き込みモードで開きます。それから、Fileオブジェクトをwrite()メソッドに渡して実際のPDFファイルを作成します。(同じ名前のwrite()メソッドがFileオブジェクトにもPdfWriterオブジェクトにもあることに注意してください。)プログラムの最後の部分では、一つのPDFに、フォルダ内のすべてのPDFをファイル名のアルファベット順に並べ替えて最初のページ以外のすべてのページが集約されています。
似たようなプログラムのアイデア
別のPDFからページを取り出してPDFを作成できると、以下のようなプログラムを作れます。
- PDFから特定のページを切り取る
- PDFのページを並べ替える
- Pageオブジェクトのextract_text()メソッドを活用して、特定のテキストがあるPDFのページだけを集めたPDFを作成する
Word文書
Pythonでは、Python-Docxパッケージを使って、.docx拡張子のMicrosfot Word文書の作成や変更ができます。付録Aの指示に従ってこのパッケージをインストールしてください。
警告
DocxではなくPython-Docxをインストールするように気をつけてください。Docxは本書で取り上げていない別のパッケージです。ただし、Python-Docxパッケージからモジュールをインポートする際は、import python-docxではなくimport docxを実行します。
Wordを持っていなくても、Windows、macOS、Linuxで.docxファイルを開くのに、フリーのLibreOffice Writerアプリケーションを利用できます。https://
プレーンテキストファイルと違って、.docxファイルには多くの構造的な要素があります。Python-Docxでは3つのデータ型でその要素を表現します。最上位レベルでは、Documentオブジェクトが文書全体を表します。Documentオブジェクトには、文書中の段落を表すParagraphオブジェクトのリストがあります。(Word文書で入力中にENTER(RETURN)キーを押すと新しい段落が始まります。)これらのParagraphオブジェクトは、それぞれ、1つ以上のRunオブジェクトのリストを含みます。図17-4は4つのrun(連続部分)がある一文の段落を示しています。
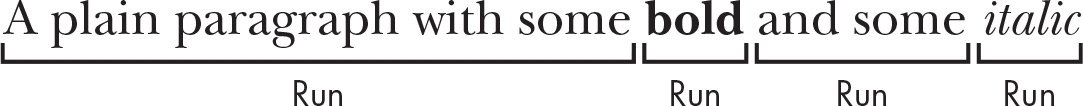
図 17-4:Paragraphオブジェクト内のRunオブジェクト
Word文書中のテキストは単なる文字列ではありません。フォント、サイズ、色その他のスタイル情報があります。Wordのスタイルはこれらの属性の集まりです。Runオブジェクトは同じスタイルのテキストの連続部分です。スタイルを変更するたびに新しいRunオブジェクトが必要になります。
Word文書の読み取り
docxモジュールを試してみましょう。本書のオンライン素材からdemo.docxをダウンロードして、現在の作業ディレクトリに保存してください。そして、対話型シェルに次のように入力します。
>>> import docx
>>> doc = docx.Document('demo.docx')
>>> len(doc.paragraphs)
7
>>> doc.paragraphs[0].text
'Document Title'
>>> doc.paragraphs[1].text
'A plain paragraph with some bold text and some italic'
>>> len(doc.paragraphs[1].runs)
4
>>> doc.paragraphs[1].runs[0].text
'A plain paragraph with some '
>>> doc.paragraphs[1].runs[1].text
'bold'
>>> doc.paragraphs[1].runs[2].text
' and some '
>>> doc.paragraphs[1].runs[3].text
'italic'
Pythonで.docxファイルを開きます。docx.Document()を呼び出してファイル名のdemo.docxを渡します。これによりDocumentオブジェクトが返されます。Paragraphオブジェクトのリストであるparagraphs属性があります。この属性についてlen()を呼び出すと、7が返され、この文書には7つのParagraphオブジェクトがあるとわかります。これらのParagraphオブジェクトにはそれぞれtext属性があり、その段落の(スタイル情報なしの)テキストの文字列が入っています。最初のtext属性には'DocumentTitle'が入っており、2つ目には'A plain paragraph with some bold text and some italic'が入っています。
Paragraphオブジェクトにはそれぞれ、Runオブジェクトのリストであるruns属性があります。Runオブジェクトにもtext属性があり、そのrun(連続部分)のテキストが入っています。2つ目のParagraphオブジェクトのtext属性を見てみましょう。このオブジェクトについてlen()を呼び出すと4つのRunオブジェクトがあることがわかります。最初のRunオブジェクトには'A plain paragraph with some 'が入っています。次に、テキストは太字になりますから、新しい'bold' というRunオブジェクトが始まります。次は太字ではなくなるので3つ目の' text and some 'というRunオブジェクトになります。最後の4つ目のRunオブジェクトは斜体のスタイルの'italic'です。
Python-Docxを使うと、Pythonプログラムで.docxファイルからテキストを読み取り、通常の文字列値と同じように扱えます。
.docxファイルからテキスト全文を取得する
Word文書のテキストしか必要なくスタイル情報が不要なら、ここで作成するget_text()関数を使えます。.docxファイルのファイル名を取り、そのテキストを一つの文字列値で返します。新しいファイルエディタタブを開き、以下のコードをreadDocx.pyという名前で保存してください。
import docx
def get_text(filename):
doc = docx.Document(filename)
full_text = []
for para in doc.paragraphs:
full_text.append(para.text)
return '\n'.join(full_text)
このget_text()関数はWord文書を開き、paragraphsリストのすべてのParagraphオブジェクトを反復処理し、そのテキストをfull_textのリストに追加します。ループが終了したら、full_textの文字列を改行文字で連結します。
readDocx.pyプログラムを他のモジュールと同じようにインポートできます。Word文書のテキストだけが必要なら、以下のように実行します。
>>> import readDocx
>>> print(readDocx.get_text('demo.docx'))
Document Title
A plain paragraph with some bold text and some italic
Heading, level 1
Intense quote
first item in unordered list
first item in ordered list
文字列を返す前に調整することもできます。例えば、各段落を字下げするなら、 readDocx.pyのappend()呼び出しを次のように変更します。
full_text.append(' ' + para.text)段落間の改行を2つにするなら、join()呼び出しを次のように変更します。
return '\n\n'.join(full_text)ご覧のように、.docxファイルを読み取って好みの形でその内容を文字列で返す関数を数行のコードで書くことができます。
ParagraphオブジェクトとRunオブジェクトのスタイル
Wordその他のワープロでは、スタイルを使ってテキストの見た目の一貫性を保ち、変更をしやすくしています。例えば、本文の段落をすべて11ポイントのTimes New Romanで左寄せにすることができます。このような設定のスタイルを本文の段落全体に適用できます。あとで文書中の本文の段落全体の見た目を変えたくなったとしたら、スタイルを変更して段落全体の見た目を自動的に変更できます。
ブラウザベースのOffice 365 Wordでスタイルを確認するには、ホームメニューをクリックして、見出しとその他のスタイルドロップダウンメニューをクリックすると、おそらくノーマルその他のスタイルの名前が表示されます。スタイルのオプションをクリックすると、その他のスタイルウィンドウが表示されます。WindowsのMicrosoft Wordデスクトップアプリケーションでは、CTRL-ALT-SHIFT-Sを押すと、図17-5のようにスタイル枠にスタイルが表示されます。LibreOffice Writerでは、表示スタイルメニュー項目をクリックすればスタイル枠が表示されます。
図 17-5:スタイル枠
Word文書には3つの種類のスタイルがあります。Paragraphオブジェクトに適用される段落スタイルと、Runオブジェクトに適用される文字スタイルと、両方のオブジェクトに適用されるリンクスタイルです。Paragraphオブジェクト及びRunオブジェクトについては、style属性にスタイル名の文字列を設定します。styleがNoneに設定されると、ParagraphオブジェクトないしRunオブジェクトにスタイルは関連づけられません。Wordのデフォルトでは、以下のスタイルがあります。
'Normal' 'Heading 5' 'List Bullet' 'List Paragraph'
'Body Text' 'Heading 6' 'List Bullet 2' 'MacroText'
'Body Text 2' 'Heading 7' 'List Bullet 3' 'No Spacing'
'Body Text 3' 'Heading 8' 'List Continue' 'Quote'
'Caption' 'Heading 9' 'List Continue 2' 'Subtitle'
'Heading 1' 'Intense Quote' 'List Continue 3' 'TOC Heading'
'Heading 2' 'List' 'List Number ' 'Title'
'Heading 3' 'List 2' 'List Number 2'
'Heading 4' 'List 3' 'List Number 3'
Runオブジェクトにリンクスタイルを適用する際は、名前の末尾に' Char'をつけます。例えば、Paragraphオブジェクトに'Quote'リンクスタイルを設定するには、paragraphObj.style = 'Quote'としますが、Runオブジェクトに設定するには、runObj.style = 'Quote Char'とします。
カスタムスタイルを作成するには、Wordアプリケーションで定義して、それをParagraphオブジェクトまたはRunオブジェクトのstyle属性から読み取ります。
Run属性の適用
Run属性でrunのスタイルを設定できます。各属性はTrue(他のスタイルが適用されていても常にその属性が有効化される)、False(常にその属性が無効化される)、None(runのスタイルのデフォルトにする)のいずれかに設定されます。表17-1はRunオブジェクトに設定できる属性の一覧です。
Attribute |
|
|---|---|
bold |
テキストを太字にする |
italic |
テキストを斜体にする |
underline |
テキストに下線を引く |
strike |
テキストに取り消し線を引く |
double_strike |
テキストに二重取り消し線を引く |
all_caps |
テキストを大文字で表示する |
small_caps |
テキスト少し小さい大文字で表示する |
shadow |
テキストを影付きにする |
outline |
テキストを実線ではなく枠線で表示する |
rtl |
テキストを右から左に書くようにする |
imprint |
テキストを刻印表示にする |
emboss |
テキストを浮き彫り表示にする |
例えば、対話型シェルに次の内容を入力して、demo.docxのスタイルを変更してみてください。
>>> import docx
>>> doc = docx.Document('demo.docx')
>>> doc.paragraphs[0].text
'Document Title'
>>> doc.paragraphs[0].style # idは異なるかもしれない
_ParagraphStyle('Title') id: 3095631007984
>>> doc.paragraphs[0].style = 'Normal'
>>> doc.paragraphs[1].text
'A plain paragraph with some bold text and some italic'
>>> (doc.paragraphs[1].runs[0].text, doc.paragraphs[1].runs[1].text,
doc.paragraphs[1].runs[2].text, doc.paragraphs[1].runs[3].text)
('A plain paragraph with some ', 'bold', ' and some ', 'italic')
>>> doc.paragraphs[1].runs[0].style = 'Quote Char'
>>> doc.paragraphs[1].runs[1].underline = True
>>> doc.paragraphs[1].runs[3].underline = True
>>> doc.save('restyled.docx')
文書中の段落を見やすくするために属性を使っています。段落をrunに分割してそれぞれのrunに個別にアクセスするのは簡単です。2つ目の段落の1つ目と2つ目と4つ目のrunを取得し、スタイルを調整して、新しい文書に保存します。
restyled.docxの冒頭のDocument Titleという文言がTitleスタイルではなくNormalスタイルになりました。A plain paragraph with someというテキストのRunオブジェクトをQuote Charスタイルにして、boldとitalicの2つのRunオブジェクトのunderline属性をTrueに設定しました。図17-6はrestyled.docxの段落とrunがどのようなスタイルになっているかを示しています。
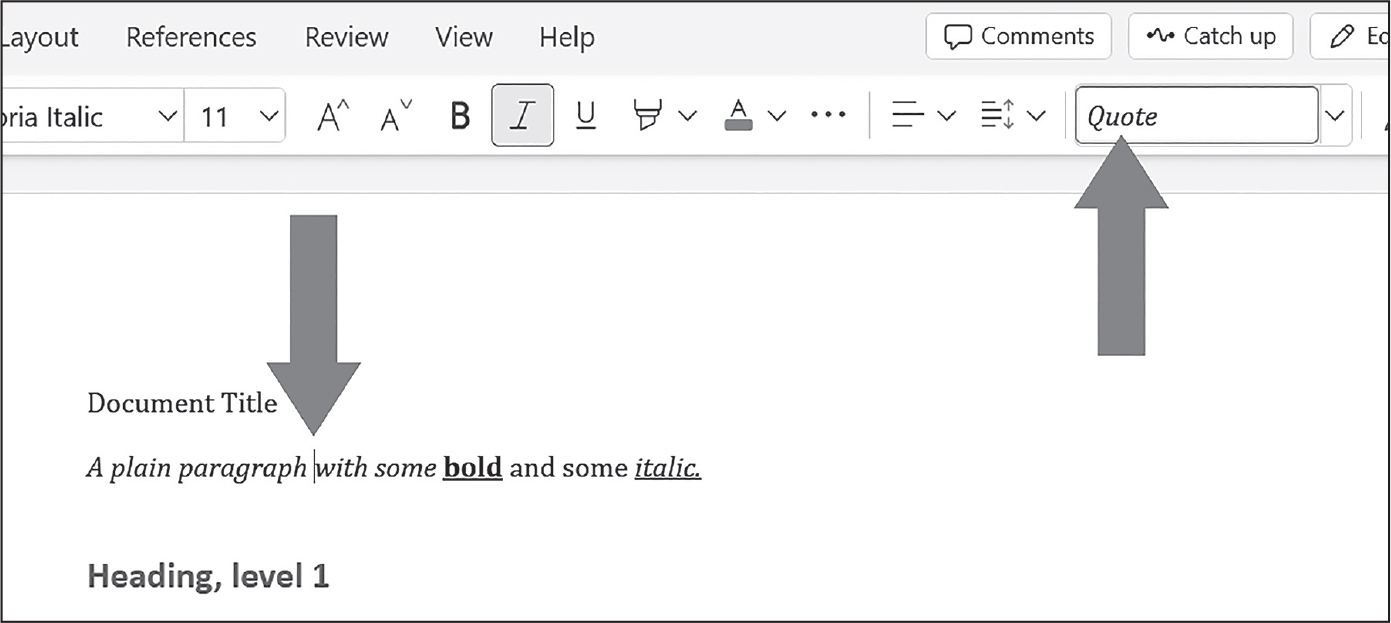
図 17-6:restyled.docxファイル
Python-Docxのスタイルの使い方はhttps://
Word文書の作成
.docx ファイルを作成するには、docx.Document()を呼び出して新しい空白のDocumentオブジェクトを取得します。対話型シェルで次のように入力してみてください。
>>> import docx
>>> doc = docx.Document()
>>> doc.add_paragraph('Hello, world!')
<docx.text.paragraph.Paragraph object at 0x0000000003B56F60>
>>> doc.save('helloworld.docx')
add_paragraph()ドキュメントメソッドは、文書に新しい段落のテキストを追加し、追加されたParagraphオブジェクトへの参照を返します。テキストを追加したら、ファイル名の文字列をsave()ドキュメントメソッドに渡してDocumentオブジェクトをファイルに保存します。
このコードは、helloworld.docxという名前のファイルを現在の作業ディレクトリに作成します。そのファイルを開くと、図17-7のようになっているはずです。この.docxファイルをOffice 365やGoogle Docsにアップロードすることができますし、WordやLibreOfficeで開くこともできます。
図 17-7:add_paragraph('Hello, world!')を使って作成したWord文書
テキストを渡してadd_paragraph()メソッドを繰り返し呼び出すことで、文書に段落を追加できます。既存の段落の末尾にテキストを追加するには、文字列を渡してその段落のadd_run()メソッドを呼び出します。以下の式を対話型シェルに入力してみてください。
>>> import docx
>>> doc = docx.Document()
>>> doc.add_paragraph('Hello world!')
<docx.text.paragraph.Paragraph object at 0x000000000366AD30>
>>> para_obj_1 = doc.add_paragraph('This is a second paragraph.')
>>> para_obj_2 = doc.add_paragraph('This is a yet another paragraph.')
>>> para_obj_1.add_run(' This text is being added to the second paragraph.')
<docx.text.run.Run object at 0x0000000003A2C860>
>>> doc.save('multipleParagraphs.docx')
図17-8のような文書が作成されるはずです。This text is being added to the second paragraph.というテキストが、docに追加された2つ目の段落であるpara_obj_1のParagraph オブジェクトに追加されています。add_paragraph()とadd_run()は、それぞれParagraphオブジェクトとRunオブジェクトを返すので、オブジェクトの作成と取得を別々に行う必要はありません。
もう一度save()メソッドを呼び出して変更点を保存してください。
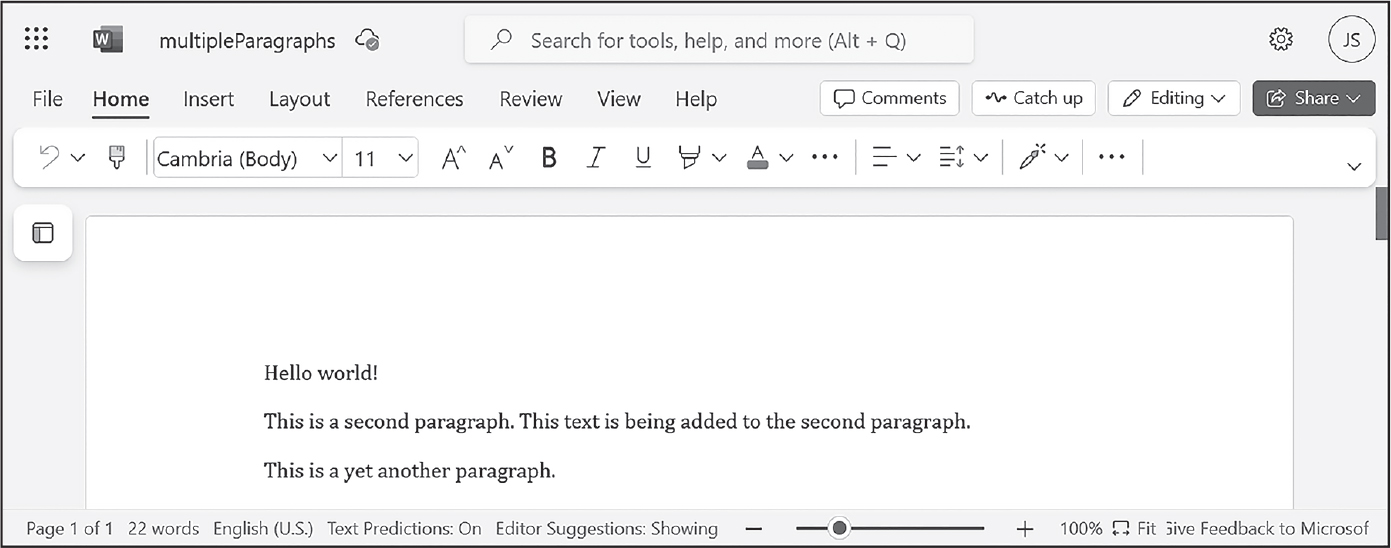
図 17-8:複数のParagraphオブジェクトと Runオブジェクトを追加した文書
add_paragraph()とadd_run()には、ParagraphオブジェクトないしRunオブジェクトのスタイルの文字列を取るオプションの第二引数があります。例を示します。
>>> doc.add_paragraph('Hello, world!', 'Title')
<docx.text.paragraph.Paragraph object at 0x00000213E6FA9190>
このコードはTitleスタイルのHello, world!テキストの段落を追加します。
見出しの追加
add_heading()を呼び出すと見出しスタイルの段落を追加します。以下の式を対話型シェルに入力してみてください。
>>> import docx
>>> doc = docx.Document()
>>> doc.add_heading('Header 0', 0)
<docx.text.paragraph.Paragraph object at 0x00000000036CB3C8>
>>> doc.add_heading('Header 1', 1)
<docx.text.paragraph.Paragraph object at 0x00000000036CB630>
>>> doc.add_heading('Header 2', 2)
<docx.text.paragraph.Paragraph object at 0x00000000036CB828>
>>> doc.add_heading('Header 3', 3)
<docx.text.paragraph.Paragraph object at 0x00000000036CB2E8>
>>> doc.add_heading('Header 4', 4)
<docx.text.paragraph.Paragraph object at 0x00000000036CB3C8>
>>> doc.save('headings.docx')
作成されるheadings.docxファイルは図17-9のように見えるはずです。
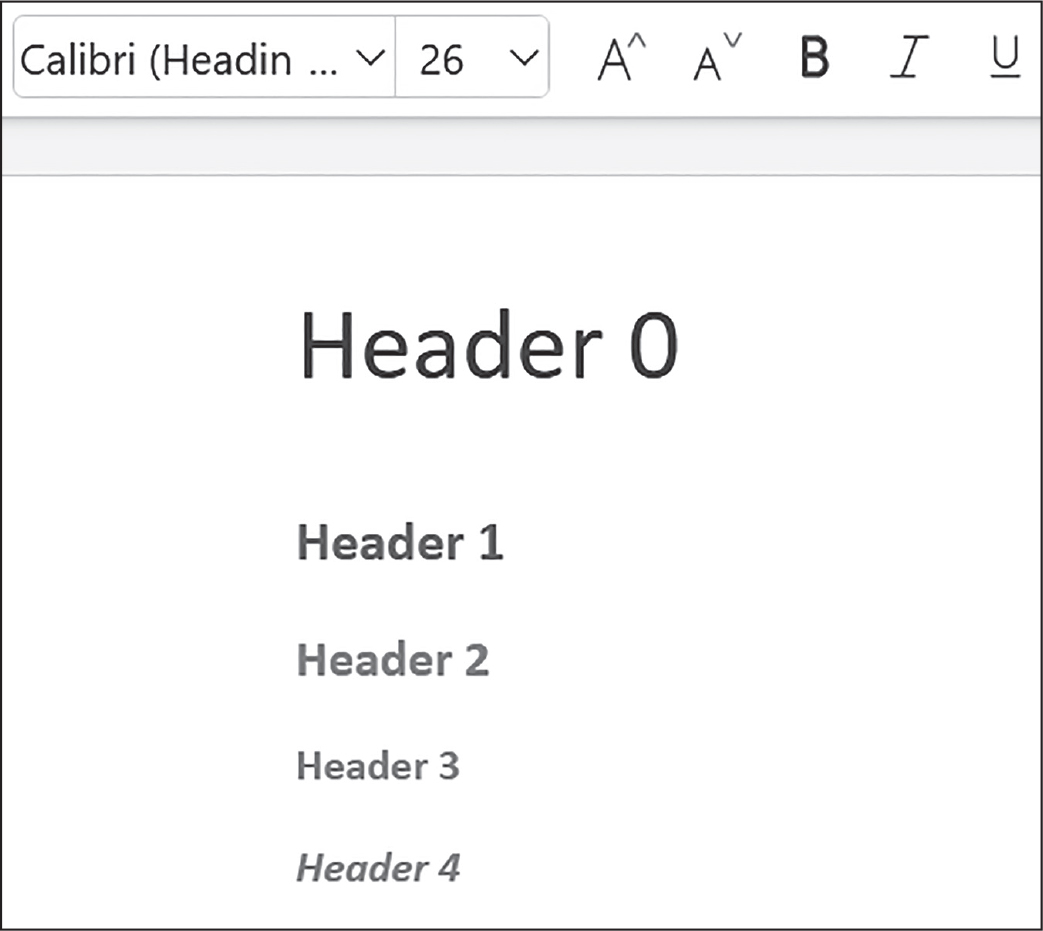
図 17-9:見出し0から見出し4があるheadings.docx文書
上記のコードにおけるadd_heading()の引数はテキストと0から4までの整数です。整数0は見出しをTitleスタイルにします。これを文書の冒頭で使っています。整数の1から9は見出しのレベルです。1が大きな見出しで9が一番小さな見出しです。add_heading()関数はParagraphオブジェクトを返すので、別途DocumentオブジェクトからParagraphオブジェクトを取得する必要はありません。
改行と改ページの追加
(新しい段落を開始するのではなく)改行を追加するには、改行したいRunオブジェクトについてadd_break()メソッドを呼び出します。改ページを追加したければ、add_break()の引数にdocx.enum.text.WD_BREAK.PAGEの値を単独で渡します。
>>> doc = docx.Document()
>>> doc.add_paragraph('This is on the first page!')
<docx.text.paragraph.Paragraph object at 0x0000000003785518>
❶ >>> doc.paragraphs[0].runs[0].add_break(docx.enum.text.WD_BREAK.PAGE)
>>> doc.add_paragraph('This is on the second page!')
<docx.text.paragraph.Paragraph object at 0x00000000037855F8>
>>> doc.save('twoPage.docx')
このコードでは、1ページ目にThis is on the first page!が、2ページ目にはThis is on the second page!がある2ページのWord文書を作成しています。1ページ目のThis is on the first page!のあとにはまだかなり空白がありますが、最初の段落の最初のrunのあとに改ページを挿入して次の段落が強制的に新しいページで始まるようにしました(❶)。
画像の追加
Documentオブジェクトのadd_picture()メソッドを使うと文書の末尾に画像を追加できます。現在の作業ディレクトリにzophie.pngというファイルがあるとします。以下のコードで幅が1インチで高さが4センチメートル(帝国単位とメートル単位のどちらでも可)のzophie.pngを文書の末尾に追加できます。
>>> doc.add_picture('zophie.png', width=docx.shared.Inches(1), height=docx.shared.Cm(4))
<docx.shape.InlineShape object at 0x00000000036C7D30>
第一引数は画像のファイル名の文字列です。オプションのwidthとheightのキーワード引数では文書中の画像の幅と高さを設定します。省略すれば、幅と高さは元の画像の通常サイズになります。
画像の高さと幅をインチやセンチメートルなどの馴染みのある単位で指定する場合は、widthとheightのキーワード引数を指定する際にdocx.shared.Inches()やdocx.shared.Cm()という関数を使えます。
まとめ
テキスト情報はプレーンテキストファイルに限られません。PDFやWord文書を扱うことはよくあるでしょう。PyPDFパッケージを使えばPDF文書を読み書きできます。PDFファイルを読み書きできるPythonのライブラリはほかにもたくさんあります。本章で取り上げたもの以外では、PyPIのウェブサイトで、pdfplumber、ReportLab、pdfrw、PyMuPDF、pdfkit、borb を検索することをおすすめします。
残念ながら、PDF文書からテキストを読み取る精度は完全ではありません。ファイルフォーマットが複雑で、全く読み取れないPDFもあるかもしれません。pdfminer.sixパッケージは保守されていないpdfminerパッケージのフォークで、PDFからのテキスト抽出に注力しています。本章ではPDFファイルからテキストを抽出できなかった場合にpdfminer.sixを使う仕組みを導入しました。
Word文書はPDFよりも信頼性が高く、python-docxパッケージのdocxモジュールを使うと読み取れます。ParagraphオブジェクトとRunオブジェクトを通じてWord文書中のテキストを操作できます。これらのオブジェクトはスタイルを適用することもできます。ただし、スタイルはデフォルトのものかすでに文書中にあるものしか使えません。新しい段落、見出し、改行、改ページ、画像を文書の末尾に追加できます。
PDFやWord文書は、ソフトウェアで解析しやすくすることではなく人間にとって見やすく表示することを意図したフォーマットなので、これらのファイルでの作業には多くの制約があります。次章では、CSV、JSON、XMLファイルという情報を保存するのに一般的に用いられる別のフォーマットを紹介します。これらのフォーマットはコンピュータによる利用が想定されており、PDFやWordと比べてPythonでの作業がずっと簡単にできます。
練習問題
1. PDFファイルを保存するには、どのモードでPdfWriterオブジェクト用のFileオブジェクトを開く必要がありますか?
2. PdfReaderオブジェクトまたはPdfWriterオブジェクトから、5ページ目のPageオブジェクトを取得するにはどうしますか?
3. PdfReaderオブジェクトのPDFがパスワードswordfishで暗号化されていたら、Pageオブジェクトを取得する前に何をしなければならないですか?
4. rotate()メソッドは時計回りにページを回転させますが、反時計回りに回転させるにはどうしますか?
5. demo.docxという名前のファイルのDocumentオブジェクトを返すメソッドは何ですか?
6. ParagraphオブジェクトとRunオブジェクトの違いは何ですか?
7. docという名前の変数に格納されているDocumentオブジェクトのParagraphオブジェクトのリストを取得するにはどうしますか?
8. bold、underline、italic、strike、outlineという属性を持っているのはどの型のオブジェクトですか?
9. bold属性をTrue、False、Noneに設定するとそれぞれどうなりますか?
10. 新しいWord文書のDocumentオブジェクトはどのように作成しますか?
11. docという名前の変数に格納されているDocumentオブジェクトに'Hello, there!'というテキストの段落を追加するにはどうしますか?
12. Word文書の利用できる見出しのレベルを表す整数は何から何までですか?
練習プログラム
以下の練習プログラムを書いてください。
PDF偏執狂
第11章で紹介したos.walk()関数を使って、フォルダ(とそのサブフォルダ)の中にあるすべてのPDFを、コマンドラインから受け取ったパスワードで暗号化するスクリプトを書いてください。暗号化したPDFファイルは元のファイル名に_encrypted.pdfという接尾辞を加えた名前で保存してください。元のファイルを削除する前に、新しいファイルを読み取って復号して正しく暗号化されていることを確認してください。
それから、すべての暗号化されたPDFをフォルダ(とそのサブフォルダ)から探してパスワードで復号したPDFのコピーを作成するプログラムを書いてください。パスワードが間違っていたら、ユーザーにメッセージを表示して次のPDFに進みます。
カスタム招待状
招待客の名前を書いたテキストファイルがあります。このguests.txtファイルには、以下のように名前が一行で書かれています。
Prof. Plum
Miss Scarlet
Col. Mustard
Al Sweigart
RoboCop
図17-10のように招待客の名前を入れたWord文書を生成するプログラムを書いてください。
Python-DocxはWord文書にすでに存在するスタイルしか使えませんので、まず空白のWordファイルにスタイルを追加してから、Python-Docxでそのファイルを開きます。Word文書で1人分の招待状はページごとに作成します。各招待状の最後の段落のあとに改ページをadd_break()で追加してください。こうすることで、1つのWord文書を開けば全員分の招待状を一気に印刷できます。
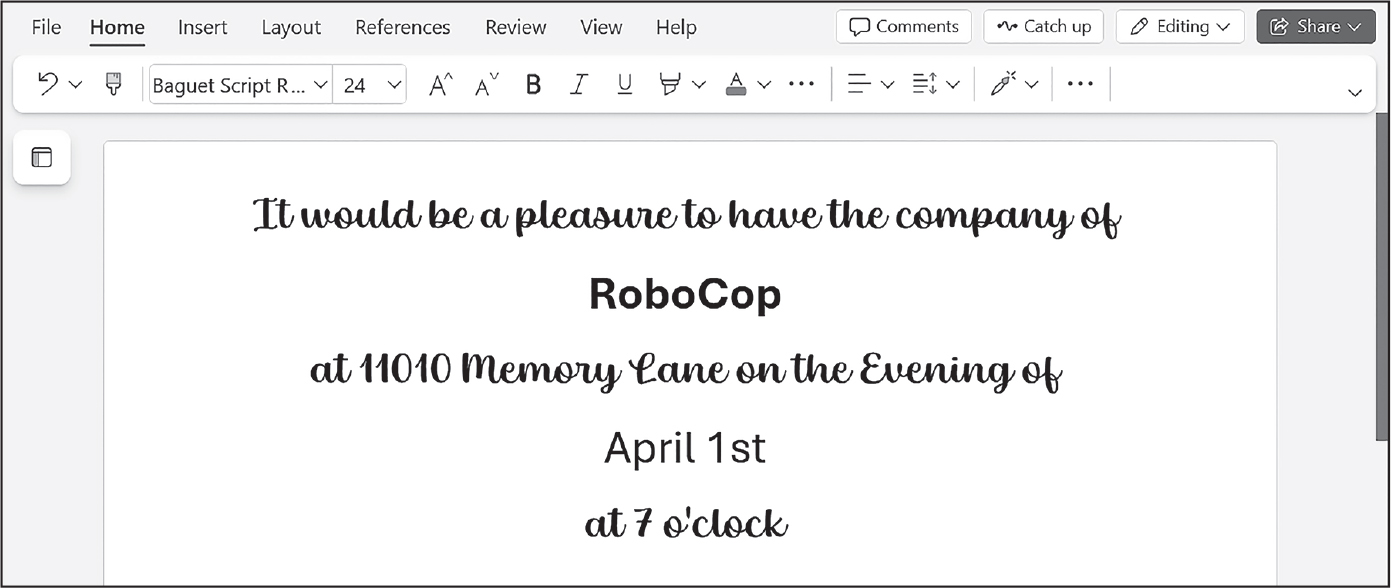
図 17-10:招待状スクリプトで生成されたWord文書
本書のオンライン素材からサンプルのguests.txtファイルをダウンロードできます。
PDFパスワード解除装置
暗号化したPDFファイルのパスワードを忘れてしまいました。ただ、パスワードは英語の1単語だったことは覚えています。忘れたパスワードを当て推量するのは非常に単調な作業です。英単語を一つずつ試して復号するプログラムを書くことができます。これはブルートフォースアタックと呼ばれる手法です。本書のオンライン素材からdictionary.txtというテキストファイルをダウンロードしてください。この辞書には1行に1単語で44,000の英単語が含まれています。
第10章で学んだファイルの読み取りスキルを活用して、このファイルを読み取り単語の文字列リストを作成します。次に、このリストの単語を反復処理し、decrypt()メソッドに渡します。単語ごとに大文字と小文字の両方を試してください。(私のノートパソコンでは、数分でこのファイルの大文字と小文字で合計88,000単語を処理できました。パスワードに単純な英単語を使ってはならないことがよくわかります。)