16 SQLiteデータベース

読者のみなさんはExcelやGoogleスプレッドシートに情報をまとめることに慣れていると思いますが、多くのソフトウェアではデータをデータベースと呼ばれるアプリケーションに保存しています。データベースを利用するとほしいデータを取得しやすくなります。ネコの情報をスプレッドシートやテキストファイルに保存していたとすると、Zophieという名前のネコの毛色を調べたいときに、CTRL-Fを押して「Zophie」と入力すると思います。しかし、体重が3キログラムから5キログラムの間で2023年10月以前に生まれたすべてのネコの毛色を知りたいとしたらどうでしょうか。第9章で説明した正規表現を使っても難しいコードになるでしょう。
データベースでは、SQL(Structured Query Language)というミニ言語で、こうした複雑なクエリを実行できます。SQLという用語はデータベースを操作する言語とその言語を受け入れるデータベースの両方を指します。「エスキューエル」と発音されることが多いですが、「シークェル」と発音されることもあります。本章ではSQLとデータベースの概念をSQLite(「シークェライト」、「エスキューライト」、「エスキューエルライト」と発音されます)を使って説明します。SQLiteはPythonに同梱されている軽量データベースです。
SQLiteは最も広く展開されているデータベースソフトウェアです。どのOSでも動きますし、別のアプリケーションに埋め込めるほど小さいです。他方で、SQLiteはシンプルであるため、他のデータベースとは顕著に異なります。PostgreSQL、MySQL、Microsoft SQL Server、Oracleなどの大規模なデータベースソフトウェアは、ネットワークを介してアクセスされる専用のハードウェアのサーバーで実行されることが想定されていますが、SQLiteはデータベース全体をコンピュータ上の一つのファイルに保存します。
SQLデータベースに慣れている人でも、SQLiteはクセがありますから、本章の説明を読んでください。SQLiteのオンラインドキュメントはhttps://
スプレッドシートとデータベース
スプレッドシートとデータベースの異同を検討しましょう。スプレッドシートでは、各行がそれぞれのレコードであり、各列がそれぞれのレコードのフィールドに保存されたデータの種類を表します。例えば、図16-1は私のネコのスプレッドシートです。列は名前、生年月日、毛色、体重(キログラム)です。
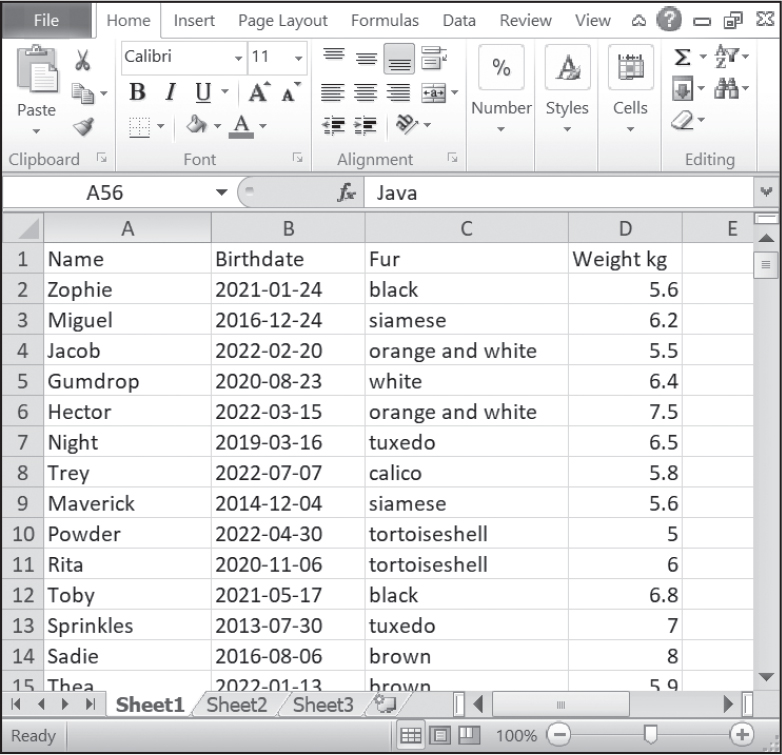
図 16-1:スプレッドシートはデータレコードを定められた列構造の行に保存する
この同じ情報をデータベースに保存できます。データベースに含まれるテーブルをスプレッドシートになぞらえることができます。テーブルにはそれぞれのレコード(行やエントリーと呼ばれることもあります)の特性に応じたカラム(列)があります。SQLiteのようなデータベースはリレーショナルデータベースと呼ばれます。リレーション(関係)というのは、データベースに含まれる複数のテーブル間の関係のことです(後述します)。
スプレッドシートもデータベースも、保存しているデータにラベルをつけます。スプレッドシートは、列にはアルファベット、行には数字のラベルを自動的につけます。さらに、先ほどの例のネコのスプレッドシートでは、最初の行が列を説明する名前になっています。2行目以下は一つの行が一匹のネコを表しています。SQLデータベースでは、各テーブルにたいていIDカラムがあります。IDカラムはレコードの主キーで、レコードを明確に特定できる一意の整数です。SQLiteでは、このカラムがrowidと呼ばれ、自動的にテーブルに追加されます。
スプレッドシートの行を削除するとその下の行が繰り上がり、行番号が変わります。しかしデータベースのレコードの主キーIDは一意であって変更されません。この特性は多くの状況で役立ちます。ネコの名前が変わったり体重の増減があったりした場合にどうなるでしょうか。名前のアルファベット順に行を並べ替えたい場合はどうすればよいでしょうか。ネコには、データが変わっても一定である固有のID番号が必要です。SQLiteのテーブルのrowidカラムに相当するようなID列をスプレッドシートに設けることも可能です。行が削除されたり移動されたりしても、このID値は同じままです。それを図16-2に示しました。Row IDが5から10の行を削除しました。
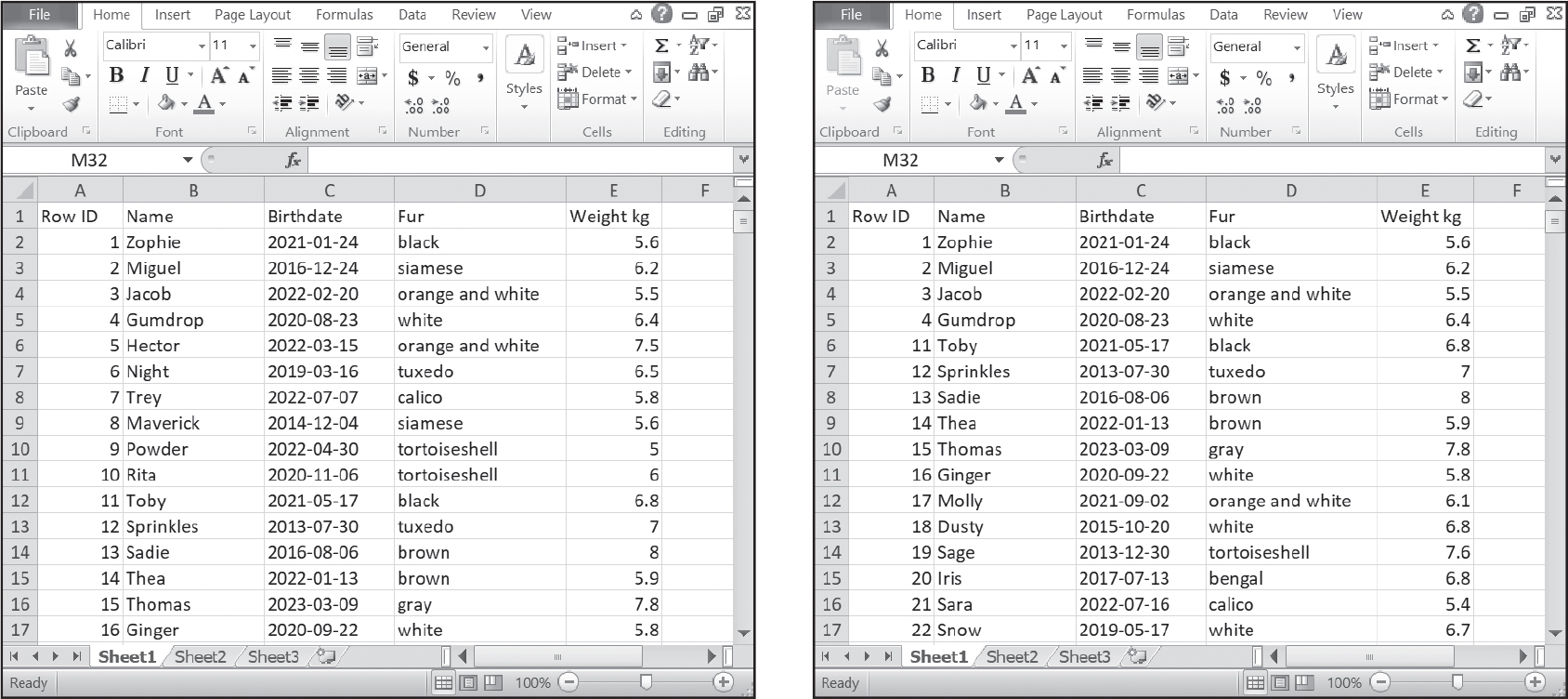
図 16-2:Row ID番号は、スプレッドシートの行番号とは異なり、IDが5から10のネコを削除した後でも(右側)、それぞれのレコードを一意に識別する(左側)
スプレッドシートは、データベースとは全く異なるやり方で使われることもあります。行ベースのデータを保存するのではなく、テンプレートとして使われることがあります。図16-3のようなスプレッドシートを目にしたことがあるでしょう。
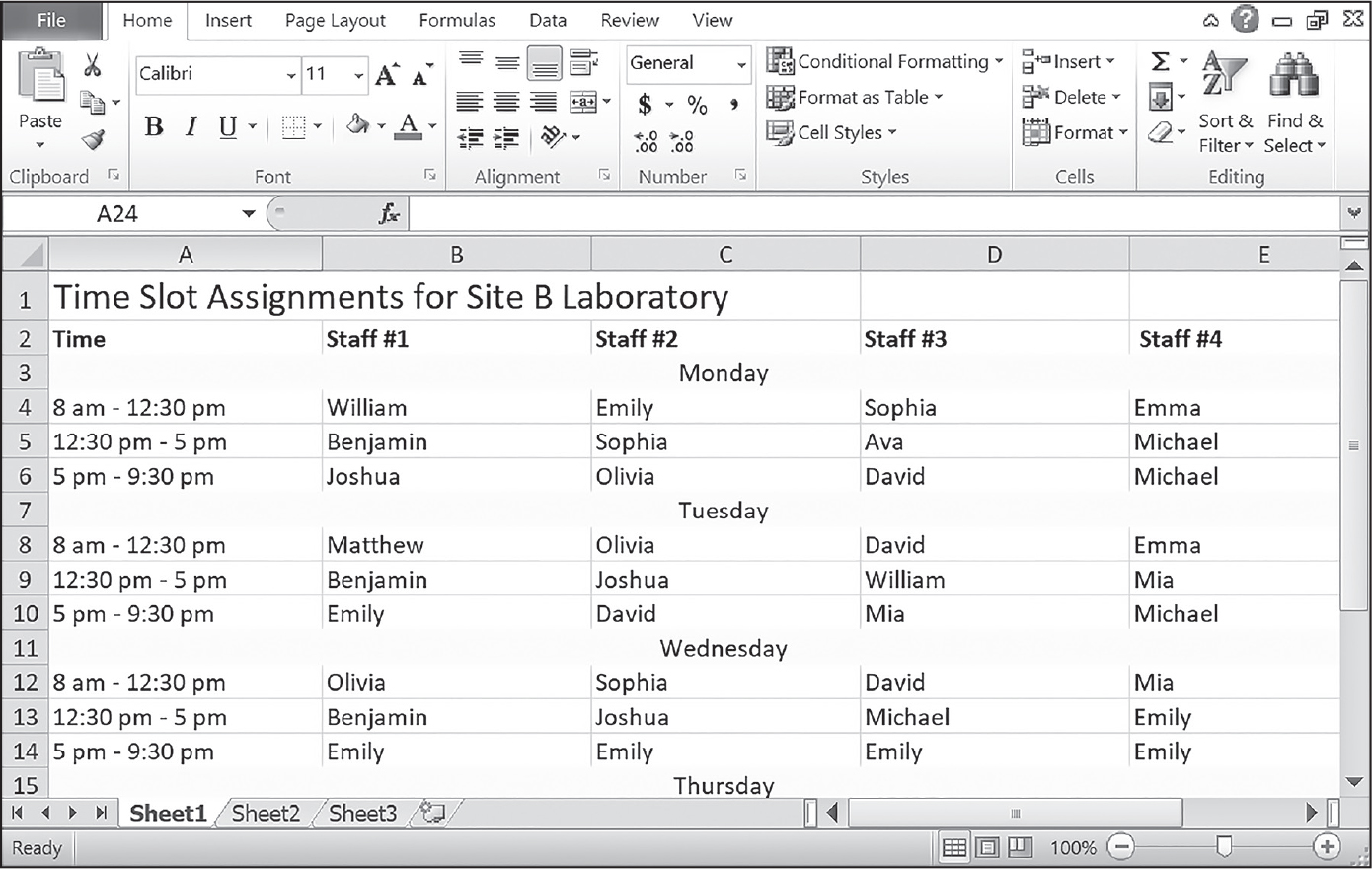
図 16-3:フォーマットされてサイズが固定されたスプレッドシートはデータベースではない
このようなスプレッドシートは、背景色、セル結合、フォントなどのフォーマットを多用しており、人間の目には見やすいです。行ベースのデータのスプレッドシートは無限に下へと新しいデータを追加できるのに対し、こうしたスプレッドシートはサイズが固定されていて空欄を埋めていく方式のデザインになっています。Pythonプログラムがデータを抽出することではなく、人間が印刷して眺めることが意図されています。
データベースは見た目のためのものではなく、生のデータを保存します。さらに重要なこととして、スプレッドシートはどのセルにどのようなデータでも入れられる柔軟性がありますが、データベースにはソフトウェアがデータを取得しやすくするための厳格な構造があります。上に示した例のようにデータがフォーマットされていたら、第14章のopenpyxlライブラリや第15章のEZSheetsライブラリを使って、ExcelやGoogleスプレッドシートのまま処理したほうがよいでしょう。
SQLiteと他のSQLデータベース
他のSQLデータベースに慣れている人は、SQLiteがそれとどう違うのか気になるところでしょう。端的に言うと、SQLiteは単純さと強力さのバランスを保っています。SQLで大量のデータを読み書きする完全なリレーショナルデータベースでありながら、Pythonプログラム内で実行され一つのファイルで操作が完結します。sys、mathその他のPython標準ライブラリと同じようにsqlite3モジュールをインポートします。
SQLiteと他のデータベースソフトウェアとの主な違いを列挙します。
- SQLiteは一つのファイルにデータを保存するので、移動、コピー、バックアップなどが簡単
- SQLiteは、組み込みデバイスや数十年前のノートパソコンなど、リソースが乏しいコンピュータでも実行できる
- SQLiteはサーバーレスであるため、バックグラウンドのサーバーアプリケーションが不要であり、ネットワーク通信も不要
- ユーザー目線では、SQLiteはPythonプログラムの一部であり、インストールと設定が不要
- 速度パフォーマンスの観点からは、SQLiteはメモリ内で動作してプログラムの終了前にファイルに書き出すことができる
- 他のSQLデータベースと同様に、カラムには数値型やテキスト型などのデータ型があるが、SQLiteはカラムのデータ型を厳密に強制はしない
- パーミッション(権限)その他のユーザーロールの設定が不要であり、他のSQLデータベースにあるようなGRANT文やREVOKE文は存在しない
- SQLiteはパブリックドメインのソフトウェアであり、商用利用でもどのような利用でも制限なしにできる
SQLiteの大きな弱点は、(ソーシャルメディアのウェブアプリで行われるような)数十万の同時書き込み操作を効率的に扱えないことです。その点を除けば、SQLiteは他のデータベースと同じくらい強力で、GBやTB単位のデータを確実に処理でき、同時読み取りを高速で簡単に行えます。
SQLiteは、他のデータベースよりも、テキストファイル(や第18章で取り上げるJSON、XML、CSVファイル)をopen()関数を使って操作することに近いです。大量のデータを保存して素早く検索する必要があるなら、SQLiteがJSONやスプレッドシートファイルよりも優れた方法になります。
データベースとテーブルの作成
最初のデータベースとテーブルをSQLを使って作成してみましょう。SQLは、正規表現のように、Python内で使えるミニ言語です。正規表現と同様に、SQLクエリはPythonの文字列値として書けます。正規表現を使わずにそれと同等のテキストのパターンマッチングを行うPythonのコードを書けるのと同じように、SQLクエリを使わずにPythonの辞書やリストのデータを検索するPythonのコードを書くことは確かにできます。しかし正規表現やSQLデータベースクエリを書くと、最初は新しい技術の学習を求められますが、長期的にはそうした作業がずっとシンプルになります。新しいデータベースでテーブルを作成するクエリの書き方から始めましょう。
ネコについての情報を保存するexample.dbという名前のファイルでサンプルのSQLiteデータベースを作成します。データベースを作成するには、まずsqlite3モジュールをインポートします(3はSQLiteのメジャーバージョンの3で、Python3とは関係ありません)。SQLiteデータベースは一つのファイルで完結します。ファイル名は何でもいいですが、慣習的に.dbというファイル拡張子にします。.sqliteという拡張子も一般的に用いられます。
データベースは複数のテーブルを持ち、各テーブルは一定の型のデータを保存します。例えば、あるテーブルにネコのレコードを保存し、別のテーブルに最初のテーブルのネコのワクチン接種レコードを保存します。テーブルはタプルのリストで、それぞれのタプルがテーブルの行だと考えることができます。catsテーブルは本質的には[('Zophie', '2021-01-24', 'black', 5.6), ('Colin', '2016-12-24', 'siamese', 6.2), ...]というタプルのリストと同じです。
データベースを作成して、ネコのデータを保存するテーブルを作成し、何匹かのネコのレコードを挿入して、データベースからそのデータを読み取り、データベース接続を閉じてみましょう。
データベースに接続する
sqlite3.connect()を呼び出してデータベースのConnectionオブジェクトを取得するのがSQLiteのコードを書く第一歩です。以下の式を対話型シェルに入力してみてください。
>>> import sqlite3
>>> conn = sqlite3.connect('example.db', isolation_level=None)
この関数の第一引数は、データベースファイルのファイル名の文字列かpathlib.Pathオブジェクトのいずれかです。指定されたファイルが存在しなければ、新しい空白のデータベースを作成します。例えば、sqlite3.connect('example.db', isolation_level=None)は、現在の作業ディレクトリにあるexample.dbという名前のファイルのデータベースに接続します。そのファイルが存在しなければ、空白のデータベースファイルを作成します。
存在はするけれどもSQLiteデータベースファイルではないファイルを指定した場合は、クエリを実行しようとしたときにsqlite3.DatabaseError: file is not a database例外が送出されます。第10章の「有効なパスかどうかをチェックする」で、ファイルが存在するかどうかを判定するのに使える、Pathメソッドのexists()と、os.path.exists()関数を説明しています。
isolation_level=Noneキーワード引数を指定すると、データベースが自動コミットモードになります。execute()メソッド呼び出し後にcommit()メソッドを呼び出さなくてもすむようになります。
sqlite3.connect()関数はConnectionオブジェクトを返します。先の例ではそのオブジェクトをconnという名前の変数に格納しました。それぞれのConnectionオブジェクトは一つのSQLiteデータベースファイルに接続します。もちろん、このConnectionオブジェクトを格納する変数名は何でもよいのですが、複数のデータベースに同時に接続する場合は、わかりやすい変数名にしたほうがよいです。とはいえ、同時に一つのデータベースにしか接続しない小さなプログラムでは、connという名前が書きやすくて十分にわかりやすいです。(conはもっと短いですが、“console”、“content”、“confusing name for a variable”などと誤解しやすいです。)
プログラムでデータベースの処理を終えたら、conn.close()を呼び出して接続を閉じます。プログラムが終了したらデータベース接続は自動的に閉じられます。
テーブルを作成する
新しい空白のデータベースに接続したら、CREATE TABLEというSQLクエリでテーブルを作成します。SQLクエリを実行するには、Connectionオブジェクトのexecute()メソッドを呼び出します。conn.execute()メソッドにクエリの文字列を渡します。
>>> import sqlite3
>>> conn = sqlite3.connect('example.db', isolation_level=None)
>>> conn.execute('CREATE TABLE IF NOT EXISTS cats (name TEXT NOT NULL,
birthdate TEXT, fur TEXT, weight_kg REAL) STRICT')
<sqlite3.Cursor object at 0x00000201B2399540>
慣習的に、CREATEやTABLEのようなSQLのキーワードは、大文字で書きます。SQLiteは大文字で書くことを強制せず、'create table if not exists cats (name text not null, birthdate text, fur text, weight_kg real) strict'というクエリでも正常に実行されます。テーブル名とカラム名も大文字と小文字を区別しませんが、weight_kgのように小文字にして単語の間はアンダースコアでつなぐのが慣習です。
IF NOT EXISTSをつけずにCREATE TABLE文を実行したら、すでにその名前のテーブルが存在する場合にsqlite3.OperationalError: table cats already exists例外が送出されます。IF NOT EXISTSをつけるとこの例外に悩まされずにすみますので、CREATE TABLEクエリには常にこれをつけることになるでしょう。
先の例では、CREATE TABLE IF NOT EXISTSのあとにテーブル名のcatsを続けました。テーブル名のあとは丸かっこ内に一連のカラム名とデータ型を書きました。
データ型の定義
SQLiteには6つのデータ型があります。
NULL PythonのNoneに対応
INT または INTEGER Pythonのint型に対応
REAL 数学用語の実数を表し、Pythonのfloat型に対応
TEXT Pythonのstr型に対応
BLOB Binary Large Objectの略で、Pythonのbytes型に対応し、ファイル全体をデータベースに保存するときに使う
SQLiteは、Pythonのためだけに作られたものではないので、独自のデータ型があります。他のプログラミング言語からもSQLiteを使えます。
他のSQLデータベースソフトウェアとは異なり、SQLiteはカラムのデータ型について厳密ではありません。SQLiteは、デフォルトで、INTEGER型のカラムに文字列'Hello'を保存しても例外が送出されません。他方で、SQLiteのデータ型は全く意味がないかといえばそうでもなく、カラムのデータ型に応じて可能な場合にはデータが自動的にキャスト(変更)されます。この機能は型親和性と呼ばれます。例えば、文字列の'42'をINTEGER型のカラムに追加したとすると、このカラムには整数型に親和性があるので、SQLiteは自動的に整数の42を値として保存します。しかし、INTEGER型のカラムに文字列'Hello'を追加したとすると、整数型に親和性があるといっても'Hello'は整数に変換できないので、SQLiteは'Hello'を保存します(エラーは発生しません)。
STRICTキーワードでそのテーブルについて厳格モードを有効にできます。厳格モードでは、各カラムにデータ型を設定して、間違った型のデータをテーブルに挿入しようとしたらsqlite3.IntegrityError例外が送出されるようになります。SQLiteはカラムのデータ型に応じてデータを自動的にキャストします。'42'をINTEGER型のカラムに入れようとしたら整数の42が挿入されます。しかし、文字列の'Hello'は整数にキャストできないので、これを挿入しようとすると例外が送出されます。厳格モードを使うことを強くおすすめします。そうすれば不適切なデータをテーブルに挿入するというバグがあったときに早い段階で警告を発してくれます。
SQLiteはSTRICTキーワードをバージョン3.37.0で追加しました。これはPython 3.11以降で使われています。それ以前のバージョンでは厳格モードがなく、厳格モードにしようとすると構文エラーになります。Pythonが使っているSQLiteのバージョンは、以下のように、sqlite3.sqlite _version変数で確かめられます。
>>> import sqlite3
>>> sqlite3.sqlite_version
'3.xx.xx'
SQLiteにはブール型はありませんので、ブール値にはINTEGER型を用いてください。Trueの場合は1を、Falseの場合は0を保存します。SQLiteには日付型や時間型や日時型もありませんので、表16-1に示していますように、TEXT型で文字列を保存します。
形式 |
例 |
|---|---|
YYYY-MM-DD |
'2035-10-31' |
YYYY-MM-DD HH:MM:SS |
'2035-10-31 16:30:00' |
YYYY-MM-DD HH:MM:SS.SSS |
'2035-10-31 16:30:00.407' |
HH:MM:SS |
'16:30:00' |
HH:MM:SS.SSS |
'16:30:00.407' |
name TEXT NOT NULLのNOT NULLという部分では、PythonのNone値がnameカラムに保存できないことを指定しています。必須項目についてはこのように指定します。
SQLiteのテーブルでは、自動的に一意の主キーとなる整数を含むrowidというカラムが作成されます。catsテーブルに偶然名前と生年月日と毛色と体重が同じ2匹のネコがいたとしても、rowidにより区別できます。
テーブルとカラムの一覧表示
すべてのSQLiteデータベースにsqlite_schemaという名前のテーブルがあり、そこにはすべてのテーブルに関して、データベースについてのメタデータが一覧で保存されています。SQLiteデータベースのテーブル一覧を表示するには、以下のクエリを実行してください。
>>> import sqlite3
>>> conn = sqlite3.connect('example.db', isolation_level=None)
>>> conn.execute('SELECT name FROM sqlite_schema WHERE type="table"').fetchall()
[('cats',)]
先ほど作成したcatsテーブルが出力されています。(SELECT文の構文については「データベースからデータを読み取る」で説明します。)catsテーブルのカラム情報を取得するには、以下のクエリを実行してください。
>>> import sqlite3
>>> conn = sqlite3.connect('example.db', isolation_level=None)
>>> conn.execute('PRAGMA TABLE_INFO(cats)').fetchall()
[(0, 'name', 'TEXT', 1, None, 0), (1, 'birthdate', 'TEXT', 0, None, 0), (2,
'fur', 'TEXT', 0, None, 0), (3, 'weight_kg', 'REAL', 0, None, 0)]
このクエリは、テーブルの各カラムを説明するタプルのリストを返します。例えば、(1, 'birthdate', 'TEXT', 0, None, 0)のタプルはbirthdateカラムの情報です。
カラム位置 1はそのカラムがテーブルの2番目にあることを示します。カラム番号は、Pythonのリストと同じようにゼロ始まりですので、最初のカラムの位置は0です。
カラム名 'birthdate'はカラム名です。SQLiteのカラム名とテーブル名は大文字と小文字を区別しません。
データ型 'TEXT'はbirthdateカラムのSQLiteのデータ型です。
NOT NULLの有無 0はFalseを意味し、このカラムはNOT NULLではないこと(このカラムにNone値を入れられること)を示します。
デフォルト値 Noneは値が指定されなかったときに挿入されるデフォルトの値です。
主キーの有無 0はFalseを意味し、このカラムは主キーのカラムではないことを示します。
sqlite_schemaテーブル自体はテーブルとして一覧表示されません。sqlite_schemaテーブルを自分で修正することは決してないでしょうし、そのようなことをしたらデータベースが破損して読めなくなる可能性があります。
データベースのCRUD操作
CRUDはデータベースが実行する4つの基本操作――作成(Create)、読み取り(Read)、更新(Update)、削除(Delete)――の頭字語です。SQLiteでは、これらの操作を、それぞれ、INSERT文、SELECT文、UPDATE文、DELETE文で行います。conn.execute()に文字列として渡すことになる、それぞれの文の例を示します。
- INSERT INTO cats VALUES ("Zophie", "2021-01-24", "black", 5.6)
- SELECT rowid, * FROM cats ORDER BY fur
- UPDATE cats SET fur = "gray tabby" WHERE rowid = 1
- DELETE FROM cats WHERE rowid = 1
ほとんどのアプリケーションやソーシャルメディアサイトは、実際のところ、CRUDデータベースの手の込んだユーザーインターフェイスです。写真を投稿したり返信したりすると、どこかにあるデータベースにレコードを作成しています。ソーシャルメディアのタイムラインをスクロールしたら、データベースからレコードを読み取っています。投稿を編集や削除したら、更新や削除の操作を実行しています。新しいアプリやプログラミング言語やクエリ言語の使い方を学ぶ際には、CRUDの基本操作を軸に考えてください。
データベースにデータを挿入する
データベースとcatsテーブルを作成したので、私のペットのネコのレコードを挿入しましょう。私は約300匹のネコを家で飼っていて、SQLiteデータベースを使って管理しています。INSERT文でテーブルに新しいレコードを挿入できます。対話型シェルに以下のコードを入力してください。
>>> import sqlite3
>>> conn = sqlite3.connect('example.db', isolation_level=None)
>>> conn.execute('CREATE TABLE IF NOT EXISTS cats (name TEXT NOT NULL, birthdate TEXT,
fur TEXT, weight_kg REAL) STRICT')
<sqlite3.Cursor object at 0x00000201B2399540>
>>> conn.execute('INSERT INTO cats VALUES ("Zophie", "2021-01-24", "black", 5.6)')
<sqlite3.Cursor object at 0x00000162842E78C0>
INSERTクエリはcatsテーブルに新しい行を追加します。丸かっこ内はカンマ区切りの各カラムの値です。INSERTクエリでは丸かっこが必須です。TEXT値を挿入する際には、すでにシングルクォート(')をクエリ文字列で使っているので、ダブルクォート(")を使っています。sqlite3モジュールでは、TEXT値にシングルクォートでもダブルクォートでも使えます。
トランザクション
INSERT文はトランザクションを開始します。トランザクションとは、データベースでの作業単位です。トランザクションはACID特性を持たなければなりません。ACIDとは、以下の概念を指します。
Atomic(原子性) トランザクションは全部実行されるか全く実行されないかのどちらかでなければならない。
Consistent(一貫性) トランザクションは、カラムのNOT NULLなどの制約に違反してはならない。
Isolated(独立性) 一つのトランザクションは別のトランザクションに影響を及ぼしてはならない。
Durable(永続性) コミットされたらトランザクションの結果はハードドライブなどの永続的なストレージに書き込まれる。
SQLiteはACID特性を持つデータベースです。トランザクションの途中でコンピュータの電源が落ちても大丈夫だと検証されているので、データベースファイルが破損して読めなくなることはないと信頼できます。SQLiteのクエリはデータを全部データベースに挿入するか、全く挿入しないかのいずれかです。
SQLインジェクション攻撃
SQLインジェクション攻撃と呼ばれる攻撃手法により、意図しないクエリに変更されてしまうことがあります。こうした攻撃手法について解説するのは本書の範囲外であり、自分で書いたプログラムがインターネット上の知らない人からデータを受け取ることがなければこの攻撃を受けることもないでしょう。しかし、この攻撃を防ぐために、データベースのデータの挿入や更新に変数を参照する場合は常にクエスチョンマーク構文を使うようにしてください。
例えば、変数に格納されたデータをもとに新しいネコのレコードを挿入したいとしたら、このようにPythonでこれらの変数を直接クエリ文字列に挿入しないでください。
>>> cat_name = 'Zophie'
>>> cat_bday = '2021-01-24'
>>> fur_color = 'black'
>>> cat_weight = 5.6
>>> conn.execute(f'INSERT INTO cats VALUES ("{cat_name}", "{cat_bday}",
"{fur_color}", "{cat_weight}")')
<sqlite3.Cursor object at 0x0000022B91BB7C40>
これらの変数の値がウェブアプリのフォームなどユーザーの入力に由来する場合は、攻撃者がクエリの意味を変える文字列を指定する可能性があります。変数を直接クエリ文字列に挿入するのではなく、クエリ文字列で?を用いて、クエリ文字列のあとでリスト引数内で変数を渡します。
>>> conn.execute('INSERT INTO cats VALUES (?, ?, ?, ?)', [cat_name, cat_bday,
fur_color, cat_weight])
<sqlite3.Cursor object at 0x0000022B91BB7C40>
execute()メソッドは、SQLインジェクションを引き起こさないことを確認してから、?のクエリ文字列中のプレースホルダーを変数の値に置き換えます。自分が書いて自分が実行するプログラムでそうした攻撃を受けることはないでしょうが、クエリ文字列を自分で組み立てるのではなく?プレースホルダーを用いるのはよい習慣です。
データベースからデータを読み取る
データベースにデータがあれば、SELECTクエリでそのデータを読み取ることができます。対話型シェルに以下の内容を入力して、example.dbデータベースからデータを読み取ってみましょう。
>>> import sqlite3
>>> conn = sqlite3.connect('example.db', isolation_level=None)
>>> conn.execute('SELECT * FROM cats').fetchall()
[('Zophie', '2021-01-24', 'black', 5.6)]
SELECTクエリを実行するexecute()メソッドを呼び出すと、Cursorオブジェクトが返されます。実際のデータを取得するには、このCursorオブジェクトについてfetchall()メソッドを呼び出します。各レコードがタプルとして返され、そのタプルがリストになっています。各タプル中のデータはテーブルのカラム順になっています。
このタプルのリストから抽出するPythonのコードを自分で書くのではなく、SQLiteでほしい情報を抽出します。SELECTクエリには4つの部分があります。
- SELECTキーワード
- 取得するカラム(*はrowid以外のすべてのカラムという意味)
- FROMキーワード
- データを取得するテーブル(この例の場合はcatsテーブル)
catsテーブルのrowidカラムとnameカラムのレコードだけが必要なのであれば、次のようなクエリを書きます。
>>> conn.execute('SELECT rowid, name FROM cats').fetchall()
[(1, 'Zophie')]
次の節で説明するように、SQLでクエリの結果をフィルタリングすることもできます。
クエリ結果を反復処理する
fetchall()メソッドはSELECTクエリ結果をタプルのリストとして返します。このデータを使ってforループで各タプルに何らかの操作を行うというコードのパターンがよくあります。例えば、https://
>>> import sqlite3
>>> conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> for row in conn.execute('SELECT * FROM cats'):
... print('Row data:', row)
... print(row[0], 'is one of my favorite cats.')
...
Row data: ('Zophie', '2021-01-24', 'gray tabby', 5.6)
Zophie is one of my favorite cats.
Row data: ('Miguel', '2016-12-24', 'siamese', 6.2)
Miguel is one of my favorite cats.
Row data: ('Jacob', '2022-02-20', 'orange and white', 5.5)
Jacob is one of my favorite cats.
--snip--
forループはfetchall()を呼び出さずにconn.execute()が返す行のデータのタプルを反復処理します(訳注:fetchall()を呼び出すと一度すべての結果を取得するのに対し、呼び出さないと結果を逐次処理します)。forループ内のコードでは各行を処理します。変数rowにはクエリの結果のデータ行のタプルが入っているからです。タプルの整数のインデックスでカラムにアクセスできます。インデックス0は名前で、インデックス1は生年月日で、といった具合です。
取得したデータのフィルタリング
先ほどのSELECTクエリではテーブルのすべての行を取得しましたが、何らかのフィルタリング基準に沿って一部の行だけがほしいこともあるでしょう。sweigartcats.dbファイルで、WHERE節をSELECT文につけて検索条件を指定します。例えば毛色が黒のネコだけを取得してみましょう。
>>> import sqlite3
>>> conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> conn.execute('SELECT * FROM cats WHERE fur = "black"').fetchall()
[❶('Zophie', '2021-01-24', 'black', 5.6), ('Toby', '2021-05-17', 'black',
6.8), ('Thor', '2013-05-14', 'black', 5.2), ('Sassy', '2017-08-20', 'black',
7.5), ('Hope', '2016-05-22', 'black', 7.6)]
この例では、WHERE節のWHERE fur = "black"により、furカラムの値が"black"のレコードのみを取得します。
SQLiteはWHERE節で固有の演算子を使いますが、Pythonの演算子に似ています。=、!=、<、>、<=、>=、AND、OR、NOTです。SQLiteは「等しい」という意味で=演算子を使うことに注意してください。Pythonでは「等しい」という意味の演算子は==です。演算子のどちらの側にカラム名を置いてもリテラル値を置いても動作します。
比較はテーブルの各行について行われます。例えば、WHERE fur = "black"では、SQLiteが以下の比較を行います。
- 1行目ではfurが'black'であり、'black' = 'black'はtrueになりますから、SQLiteはこの❶の行を結果に含めます。
- 2行目では(2, 'Miguel', '2016-12-24', 'siamese', 6.2)のfurは'siamese'であり、'siamese' = 'black'はfalseになりますから、この行は結果に含まれません。
- 3行目では(3, 'Jacob', '2022-02-20', 'orange and white', 5.5)のfurは'orange and white'であり、'orange and white' = 'black'はfalseになりますから、この行は結果に含まれません。
catsテーブルのすべての行についてこのように比較します。
WHERE fur = "black" OR birthdate >= "2024-01-01"'という、もっと複雑なWHERE節の例を見てみましょう。pprint.pprint()関数を使って結果のリストをきれいに表示しましょう。
>>> import pprint
>>> matching_cats = conn.execute('SELECT * FROM cats WHERE fur = "black"
OR birthdate >= "2024-01-01"').fetchall()
>>> pprint.pprint(matching_cats)
[('Zophie', '2021-01-24', 'black', 5.6),
('Toby', '2021-05-17', 'black', 6.8),
('Taffy', '2024-12-09', 'white', 7.0),
('Hollie', '2024-08-07', 'calico', 6.0),
('Lewis', '2024-03-19', 'orange tabby', 5.1),
('Thor', '2013-05-14', 'black', 5.2),
('Shell', '2024-06-16', 'tortoiseshell', 6.5),
('Jasmine', '2024-09-05', 'orange tabby', 6.3),
('Sassy', '2017-08-20', 'black', 7.5),
('Hope', '2016-05-22', 'black', 7.6)]
結果のリストmatching_catsに含まれるネコは、毛色が黒か生年月日が2024年1月1日以降です。生年月日は文字列です。>=のような演算子の比較は文字列ではアルファベット順の比較になりますが、生年月日のフォーマットがYYYY-MM-DDであれば日付順の比較と同じになります。
LIKE演算子でパーセント記号(%)をワイルドカードとして使えば、値の先頭あるいは末尾にマッチさせられます。例えば、name LIKE "%y"は'y'で終わるすべての名前にマッチしますし、name LIKE "Ja%"は'Ja'で始まるすべての名前にマッチします。
>>> conn.execute('SELECT rowid, name FROM cats WHERE name LIKE "%y"').fetchall()
[(5, 'Toby'), (11, 'Molly'), (12, 'Dusty'), (17, 'Mandy'), (18, 'Taffy'), (25, 'Rocky'), (27,
'Bobby'), (30, 'Misty'), (34, 'Mitsy'), (38, 'Colby'), (40, 'Riley'), (46, 'Ruby'), (65,
'Daisy'), (67, 'Crosby'), (72, 'Harry'), (77, 'Sassy'), (85, 'Lily'), (93, 'Spunky')]
>>> conn.execute('SELECT rowid, name FROM cats WHERE name LIKE "Ja%"').fetchall()
[(3, 'Jacob'), (49, 'Java'), (75, 'Jasmine'), (80, 'Jamison')]
パーセント記号を文字列の先頭と末尾に置けば、部分一致になります。例えば、name LIKE "%ob%"は文字列中のどこかに'ob'があるすべての名前にマッチします。
>>> conn.execute('SELECT rowid, name FROM cats WHERE name LIKE "%ob%"').fetchall()
[(3, 'Jacob'), (5, 'Toby'), (27, 'Bobby')]
LIKE演算子は大文字と小文字を区別せずにマッチします。よって、name LIKE "%ob%"は'%OB%'、'%Ob%'、'%oB%'にもマッチします。大文字と小文字を区別してマッチさせるには、GLOB演算子と*をワイルドカードとして使います。
>>> conn.execute('SELECT rowid, name FROM cats WHERE name GLOB "*m*"').fetchall()
[(4, 'Gumdrop'), (9, 'Thomas'), (44, 'Sam'), (63, 'Cinnamon'), (75, 'Jasmine'),
(79, 'Samantha'), (80, 'Jamison')]
name LIKE "%m%"は大文字と小文字のmにマッチするのに対し、name GLOB "*m*"は小文字のmにしかマッチしません。
SQLiteの演算子は、プログラミング言語の演算子と同じくらい幅広いです。https://
結果の並べ替え
fetchall()で返されるリストにPythonのsort()メソッドを適用して並べ替えをすることができますが、SELECTクエリにORDER BY節をつけてSQLiteのデータの並べ替えをしたほうが簡単です。例えば、ネコを毛色で並べ替えたければ、以下のようにします。
>>> import sqlite3, pprint
>>> conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> pprint.pprint(conn.execute('SELECT * FROM cats ORDER BY fur').fetchall())
[('Iris', '2017-07-13', 'bengal', 6.8),
('Ruby', '2023-12-22', 'bengal', 5.0),
('Elton', '2020-05-28', 'bengal', 5.4),
('Toby', '2021-05-17', 'black', 6.8),
('Thor', '2013-05-14', 'black', 5.2),
--snip--
('Celine', '2015-04-18', 'white', 7.3),
('Daisy', '2019-03-19', 'white', 6.0)]
クエリにWHERE節があれば、ORDER BY節はそれより後に書きます。複数のカラムに基づいて並べ替えることもできます。例えば、まず毛色で並べ替えて、同じ毛色内では生年月日で並べ替えるなら、以下のように実行します。
>>> cur = conn.execute('SELECT * FROM cats ORDER BY fur, birthdate')
>>> pprint.pprint(cur.fetchall())
[('Iris', '2017-07-13', 'bengal', 6.8),
('Elton', '2020-05-28', 'bengal', 5.4),
('Ruby', '2023-12-22', 'bengal', 5.0),
('Thor', '2013-05-14', 'black', 5.2),
('Hope', '2016-05-22', 'black', 7.6),
--snip--
('Ginger', '2020-09-22', 'white', 5.8),
('Taffy', '2024-12-09', 'white', 7.0)]
ORDER BY節はfurカラムを先に書き、カンマで区切ってbirthdateカラムを続けて書きます。デフォルトでは、昇順で並べ替えられます。小さな値が先で大きな値が後に来ます。降順で並べ替えるには、カラム名の後にDESCキーワードをつけます。ASCキーワードをつけて昇順であることを明示してクエリを読みやすくすることもできます。これらのキーワードの練習として、対話型シェルで以下の内容を実行してみてください。
>>> cur = conn.execute('SELECT * FROM cats ORDER BY fur ASC, birthdate DESC')
>>> pprint.pprint(cur.fetchall())
[('Ruby', '2023-12-22', 'bengal', 5.0),
('Elton', '2020-05-28', 'bengal', 5.4),
('Iris', '2017-07-13', 'bengal', 6.8),
('Toby', '2021-05-17', 'black', 6.8),
('Sassy', '2017-08-20', 'black', 7.5),
--snip--
('Mitsy', '2015-05-29', 'white', 5.0),
('Celine', '2015-04-18', 'white', 7.3)]
毛色の昇順でネコの一覧を出力します('bengal'は'white'よりも前に来ます)。同じ毛色内では、生年月日の降順になります('2023-12-22'は'2020-05-28'よりも前に来ます)。
結果の数を限定する
SELECTクエリで返される最初の数行を確認したいだけであれば、Pythonのリストのスライスで結果の数を限定しようと考えるかもしれません。例えば、[:3]というスライスを使えば、catsテーブルの最初の3行だけを表示できます。
>>> import sqlite3
>>> conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> conn.execute('SELECT * FROM cats').fetchall()[:3] # これは非効率
[('Zophie', '2021-01-24', 'gray tabby', 5.6), ('Miguel', '2016-12-24',
'siamese', 6.2), ('Jacob', '2022-02-20', 'orange and white', 5.5)]
このコードは意図した通りに動きますが非効率です。まずテーブルからすべての行を取得し、次に最初の3行以外を捨てています。データベースから最初の3行だけを取得したほうがプログラムは速くなります。LIMIT節でそれができます。
>>> conn.execute('SELECT * FROM cats LIMIT 3').fetchall()
[('Zophie', '2021-01-24', 'gray tabby', 5.6), ('Miguel', '2016-12-24',
'siamese', 6.2), ('Jacob', '2022-02-20', 'orange and white', 5.5)]
このコードは、特に行数の多いテーブルに関しては、すべての行を取得するコードよりも実行が速いです。LIMIT節はWHERE節とORDER BY節よりも後に来ますので、SELECTクエリにそれらの節があるのであれば、次のように書きます。
>>> conn.execute('SELECT * FROM cats WHERE fur="orange" ORDER BY birthdate LIMIT 4').fetchall()
[('Mittens', '2013-07-03', 'orange', 7.4), ('Piers', '2014-07-08', 'orange', 5.2),
('Misty', '2016-07-08', 'orange', 5.2), ('Blaze', '2023-01-16', 'orange', 7.4)]
SELECTクエリにつけられる節はほかにもいくつかありますが、本章の範囲を超えます。それらについてはSQLiteのドキュメントで調べることができます。
データの読み取り速度を向上させるためにインデックスを作成する
前の節では、SELECTクエリを実行して名前のマッチに基づいてレコードを検索しました。nameカラムにインデックスを作成することでこの検索の速度を向上させられます。SQLのインデックスは、カラムのデータを整理するデータ構造です。これを利用すると、インデックスを作成したカラムについてWHERE節のあるクエリの実行速度が向上します。インデックスに少し容量が必要なのと、SQLiteがデータのインデックスも更新しないといけないのでデータの挿入と更新が少し遅くなるのが欠点です。データベースが大規模で、データの挿入や更新よりも読み取りの頻度が高ければ、インデックスを検討する価値があるでしょう。しかし、インデックスが実際に速度を向上させることをテストすべきです。
例えば、catsテーブルのnamesカラムとbirthdateカラムにインデックスを作成するなら、以下のCREATE INDEXクエリを実行します。
>>> import sqlite3
>>> conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> conn.execute('CREATE INDEX idx_name ON cats (name)')
<sqlite3.Cursor object at 0x0000013EC121A040>
>>> conn.execute('CREATE INDEX idx_birthdate ON cats (birthdate)')
<sqlite3.Cursor object at 0x0000013EC121A040>
インデックスには名前が必要で、慣習的に、適用するカラム名にidx_という接頭辞をつけます。インデックス名はデータベース全体でグローバルにアクセスできるので、データベースにbirthdateカラムのあるテーブルが複数あるなら、idx_cats_birthdateのように、テーブル名もインデックス名に含めたほうがよいでしょう。テーブルで作成されているすべてのインデックスを確認するには、組み込みのsqlite_schemaテーブルにSELECTクエリを実行します。
>>> conn.execute('SELECT name FROM sqlite_schema WHERE type = "index" AND
tbl_name = "cats"').fetchall()
[('idx_name',), ('idx_birthdate',)]
考えが変わったりインデックスが速度を向上させなかったりしたら、DROP INDEXクエリでインデックスを削除できます。
>>> conn.execute('SELECT name FROM sqlite_schema WHERE type = "index" AND
tbl_name = "cats"').fetchall()
[('idx_birthdate',), ('idx_name',)]
>>> conn.execute('DROP INDEX idx_name')
<sqlite3.Cursor object at 0x0000013EC121A040>
>>> conn.execute('SELECT name FROM sqlite_schema WHERE type = "index" AND
tbl_name = "cats"').fetchall()
[('idx_birthdate',)]
数千レコード程度の小さなデータベースであれば、インデックスを作成しても作成しなくても大差はないので、インデックスを気にしなくて構いません。しかし、データベースのクエリが気になるほど時間を要するなら、インデックスを作成すると速度が向上するかもしれません。
データベースのデータを更新する
テーブルに行を挿入したあとで、UPDATE文を実行すれば行を変更できます。例えば、sweigartcats.dbファイルの(1, 'Zophie', '2021-01-24', 'black', 5.6)のレコードの毛色を'black'から'gray tabby'に変更してみましょう。
>>> import sqlite3
>>> conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> conn.execute('SELECT * FROM cats WHERE rowid = 1').fetchall()
[('Zophie', '2021-01-24', 'black', 5.6)]
>>> conn.execute('UPDATE cats SET fur = "gray tabby" WHERE rowid = 1')
<sqlite3.Cursor object at 0x0000013EC121A040>
>>> conn.execute('SELECT * FROM cats WHERE rowid = 1').fetchall()
[('Zophie', '2021-01-24', 'gray tabby', 5.6)]
UPDATE文には以下の部分があります。
- UPDATEキーワード
- 更新する行を含むテーブル名
- 更新するカラムと値を指定するSET節
- 更新する行を指定するWHERE節
カンマで区切って指定すれば複数のカラムを一度に更新できます。例えば、'UPDATE cats SET fur = "black", weight_kg = 6 WHERE rowid = 1'というクエリは、furカラムの値を"black"に、weightカラムの値を6に更新します。
UPDATEクエリはWHERE節がtrueになるすべての行を更新します。'UPDATE cats SET fur = "gray tabby" WHERE name = "Zophie"'クエリを実行すると、Zophieという名前のすべてのネコについて更新が適用されます。意図していたよりも多く更新してしまう可能性があります。そのため、更新クエリでは、WHERE節で更新するレコードを一つだけ指定するために主キーのrowidカラムを使うことが多いです。主キーは行を一意に識別しますから、WHERE節でそれを使うと意図した行だけ更新することを保証できます。
WHERE節をつけ忘れてデータを更新してしまうというのはよくあるバグです。例えば、すべてのネコについて、毛色の'white and orange' を'orange and white'に置換したいとしたら、以下を実行します。
>>> conn.execute('UPDATE cats SET fur = "orange and white" WHERE fur = "white and orange"')このときWHERE節をつけ忘れたら、テーブルのすべての行に更新が適用され、突然すべてのネコの毛色が'orange and white'になってしまいます。
このバグを避けるために、すべての行に変更を適用したい場合であっても、UPDATEクエリには必ずWHERE節をつけるようにしてください。すべての行に変更を適用する場合は、WHERE 1とします。1はSQLiteでブール値のTrueを表しますから、すべての行に変更を適用するという意味になります。余計なWHERE 1をクエリの末尾につけるのはバカげているように見えるかもしれませんが、実データを簡単に消し去ってしまう危険なバグを避けるのに役立ちます。
データベースからデータを削除する
DELETEクエリでベーブルから行を削除できます。例えば、sweigartcats.dbファイルのcatsテーブルからZophieを削除するには、以下の内容を実行します。
>>> import sqlite3
>>> conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> conn.execute('SELECT rowid, * FROM cats WHERE rowid = 1').fetchall()
[(1, 'Zophie', '2021-01-24', 'gray tabby', 5.6)]
>>> conn.execute('DELETE FROM cats WHERE rowid = 1')
<sqlite3.Cursor object at 0x0000020322D183C0>
>>> conn.execute('SELECT * FROM cats WHERE rowid = 1').fetchall()
[]
DELETE文には以下の部分があります。
- DELETE FROMキーワード
- 削除する行を含むテーブル名
- 削除する行を指定するWHERE節
UPDATE文と同じように、DELETE文には必ずWHERE節をつけるようにしてください。そうでなければ、テーブルからすべての行を削除してしまいます。もしすべての行を削除したいなら、WHERE 1をつけてください。そうすれば、WHERE節のないDELETE文はバグだとわかりやすくなります。
トランザクションのロールバック
いくつかのクエリをまとめて実行するか全部実行しないかのどちらかにしたいことが時々あります。しかし、クエリを実行してみないと、そのどちらがいいのかわかりません。こうした状況に対応する一つの方法は、トランザクションを開始することです。クエリを実行し、すべてのクエリをデータベースにコミットしてトランザクションを完了させるか、ロールバックしてデータベースを何事もなかったかのような状態にするかのいずれかになります。
SQLiteデータベースに自動コミットモードで接続していれば、通常、1回のconn.execute()呼び出しごとにトランザクションを開始して終了します。しかし、BEGINクエリで新しいトランザクションを開始することもできます。そうすると、conn.commit()を呼び出してトランザクションを完了させるか、conn.rollback()を呼び出してすべてのクエリをなかったことにするかのいずれかになります。
例えば、catsテーブルに2匹の新しいネコを追加して、そのトランザクションをロールバックしてみます。そうすればテーブルは変更されないままです。
>>> import sqlite3
>>> conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> conn.execute('BEGIN')
<sqlite3.Cursor object at 0x00000219C8BF7C40>
>>> conn.execute('INSERT INTO cats VALUES ("Socks", "2022-04-04", "white", 4.2)')
<sqlite3.Cursor object at 0x00000219C8BF7C40>
>>> conn.execute('INSERT INTO cats VALUES ("Fluffy", "2022-10-30", "gray", 4.5)')
<sqlite3.Cursor object at 0x00000219C8BF7C40>
>>> conn.rollback() # これによりINSERT文がなかったことになる
>>> conn.execute('SELECT * FROM cats WHERE name = "Socks"').fetchall()
[]
>>> conn.execute('SELECT * FROM cats WHERE name = "Fluffy"').fetchall()
[]
新しいネコのSocksとFluffyは、データベースに挿入されていません。
反対に、実行したクエリをすべて適用したければ、conn.commit()を呼び出してデータベースに変更をコミットします。
>>> conn.execute('BEGIN')
<sqlite3.Cursor object at 0x00000219C8BF7C40>
>>> conn.execute('INSERT INTO cats VALUES ("Socks", "2022-04-04", "white", 4.2)')
<sqlite3.Cursor object at 0x00000219C8BF7C40>
>>> conn.execute('INSERT INTO cats VALUES ("Fluffy", "2022-10-30", "gray", 4.5)')
<sqlite3.Cursor object at 0x00000219C8BF7C40>
>>> conn.commit()
>>> conn.execute('SELECT * FROM cats WHERE name = "Socks"').fetchall()
[('Socks', '2022-04-04', 'white', 4.2)]
>>> conn.execute('SELECT * FROM cats WHERE name = "Fluffy"').fetchall()
[('Fluffy', '2022-10-30', 'gray', 4.5)]
SocksとFluffyのネコはデータベースのレコードに存在します。
データベースのバックアップ
ある私の友人が、収集用のスポーツカードを専門に扱っているECサイトで使っているデータベースに変更を加えようとしていました。いくつかのカードに含まれる誤りを訂正しなければならず、UPDATE cards SET name = 'Chris Clemons'と入力したところで、その友人のネコがキーボートの上に乗り、ENTERキーを押しました。WHERE節がなかったので、このクエリはウェブサイトで販売中の数千枚のカードすべてを更新してしまいました。
幸い、その友人はデータベースのバックアップを取得していたので、以前の状態に復元することができました。(バックアップを取得していて本当によかったです。というのも、同じことが再び起こりました。そのネコはわざとやっているのでしょう。)
プログラムが現在SQLiteデータベースに接続していなければ、データベースファイルを単純にコピーするだけでバックアップを取得できます。Pythonプログラムでは、第11章で説明したように、shutil.copy('sweigartcats.db', 'backup.db')を呼び出せばファイルをコピーできます。しかし、ソフトウェアから絶えずデータベースの内容を読み書きしているなら、(単純にファイルをコピーするというわけにはいかないので)Connectionオブジェクトのbackup()メソッドを使う必要があります。対話型シェルで次のように入力してみてください。
>>> import sqlite3
>>> conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> backup_conn = sqlite3.connect('backup.db', isolation_level=None)
>>> conn.backup(backup_conn)
backup()メソッドは、他のクエリが実行中であっても、sweigartcats.dbデータベースの内容をbackup.dbファイルへと安全にバックアップします。これでデータを安全にバックアップできましたから、ネコが好きなだけキーボートの上に乗ることができます。
テーブルの変更と削除
データベースにテーブルを作成して行を挿入してから、テーブル名やカラム名を変更したくなることがあるかもしれません。テーブルのカラムの追加や削除、あるいはテーブル全体を削除したい場合もあるでしょう。ALTER TABLEクエリを実行すればこれらの操作ができます。
以下の対話型シェルの例では、sweigartcats.dbデータベースファイルの最初の状態から始めます。ALTER TABLE RENAMEクエリを実行して、テーブル名をcatsからfelinesに変更します。
>>> import sqlite3
>>> conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> conn.execute('SELECT name FROM sqlite_schema WHERE type="table"').fetchall()
[('cats',)]
>>> conn.execute('ALTER TABLE cats RENAME TO felines') # テーブル名の変更
<sqlite3.Cursor object at 0x000001EDDB477C40>
>>> conn.execute('SELECT name FROM sqlite_schema WHERE type="table"').fetchall()
[('felines',)]
テーブル内のカラム名を変更するには、ALTER TABLE RENAME COLUMNクエリを実行します。例えば、カラム名をfurからdescriptionに変更してみましょう。
>>> conn.execute('PRAGMA TABLE_INFO(felines)').fetchall()[2] # 3番目のカラムを表示
(2, 'fur', 'TEXT', 0, None, 0)
>>> conn.execute('ALTER TABLE felines RENAME COLUMN fur TO description')
<sqlite3.Cursor object at 0x000001EDDB477C40>
>>> conn.execute('PRAGMA TABLE_INFO(felines)').fetchall()[2] # 3番目のカラムを表示
(2, 'description', 'TEXT', 0, None, 0)
テーブルに新しいカラムを追加するには、ALTER TABLE ADD COLUMNクエリを実行します。例えば、felinesテーブルに、ブール値が入るis_lovedカラムを新しく追加してみます。SQLiteでは、0がfalseを、1がtrueを表します。is_lovedのデフォルト値は1にします。
>>> conn.execute('ALTER TABLE felines ADD COLUMN is_loved INTEGER DEFAULT 1')
<sqlite3.Cursor object at 0x000001EDDB477C40>
>>> import pprint
>>> pprint.pprint(conn.execute('SELECT * FROM felines LIMIT 3').fetchall())
[('Zophie', '2021-01-24', 'gray tabby', 5.6, 1),
('Miguel', '2016-12-24', 'siamese', 6.2, 1),
('Jacob', '2022-02-20', 'orange and white', 5.5, 1)]
私はどのネコについても1を保存するので、is_lovedカラムは不要だとわかりました。そこで、ALTER TABLE DROP COLUMNクエリでこのカラムを削除します。
>>> conn.execute('PRAGMA TABLE_INFO(felines)').fetchall() # すべてのカラムを表示
[(0, 'name', 'TEXT', 1, None, 0), (1, 'birthdate', 'TEXT', 0, None, 0), (2, 'description', 'TEXT',
0, None, 0), (3, 'weight_kg', 'REAL', 0, None, 0), (4, 'is_loved', 'INTEGER', 0, '1', 0)]
>>> conn.execute('ALTER TABLE felines DROP COLUMN is_loved') # カラムの削除
<sqlite3.Cursor object at 0x000001EDDB477C40>
>>> conn.execute('PRAGMA TABLE_INFO(felines)').fetchall() # すべてのカラムを表示
[(0, 'name', 'TEXT', 1, None, 0), (1, 'birthdate', 'TEXT', 0, None, 0), (2, 'description', 'TEXT',
0, None, 0), (3, 'weight_kg', 'REAL', 0, None, 0)]
削除されるカラムに保存されているデータはすべて削除されます。
テーブル全体を削除したければ、DROP TABLEクエリを実行します。
>>> conn.execute('SELECT name FROM sqlite_schema WHERE type="table"').fetchall()
[('felines',)]
>>> conn.execute('DROP TABLE felines') # テーブル全体を削除
<sqlite3.Cursor object at 0x000001EDDB477C40>
>>> conn.execute('SELECT name FROM sqlite_schema WHERE type="table"').fetchall()
[]
テーブルやカラムの変更は控えめにしてください。これらを変更すると、対応するプログラムのクエリも変更しなければならないからです。
外部キーで複数のテーブルを結合する
SQLiteのテーブル構造はかなり厳格です。例えば、それぞれの行についてカラムの数が定まっています。しかし、現実世界のデータは一つのテーブルに収まるほと単純ではないことがしばしばあります。リレーショナルデータベースでは、複雑なデータを複数のテーブルに保存し、外部キーでテーブルを結合します。
ネコが接種したワクチンの情報を保存したいとしましょう。ネコが接種するワクチンは複数になる可能性があるので、catsテーブルにカラムを追加するわけにはいきません。さらに、ワクチンの接種ごとに、接種日と担当医師をリスト化したいです。SQLのテーブルはカラムのリストを保存するのに適していません。vaccination1、vaccination2、vaccination3といった名前のカラムを作りたくないです。vaccination1、vaccination2といった名前の変数を作りたくないのと同じです。カラムや変数を作りすぎると、コードが冗長になり、散らかって読みにくくなってしまいます。逆にこの要領で最初に用意するカラムが少なすぎると、必要に応じて追加するときにプログラムを更新しなければならなくなります。
一つの行に追加するデータの量が変わる場合は、別のテーブルの行にデータを追加するのが理に適っています。そうすれば、別テーブルの行を元のメインとなるテーブルの行から参照できます。sweigartcats.dbデータベースで、対話型シェルで以下の内容を入力して、vaccinationsという2つ目のテーブルを追加してください。
>>> import sqlite3
>>> conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> conn.execute('PRAGMA foreign_keys = ON')
<sqlite3.Cursor object at 0x000001E730AD03C0>
>>> conn.execute('CREATE TABLE IF NOT EXISTS vaccinations (vaccine TEXT,
date_administered TEXT, administered_by TEXT, cat_id INTEGER,
FOREIGN KEY(cat_id) REFERENCES cats(rowid)) STRICT')
<sqlite3.Cursor object at 0x000001CA42767D40>
新しいvaccinationsテーブルには、INTEGER型のcat_idという名前のカラムがあります。このカラムの整数値はcatsテーブルの行のrowidの値に対応します。別のテーブルの主キーを参照するので、cat_idカラムを外部キーと呼びます。
catsテーブルでは、ネコのZophieのrowidは1です。そのネコのワクチンを記録するには、vaccinationsテーブルにcat_idの値が1の行を挿入します。
>>> conn.execute('INSERT INTO vaccinations VALUES ("rabies", "2023-06-06", "Dr. Echo", 1)')
<sqlite3.Cursor object at 0x000001CA42767D40>
>>> conn.execute('INSERT INTO vaccinations VALUES ("FeLV", "2023-06-06", "Dr. Echo", 1)')
<sqlite3.Cursor object at 0x000001CA42767D40>
>>> conn.execute('SELECT * FROM vaccinations').fetchall()
[('rabies', '2023-06-06', 'Dr. Echo', 1), ('FeLV', '2023-06-06', 'Dr. Echo', 1)]
他のネコについてもrowidを使ってワクチンの記録ができます。Mangoのワクチン記録を追加するなら、catsテーブルのMangoのrowidを探し、その値をvaccinationsテーブルのcat_idカラムに入れてレコードを追加します。
>>> conn.execute('SELECT rowid, * FROM cats WHERE name = "Mango"').fetchall()
[(23, 'Mango', '2017-02-12', 'tuxedo', 6.8)]
>>> conn.execute('INSERT INTO vaccinations VALUES ("rabies", "2023-07-11", "Dr. Echo", 23)')
<sqlite3.Cursor object at 0x000001CA42767D40>
inner join(内部結合)と呼ばれるSELECTクエリを実行して、両方のテーブルの行を結合した結果を得ることができます。例えば、対話型シェルに以下の内容を入力して、catsテーブルのデータとvaccinationsの行を結合した結果を取得してみてください。
>>> conn.execute('SELECT * FROM cats INNER JOIN vaccinations ON cats.rowid =
vaccinations.cat_id').fetchall()
[('Zophie', '2021-01-24', 'gray tabby', 5.6, 'rabies', '2023-06-06', 'Dr. Echo', 1),
('Zophie', '2021-01-24', 'gray tabby', 5.6, 'FeLV', '2023-06-06', 'Dr. Echo', 1),
('Mango', '2017-02-12', 'tuxedo', 6.8, 'rabies', '2023-07-11', 'Dr. Echo', 23)]
cat_idをINTEGER型のカラムにしてFOREIGN KEY(cat_id) REFERENCES cats(rowid)構文を使わずに外部キーとして利用することも可能ではありますが、構文を使った外部キーにはデータの整合性を保つための安全装置が組み込まれています。例えば、存在しないネコのcat_idを使ったワクチンレコードの挿入や更新はできません。「孤立した」ワクチンレコードを残してしまわないように、SQLiteでは(catsテーブルの)ネコを削除する前にそのネコのワクチンレコードをすべて削除することが強制されます。
こうした安全装置はデフォルトで無効になっています。sqlite3.connect()呼び出しのあとでPRAGMAクエリを実行すると有効にできます。
>>> conn.execute('PRAGMA foreign_keys = ON')外部キーと結合にはさらに発展的な機能がありますが、本書での説明はこれくらいにします。
インメモリデータベースとバックアップ
プログラムから多数のクエリを実行するのであれば、インメモリデータベースを利用するとデータベースの速度を劇的に向上させられる可能性があります。インメモリデータベースは、コンピュータのハードドライブ上のファイルではなく、すべてメモリ上に保存されます。そのおかげで変更がとても高速になります。しかし、backup()メソッドでインメモリデータベースをファイルに保存することを忘れないようにしなければなりません。プログラムが実行中にクラッシュすれば、プログラムの変数に格納された値を失ってしまうのと同じように、インメモリデータベース全体を失ってしまいます。
以下の例では、インメモリデータベースを作成し、test.dbというファイルにデータベースを保存します。
>>> import sqlite3
>>> memory_db_conn = sqlite3.connect(':memory:',
isolation_level=None) # インメモリデータベースを作成
>>> memory_db_conn.execute('CREATE TABLE test (name TEXT, number REAL)')
<sqlite3.Cursor object at 0x000001E730AD0340>
>>> memory_db_conn.execute('INSERT INTO test VALUES ("foo", 3.14)')
<sqlite3.Cursor object at 0x000001D9B0A07EC0>
>>> file_db_conn = sqlite3.connect('test.db', isolation_level=None)
>>> memory_db_conn.backup(file_db_conn) # データベースをtest.dbファイルに保存
SQLiteデータベースファイルのロードも同様にbackup()メソッドで行います。
>>> import sqlite3
>>> file_db_conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> memory_db_conn = sqlite3.connect(':memory:', isolation_level=None)
>>> file_db_conn.backup(memory_db_conn)
>>> memory_db_conn.execute('SELECT * FROM cats LIMIT 3').fetchall()
[('Zophie', '2021-01-24', 'gray tabby', 5.6), ('Miguel', '2016-12-24',
'siamese', 6.2), ('Jacob', '2022-02-20', 'orange and white', 5.5)]
インメモリデータベースには欠点があります。例外を処理せずにプログラムがクラッシュすると、データベースを失ってしまいます。try文でコードを囲んで例外を捕捉し、except文でデータベースをファイルに保存することにより、そのリスクを緩和できます。第4章でtry文とexcept文による例外処理を説明しました。
データベースを複製する
Connectionオブジェクトについてiterdump()メソッドを呼び出すと、データベースの複製を取得できます。このメソッドは、データベースを再作成するのに必要なSQLiteのクエリのテキストを生成するイテレータを返します。イテレーターをforループで使うかlist()関数に渡して文字列のリストに変換します。例えば、sweigartcats.dbデータベースを再作成するのに必要なSQLiteのクエリを取得するには、対話型シェルで以下の内容を入力します。
>>> import sqlite3
>>> conn = sqlite3.connect('sweigartcats.db', isolation_level=None)
>>> with open('sweigartcats-queries.txt', 'w', encoding='utf-8') as fileObj:
... for line in conn.iterdump():
... fileObj.write(line + '\n')
このコードを実行すると、データベースを再作成する以下のSQLiteクエリが書かれたsweigartcats-queries.txtファイルが作成されます。
BEGIN TRANSACTION;
CREATE TABLE "cats" (name TEXT NOT NULL, birthdate TEXT, fur TEXT, weight_kg REAL) STRICT;
INSERT INTO "cats" VALUES('Zophie','2021-01-24','gray tabby',5.6);
INSERT INTO "cats" VALUES('Miguel','2016-12-24','siamese',6.2);
INSERT INTO "cats" VALUES('Jacob','2022-02-20','orange and white',5.5);
--snip--
INSERT INTO "cats" VALUES('Spunky','2015-09-04','gray',5.9);
INSERT INTO "cats" VALUES('Shadow','2021-01-18','calico',6.0);
COMMIT;
このクエリのテキストは、まず間違いなく、元のデータベースよりもサイズが大きくなります。他方で、人間にとって読みやすく、PythonのコードやSQLiteアプリ(次に説明します)で複製する前に、簡単に編集できるという利点があります。
SQLiteアプリ
データベースとは本質的には関係のないPythonのコードを書かずに、SQLiteデータベースを直接調べたいことがあるかもしれません。そのためには、sqlite3コマンドをインストールして、ターミナルコマンドラインウィンドウから実行します。https://
Windowsでは、https://
次に、ターミナルウィンドウで、sqlite3 example.dbを実行してexample.dbのデータベースに接続します。このファイルが存在しなければ、sqlite3は空のデータベースでこのファイルを作成します。それから、SQLクエリを入力します。Pythonのconn.execute()に渡したクエリとは異なり、末尾にセミコロンをつけなければなりません。
例えば、ターミナルウィンドウで以下の内容を入力してください。
C:\Users\Al>sqlite3 example.db
SQLite version 3.xx.xx
Enter ".help" for usage hints.
sqlite> CREATE TABLE IF NOT EXISTS cats (name TEXT NOT NULL,
birthdate TEXT, fur TEXT, weight_kg REAL) STRICT;
sqlite> INSERT INTO cats VALUES ('Zophie', '2021-01-24', 'gray tabby', 4.7);
sqlite> SELECT * from cats;
Zophie|2021-01-24|gray tabby|4.7
この例からわかるように、sqlite3コマンドラインツールは一種のSQLite対話型シェルを提供し、そのsqlite>プロンプトでクエリを入力します。.helpコマンドで、.tables(データベースのテーブルを表示する)や.headers(カラムヘッダーのオン/オフを切り替える)などの、さらなるコマンドが表示されます。
sqlite> .tables
cats
sqlite> .headers on
sqlite> SELECT * from cats;
name|birthdate|fur|weight_kg
Zophie|2021-01-24|gray tabby|4.7
コマンドラインツールが不親切だと思われるなら、SQLiteデータベースをGUIで表示するフリーでオープンソースのアプリもあります。Windows、macOS、Linuxで使えます。
- DB Browser for SQLite (https://
sqlitebrowser .org) - SQLite Studio (https://
sqlitestudio .pl) - DBeaver Community (https://
dbeaver .io)
これらのGUIアプリはSQLiteデータベースを扱いやすくしてくれますが、テキストベースのSQLiteクエリの構文を学ぶことには意義があります。
まとめ
コンピュータでは大量のデータを扱えますが、データをテキストファイルやスプレッドシートに保存すると、構造化が不十分です。SQLiteなどのSQLデータベースを活用すると、大量の情報を効率的に保存できるだけでなく、SQL言語で必要なデータを正確に取得できます。
SQLiteは素晴らしいデータベースで、sqlite3モジュールがPythonの標準ライブラリに同梱されています。SQLiteのSQLには他のリレーショナルデータベースで用いられるSQLと異なる点が多少あるもののほぼ同じなので、SQLiteの学習はデータベース一般へのいい導入になります。
SQLiteデータベースは専用のサーバーが不要で、一つのファイルに保存されます。複数のテーブルが含まれ(テーブルはスプレッドシートになぞらえられます)、各テーブルには複数のカラムがあります。INSERT、SELECT、UPDATE、DELETEのクエリでCRUD(Create、Read、Update、Delete)操作を行い、テーブルの値を編集します。ALTER TABLEとDROP TABLEのクエリでテーブルやカラム自体を変更できます。外部キーという仕組みで複数テーブルのレコードを結合できます。
SQLiteやデータベースについては、1つの章で説明できないほどたくさんの事柄があります。SQLデータベース一般についてもっと知りたければ、Anthony DeBarrosのPractical SQL, 2nd edition (No Starch Press, 2022)をおすすめします。
練習問題
1. example.dbという名前のファイルのSQLデータベースについてConnectionオブジェクトを取得するPythonのコードを書いてください。
2. studentsという名前のテーブルに、first_name、last_name、favorite_colorという名前のTEXT型のカラムを作成するPythonのコードを書いてください。
3. 自動コミットモードでSQLiteデータベースに接続する方法を教えてください。
4. SQLiteでINTEGER型のデータとREAL型のデータはどう違いますか?
5. 厳格モードを設定するとテーブルはどうなりますか?
6. 'SELECT * FROM cats'というクエリ中の*はどういう意味ですか?
7. CRUDは何の略ですか?
8. ACIDは何の略ですか?
9. テーブルに新しいレコードを追加するクエリは何ですか?
10. テーブルからレコードを削除するクエリは何ですか?
11. UPDATEクエリでWHERE節を指定しないとどうなりますか?
12. インデックスとは何ですか? catsという名前のテーブルのbirthdateという名前のカラムにインデックスを作成するコードはどのように書きますか?
13. 外部キーとは何ですか?
14. catsという名前のテーブルを削除するコードを書いてください。
15. インメモリデータベースを作成する際に「ファイル名」をどう指定しますか?
16. データベースを複製する方法を教えてください。
練習プログラム
以下の練習プログラムを書いてください。
ネコのワクチン接種チェック
https://
食材データベース
食事と材料の2つのテーブルを作成するプログラムを書きます。以下のSQLクエリを使ってください。
CREATE TABLE IF NOT EXISTS meals (name TEXT) STRICT
CREATE TABLE IF NOT EXISTS ingredients (name TEXT,
meal_id INTEGER, FOREIGN KEY(meal_id) REFERENCES meals
(rowid)) STRICT
ユーザーに入力を求めるプログラムを書きます。ユーザーが'quit'と入力すると、プログラムは終了します。ユーザーは、'meal:ingredient1,ingredient2'のように、食事の名前のあとにコロンで区切って材料を入力することができます。そうするとその食事と材料をmealsテーブルとingredientsテーブルに保存します。
ユーザーは、食事の名前ないし材料の名前を入力することもできます。mealsテーブルにその名前が存在すれば、プログラムはその食事の材料を出力します。ingredientsテーブルにその名前が存在すれば、プログラムはその材料を使う食事を出力します。例えば、このプログラムの出力は以下のようになります。
> onigiri:rice,nori,salt,sesame seeds
Meal added: onigiri
> chicken and rice:chicken,rice,cream of chicken soup
Meal added: chicken and rice
> onigiri
Ingredients of onigiri:
rice
nori
salt
sesame seeds
> chicken
Meals that use chicken:
chicken and rice
> rice
Meals that use rice:
onigiri
chicken and rice
> quit