15 Googleスプレッドシート

Googleスプレッドシートは、GoogleアカウントかGmailアドレスを持っていたら誰でも無料で使える、ウェブベースのスプレッドシートアプリケーションです。機能が豊富で便利であり、Excelのライバルと言えます。Googleスプレッドシートには独自のAPIがありますが、このAPIはややこしくて使いにくいです。本章では、EZSheetsというサードパーティのライブラリを紹介します。このライブラリでは、一般的な操作が簡単にできるようにGoogleスプレッドシートAPIの細かい部分を処理してくれるので、自分でそのAPIの使い方を調べなくてもすみます。
EZSheetsのインストールと設定
EZSheetsは、付録Aの指示に沿ってpipコマンドラインツールでインストールできます。
PythonスクリプトからEZSheetsでGoogleスプレッドシートにアクセスして編集するには、事前に認証情報JSONファイルと2つのトークンJSONファイルを用意する必要があります。認証情報を作成するには以下の5つの手順を進めます。
1. 新しいGoogle Cloudプロジェクトを作成する
2. プロジェクトでGoogle Sheets APIとGoogle Drive APIを有効化する
3. OAuth同意画面を設定する
4. 認証情報を作成する
5. 認証情報ファイルでログインする
これは大変そうに見えるかもしれませんが、一度このセットアップをすると、あとは自由に使えます。Google/Gmailのアカウントが必要になります。Pythonスクリプトのバグがお持ちのスプレッドシートに悪影響を及ぼさないように、既存のアカウントを使うのではなく、新しいGoogleアカウントを作成することを強くおすすめします。本章を通して、「自分のGoogleアカウント」や「自分のGmailアドレス」で、Pythonスクリプトによりアクセスするスプレッドシートを所有しているGoogleアカウントを指します。
GoogleはGoogle Cloudコンソールのレイアウトや言い回しを変更する可能性がありますが、ここで説明する基本的な手順は変わらないはずです。(訳注:以下の説明では、訳出時の日本語版の画面に従って原文を訳し変えています。)
新しいGoogle Cloudプロジェクトを作成する
まず、Google Cloudプロジェクトを作成する必要があります。ブラウザでhttps://
Google Cloudでは、“My Project 23135”のようなプロジェクト名と“macro-nuance-362516”のようなプロジェクトIDが作成されます。これらの名前はPythonスクリプトを使うときに見えませんが、プロジェクト名は好きなように変更できます(プロジェクトIDは変更できません)。私はウェブサイトが作成したデフォルトの名前をそのまま使います。場所は「組織なし」のままで構いません。無料のGoogleアカウントが作成できるプロジェクトは12個までですが、本書のすべてのPythonスクリプトに1つのプロジェクトで対応できます。青色の「作成」ボタンをクリックしてプロジェクトを作成してください。
Google Sheets APIとGoogle Drive APIを有効化する
https://
下にスクロールしてGoogle Sheets APIを探してクリックするか、検索バーにGoogle Sheets APIと入力して見つけます。Google Sheets APIのページに移動するので、青色の「有効にする」ボタンをクリックしてGoogle CloudプロジェクトでGoogle Sheets APIを使えるようにします。APIとサービスAPI / サービスの詳細ページにリダイレクトされ、そこでこのAPIの使用頻度の情報を確かめられます。Google Drive APIについても同じ手順で有効にしてください。
次に、このプロジェクトのOAuth同意画面を設定します。
OAuth同意画面を設定する
import ezsheetsの初回実行時にOAuth同意画面が表示されます。左上のナビゲーションメニューボタンから「OAuth同意画」をクリックして、青色の「開始」ボタンを押してください。OAuth同意画面の第一段階のアプリ情報では、アプリ名(私は“Python Google API Script”のような一般的な名前にしています)と、ユーザーサポートメールにメールアドレスを入力し、「次へ」ボタンを押します。 第二段階の対象では、外部を選んで「次へ」ボタンを押します。 第三段階の連絡先情報では、自分のメールアドレスを入力して、「次へ」ボタンを押します。 第四段階の終了では、Google API サービス: ユーザーデータに関するポリシーに同意しますというチェックボックスにチェックを入れて、「続行」ボタンを押します。 最後に青色の「作成」ボタンをクリックします。
次に、このプロジェクトのスコープ、すなわちプロジェクトがどのリソースを使えるかの権限を定義します。左サイドバーの「データアクセス」をクリックして、「スコープを追加または削除」ボタンを押します。新しいパネルが表示されるので、.../auth/drive (the Google Drive API)と.../auth/spreadsheets (the Google Sheets API)のチェックボックスにチェックを入れます。それから青色の「更新」ボタンをクリックして、「Save」ボタンをクリックします。
最後に、対象ページで、Pythonのスクリプトから操作するスプレッドシートを所有しているGoogleアカウントのGmailアドレスを追加します。Googleのアプリ承認プロセスを通過しなければ、スクリプトが操作できるのはここでメールアドレスを追加したものに限られます。左サイドバーの対象をクリックして、「Add users」ボタンを押します。新しく表示されるパネルで自分のGoogleアカウントのGmailアドレスを入力し、青色の「保存」ボタンをクリックします。
認証情報を作成する
認証情報ファイルを作成する必要があります。EZSheetsがGoogleのAPIを利用するにはこの認証情報ファイルが必要です。誰でも見られる公開状態で共有されているスプレッドシートであってもそうです。左上のナビゲーションメニューボタンからAPIとサービス、認証情報とたどると、認証情報のページに移動します。画面上部の「認証情報を作成」リンクをクリックします。APIキー、OAuthクライアントID、サービスアカウントのうちどの種類の認証情報を作成するかを尋ねるサブメニューが表示されるので、OAuthクライアントIDをクリックします。
次のページでは、アプリケーションの種類でデスクトップアプリを選び、名前はデフォルトのデスクトップ クライアント: 1のままにします。お望みなら別の名前に変更できます。この名前はPythonスクリプトで表示されません。青色の「作成」ボタンをクリックします。
ポップアップウィンドウが表示されます。JSONをダウンロードをクリックして認証情報ファイルをダウンロードします。client_secret_282792235794-p2o9gfcub4htibfg2u207gcomco9nqm7.apps.googleusercontent.com.jsonのような名前のファイルです。このファイルをPythonスクリプトと同じフォルダ内に置きます。credentials-sheets.jsonといったシンプルな名前に変更してもよいです。EZSheetsは、credentials-sheets.jsonという名前のファイルか、client_secret_*.jsonという形の名前のファイルを探します。
認証情報ファイルでログインする
認証情報JSONファイルと同じフォルダでPythonの対話型シェルを実行し、import ezsheetsを実行してください。EZSheetsは自動的にezsheets.init() 関数を呼び出し、現在の作業フォルダを確認して、認証情報JSONファイルを探します。ファイルが見つかれば、EZSheetsはウェブブラウザを立ち上げてOAuth同意画面を表示し、トークンファイルを作成します。EZSheetsは、スプレッドシートにアクセスするのに、認証情報JSONファイルに加えて、token-drive.pickleとtoken-sheets.pickleという名前のこれらのトークンファイルも必要とします。トークンファイルの作成は一度だけで、次にimport ezsheetsを実行したときには新しくトークンファイルが作成されることはありません。
(ブラウザでOAuth同意画面が表示されたら)自分のGoogleアカウントでサインインします。Google CloudプロジェクトのOAuth同意画面でテストユーザーに追加したのと同じメールアドレスでサインインしてください。「このアプリは Googleで確認されていません」という警告メッセージが表示されますが、自分が作成したアプリですから、気にしないでください。「続行」をクリックします。「Python Google API Script が Google アカウントへのアクセスを求めています」のように書かれている別のページに移動するはずですから(OAuth同意画面で入力したアプリ名が表示されます)、「続行」をクリックします。「The authentication flow has completed. You may close this window.」とだけ書かれたページが表示されます。もうブラウザウィンドウを閉じても構いません。
Sheets APIの認証フローが完了したら、次に開くウィンドウでDrive APIの同じ認証フローを繰り返します。2回目のウィンドウを閉じると、token-drive.pickleとtoken-sheets.pickleファイルが同じフォルダにあるはずです。これらのファイルはパスワードと同じように扱い、共有しないでください。これらのファイルを使ってログインしてGoogleスプレッドシートにアクセスできてしまいます。
認証情報ファイルを失効させる
認証情報ファイルまたはトークンファイルを共有してしまったら、そのファイルを入手した人が、Googleアカウント本体のパスワードの変更はできないとしても、スプレッドシートにアクセスできてしまいます。https://
スプレッドシートオブジェクト
Googleスプレッドシートでは、スプレッドシートは複数のシート(ワークシート)を含み、それぞれのシートにはセルの行と列があります。セルには数値、日付、テキストなどのデータを入れます。セルには、フォント、幅、高さ、背景色などのプロパティもあります。図15-1は、BooksとWebsitesの2つのシートがあるSweigart Booksという名前のスプレッドシートを示しています。https://
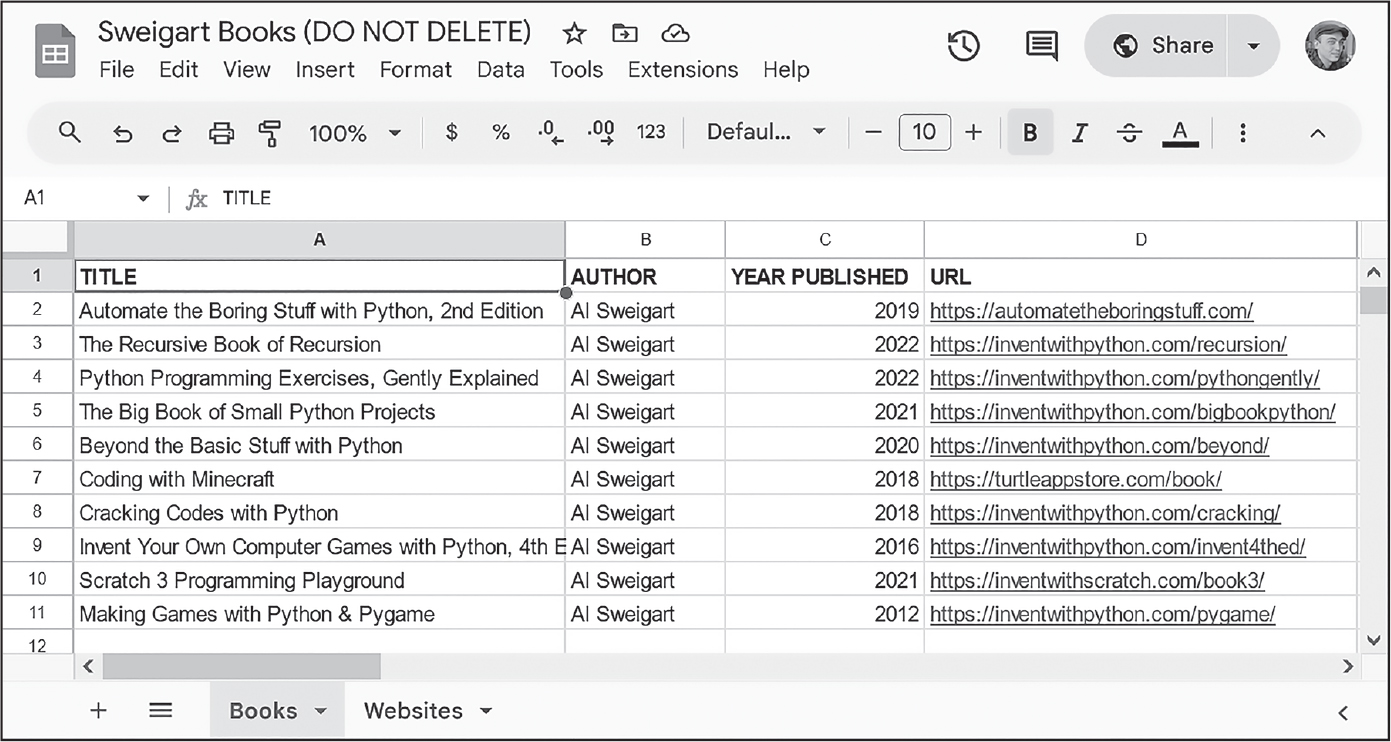
図 15-1:BooksとWebsitesの2つのシートがあるSweigart Booksという名前のスプレッドシート
大部分の作業はSheetオブジェクトを変更することになるでしょうが、次の節で見るようにSpreadsheetオブジェクトを変更することもできます。
スプレッドシートの作成、更新、一覧表示
既存のGoogleスプレッドシートからでも、新しい空白のスプレッドシートからでも、アップロードしたExcelファイルからでも、新しいSpreadsheetオブジェクトを作成できます。すべてのGoogleスプレッドシートには固有のIDがあり、URL中のspreadsheets/d/の後で/editの前の部分に含まれています。例えば、https://
Googleスプレッドシートはezsheets.Spreadsheetオブジェクトで表されます。id、url、titleの属性があります。Spreadsheet()関数で新しい空白のスプレッドシートを作成できます。
>>> import ezsheets
>>> ss = ezsheets.Spreadsheet()
>>> ss.title = 'Title of My New Spreadsheet'
>>> ss.title
'Title of My New Spreadsheet'
>>> ss.url
'https://docs.google.com/spreadsheets/d/1gxz-Qr2-RNtqi_d7wWlsDlbtPLRQigcEXvCtdVwmH40/'
>>> ss.id
'1gxz-Qr2-RNtqi_d7wWlsDlbtPLRQigcEXvCtdVwmH40'
IDまたはURL(スプレッドシートのURLにリダイレクトするURLも可)を渡すことで、既存のスプレッドシートをロードすることもできます。
>>> import ezsheets
>>> ss1 = ezsheets.Spreadsheet('https://autbor.com/examplegs')
>>> ss2 = ezsheets.Spreadsheet('https://docs.google.com/spreadsheets/d/1TzOJxh
NKr15tzdZxTqtQ3EmDP6em_elnbtmZIcyu8vI/')
>>> ss3 = ezsheets.Spreadsheet('1TzOJxhNKr15tzdZxTqtQ3EmDP6em_elnbtmZIcyu8vI')
>>> ss1 == ss2 == ss3 # これらは同じスプレッドシート
True
既存のExcel、OpenOffice、CSV、TSVファイルをスプレッドシートにアップロードするには、ファイル名をezsheets.upload()に渡します。対話型シェルに以下の内容を入力してください。my_spreadsheet.xlsxの部分はご自身のExcelファイルに置き換えてください。
>>> import ezsheets
>>> ss = ezsheets.upload('my_spreadsheet.xlsx')
>>> ss.title
'my_spreadsheet'
listSpreadsheets()関数を呼び出せば、自分のGoogleアカウントのスプレッドシートを一覧表示できます。この関数は、キーがスプレッドシートID、値がスプレッドシート名の辞書を返します。ゴミ箱フォルダにある削除されたスプレッドシートも含まれます。スプレッドシートをアップロードしてから、対話型シェルで以下の内容を実行してください。
>>> ezsheets.listSpreadsheets()
{'1J-Jx6Ne2K_vqI9J2SO-TAXOFbxx_9tUjwnkPC22LjeU': 'Education Data'}
Spreadsheetオブジェクトを取得できたら、その属性やメソッドを通じて、Googleがホストしているオンラインのスプレッドシートを操作できます。
スプレッドシートの属性にアクセスする
実際のデータはスプレッドシートの各シートに存在しますが、Spreadsheetオブジェクトにはスプレッドシート自体を操作できる、title、id、url、sheetTitles、sheetsという属性があります。https://
>>> import ezsheets
>>> example_ss = ezsheets.Spreadsheet('https://autbor.com/examplegs')
>>> ss = ezsheets.Spreadsheet()
>>> example_ss.sheets[0].copyTo(ss)
>>> ss.sheets[0].delete() # Sheet1シートを削除
>>> ss.url
'https://docs.google.com/spreadsheets/d/15gjrbgTmUzItRt9KUcL4JajLaQU70xanstB1dXKoSlM/'
新しくコピーされたシートは、Booksという元のシート名から、Copy of Booksというシート名になります。対話型シェルで以下のコードを続けて実行してください。
>>> ss.title # スプレッドシート名
'Untitled spreadsheet'
>>> ss.title = 'Sweigart Books' # スプレッドシート名の変更
>>> ss.id # 一意のID(読み取り専用属性)
'15gjrbgTmUzItRt9KUcL4JajLaQU70xanstB1dXKoSlM'
>>> ss.url # 元URL(読み取り専用属性)
'https://docs.google.com/spreadsheets/d/15gjrbgTmUzItRt9KUcL4JajLaQU70xanstB1dXKoSlM/'
>>> ss.sheetTitles # すべてのシート名
('Copy of Books',)
>>> ss.sheets # このスプレッドシートのSheetオブジェクト(順序あり)
(<Sheet sheetId=1464919459, title='Copy of Books', rowCount=1000, columnCount=26>,)
>>> ss.sheets[0] # このスプレッドシートの最初のSheetオブジェクト
<Sheet sheetId=1464919459, title='Copy of Books', rowCount=1000, columnCount=26>
>>> ss['Copy of Books'] # シート名でもアクセス可能
<Sheet sheetId=1464919459, title='Copy of Books', rowCount=1000, columnCount=26>
>>> ss.Sheet('New blank sheet') # 新しいシートの作成
<Sheet sheetId=1759616008, title='New blank sheet', rowCount=1000, columnCount=26>
>>> ss.sheets[1].delete() # このスプレッドシートの2番目のシートを削除
誰かがブラウザでスプレッドシートを変更した場合、refresh()メソッドを呼び出すと、オンラインのデータに合うように、Spreadsheetオブジェクトをスクリプトから更新できます。
>>> ss.refresh()Spreadsheetオブジェクトの属性だけでなく、Sheetオブジェクトのデータも更新されます。Spreadsheetオブジェクトに適用した変更はリアルタイムでオンラインのスプレッドシートに反映されます。
スプレッドシートのダウンロードとアップロード
Googleスプレッドシートは、Excel、OpenOffice、CSV、TSV、PDFと様々な形式でダウンロードできます。スプレッドシートのデータのHTMLを含むZIPファイルとしてダウンロードすることもできます。EZSheetsはこれらの形式でのダウンロードに対応する関数があります。
>>> import ezsheets
>>> ss = ezsheets.Spreadsheet('https://autbor.com/examplegs')
>>> ss.title
'Sweigart Books (DO NOT DELETE)'
>>> ss.downloadAsExcel() # スプレッドシートをExcelファイルとしてダウンロード
'Sweigart_Books.xlsx'
>>> ss.downloadAsODS() # スプレッドシートをOpenOfficelファイルとしてダウンロード
'Sweigart_Books.ods'
>>> ss.downloadAsCSV() # スプレッドシートをCSVファイルとしてダウンロード
'Sweigart_Books.csv'
>>> ss.downloadAsTSV() # スプレッドシートをTSVファイルとしてダウンロード
'Sweigart_Books.tsv'
>>> ss.downloadAsPDF() # スプレッドシートをPDFファイルとしてダウンロード
'Sweigart_Books.pdf'
>>> ss.downloadAsHTML() # スプレッドシートをHTMLを含むZIPファイルとしてダウンロード
'Sweigart_Books.zip'
CSVとTSV形式のファイルには一つのシートしか含まれません。よって、このどちらかの形式でGoogleスプレッドシートをダウンロードする場合は、最初のシートしか取得できません。別のシートをダウンロードするには、ダウンロードする前にSheetオブジェクトの順番を変える必要があります。
ダウンロード関数はすべてダウンロードしたファイル名の文字列を返します。ダウンロード関数に新しいファイル名を渡してファイル名を指定することもできます。
>>> ss.downloadAsExcel('a_different_filename.xlsx')
'a_different_filename.xlsx'
この関数はローカルに保存されたファイル名を返します。
スプレッドシートの削除
スプレッドシートを削除するには、delete()メソッドを呼び出します。
>>> import ezsheets
>>> ss = ezsheets.Spreadsheet() # スプレッドシートの作成
>>> ezsheets.listSpreadsheets() # スプレッドシートの作成確認
{'1aCw2NNJSZblDbhygVv77kPsL3djmgV5zJZllSOZ_mRk': 'Delete me'}
>>> ss.delete() # スプレッドシートの削除
>>> ezsheets.listSpreadsheets() # ゴミ箱フォルダにあるスプレッドシートも一覧表示される
{'1aCw2NNJSZblDbhygVv77kPsL3djmgV5zJZllSOZ_mRk': 'Delete me'}
delete()メソッドは、スプレッドシートをGoogleドライブのゴミ箱フォルダに移動させます。 https://
>>> ss.delete(permanent=True)
>>> ezsheets.listSpreadsheets()
{}
一般的に、自動化スクリプトでスプレッドシートを完全に削除するのはいい考えではありません。スクリプトにバグがあってもスプレッドシートを回復する術がないからです。無料のGoogleアカウントでもドライブはギガバイト単位の容量が利用できますから、容量を心配する必要はあまりないでしょう。
シートオブジェクト
SpreadsheetオブジェクトはSheetオブジェクトを持っています。Sheetオブジェクトは各シートの行と列のデータを表します。角かっこと整数のインデックスでシートにアクセスできます。
Spreadsheetオブジェクトのsheets属性は、スプレッドシートで表示される順番でSheetオブジェクトのタプルを保持しています。対話型シェルに以下の内容を入力して、スプレッドシートのSheetオブジェクトにアクセスしてみてください。
>>> import ezsheets
>>> ss = ezsheets.Spreadsheet() # Sheet1という名前のシートが最初からある
>>> sheet2 = ss.Sheet('Spam')
>>> sheet3 = ss.Sheet('Eggs')
>>> ss.sheets # このスプレッドシートのSheetオブジェクト(順序あり)
(<Sheet sheetId=0, title='Sheet1', rowCount=1000, columnCount=26>, <Sheet sheetId=284204004,
title='Spam', rowCount=1000, columnCount=26>, <Sheet sheetId=1920032872, title='Eggs',
rowCount=1000, columnCount=26>)
>>> ss.sheets[0] # このスプレッドシートの最初のSheetオブジェクト
<Sheet sheetId=0, title='Sheet1', rowCount=1000, columnCount=26>
SpreadsheetオブジェクトのsheetTitles属性はすべてのシート名を保持しています。対話型シェルで次のように入力してみてください。
>>> ss.sheetTitles # このスプレッドシートのすべてのシート名
('Sheet1', 'Spam', 'Eggs')
Sheetオブジェクトを取得できたら、次の節で説明するように、Sheetオブジェクトのメソッドでデータの読み書きができます。
データの読み書き
Excelと同じように、Googleスプレッドシートのワークシートには、データを含むセルの行と列があります。角かっこ演算子[] でセルの読み書きができます。例えば、対話型シェルに以下の内容を入力すると、新しいスプレッドシートを作成してデータを追加します。
>>> import ezsheets
>>> ss = ezsheets.Spreadsheet()
>>> ss.title = 'My Spreadsheet'
>>> sheet = ss.sheets[0] # このスプレッドシートの最初のシートを取得
>>> sheet.title
'Sheet1'
>>> sheet['A1'] = 'Name' # A1セルの値を設定
>>> sheet['B1'] = 'Age'
>>> sheet['C1'] = 'Favorite Movie'
>>> sheet['A1'] # A1セルの値を読み取り
'Name'
>>> sheet['A2'] # 空白セルは空文字列を返す
''
>>> sheet[2, 1] # 2列目1行目はB1と同じ
'Age'
>>> sheet['A2'] = 'Alice'
>>> sheet['B2'] = 30
>>> sheet['C2'] = 'RoboCop'
>>> sheet['B2'] # データはすべて文字列として返される
'30'
これらの指示によりGoogleスプレッドシートは図15-2のようになります。
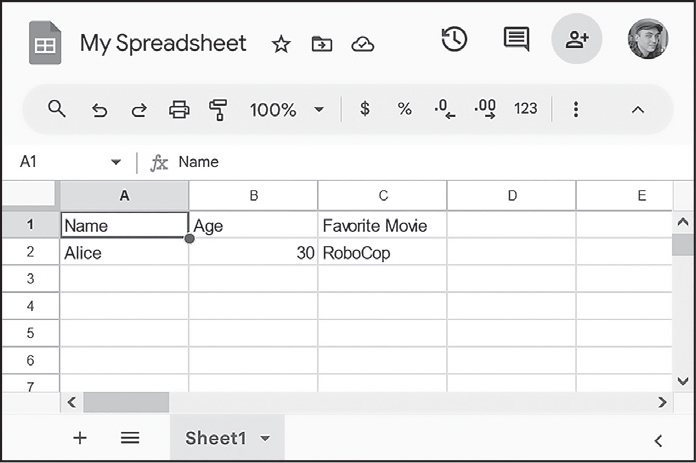
図 15-2:上記の例の指示により作成されたスプレッドシート
SheetオブジェクトのすべてのデータはSpreadsheetオブジェクトが最初にロードされたときにロードされます。そのため、データの読み取りは一瞬でできます。しかし、値をオンラインのスプレッドシートに書き込むには、ネットワーク接続が必要で、1秒程度かかります。数千セルを一つずつ更新すると非常に時間がかかります。一つずつ更新するのではなく、行全体や列全体を一度に更新する方法を次の節で示します。
列と行を操作する
GoogleスプレッドシートのセルはExcelと同じように操作できます。Pythonの0始まりのリストインデックスとは異なり、Googleスプレッドシートの行と列は1始まりです。最初の行や列のインデックスは1であり、0ではありません。convertAddress()関数を使えば、'A2'のような文字スタイルの座標を(column, row)のようなタプルスタイルの座標に変換できます(逆の変換もできます)。getColumnLetterOf()関数とgetColumnNumberOf()関数は、列のアルファベットと数値を変換します。対話型シェルで次のように入力してみてください。
>>> import ezsheets
>>> ezsheets.convertAddress('A2') # 文字スタイルの座標を変換
(1, 2)
>>> ezsheets.convertAddress(1, 2) # タプルスタイルの座標を変換
'A2'
>>> ezsheets.getColumnLetterOf(2)
'B'
>>> ezsheets.getColumnNumberOf('B')
2
>>> ezsheets.getColumnLetterOf(999)
'ALK'
>>> ezsheets.getColumnNumberOf('ZZZ')
18278
ソースコードに座標を入力するなら'A2'文字スタイルの座標が便利です。しかし座標をループさせて列番号が必要になるなら(column, row)タプルスタイルの座標が便利です。2つのスタイルを変換するのに、convertAddress()関数、getColumnLetterOf()関数、getColumnNumberOf()関数が役立ちます。
列全体または行全体を読み書きする
先ほど述べたように、一度に一つのセルに書き込むと時間がかかりすぎます。EZSheetsには、列全体または行全体を読み書きするSheetメソッドがあります。getColumn()、getRow()、updateColumn()、updateRow()のメソッドが、それぞれ列全体または行全体を読み書きします。これらのメソッドはGoogleスプレッドシートのサーバーにリクエストを送り、スプレッドシートを更新します。よってインターネット接続が必要になります。この節の例では、第14章のproduceSales3.xlsxをGoogleスプレッドシートにアップロードして使います。このファイルは本書のオンライン素材からダウンロードできます。最初の8行を表15-1に示します。
A |
B |
C |
D |
|
|---|---|---|---|---|
1 |
PRODUCE |
COST PER POUND |
POUNDS SOLD |
TOTAL |
2 |
Potatoes |
0.86 |
21.6 |
18.58 |
3 |
Okra |
2.26 |
38.6 |
87.24 |
4 |
Fava beans |
2.69 |
32.8 |
88.23 |
5 |
Watermelon |
0.66 |
27.3 |
18.02 |
6 |
Garlic |
1.19 |
4.9 |
5.83 |
7 |
Parsnips |
2.27 |
1.1 |
2.5 |
8 |
Asparagus |
2.49 |
37.9 |
94.37 |
produceSales3.xlsxファイルを現在の作業ディレクトリに置いて、対話型シェルで以下の内容を実行してこのExcelファイルをアップロードしてください。
>>> import ezsheets
>>> ss = ezsheets.upload('produceSales3.xlsx')
>>> sheet = ss.sheets[0]
>>> sheet.getRow(1) # 最初の行は0ではなく1
['PRODUCE', 'COST PER POUND', 'POUNDS SOLD', 'TOTAL', '', '']
>>> sheet.getRow(2)
['Potatoes', '0.86', '21.6', '18.58', '', '']
>>> sheet.getColumn(1)
['PRODUCE', 'Potatoes', 'Okra', 'Fava beans', 'Watermelon', 'Garlic',
--snip--
>>> sheet.getColumn('A') # getColumn(1)と同じ
['PRODUCE', 'Potatoes', 'Okra', 'Fava beans', 'Watermelon', 'Garlic',
--snip--
>>> sheet.getRow(3)
['Okra', '2.26', '38.6', '87.24', '', '']
>>> sheet.updateRow(3, ['Pumpkin', '11.50', '20', '230'])
>>> sheet.getRow(3)
['Pumpkin', '11.50', '20', '230', '', '']
>>> columnOne = sheet.getColumn(1)
>>> for i, value in enumerate(columnOne):
... # Pythonのリスト内の文字列を大文字に
... columnOne[i] = value.upper()
...
>>> sheet.updateColumn(1, columnOne) # 列全体を1回のリクエストで更新
getRow()関数とgetColumn()関数は指定した行または列のすべてのセルのデータをリストとして取得します。空白セルはリスト内で空白文字列値になります。getColumn()に列番号とアルファベット文字のどちらを渡しても、指定した列のデータを取得します。先の例ではgetColumn(1)とgetColumn('A')が同じリストを返すことを示しています。
updateRow()関数とupdateColumn()関数は、渡した値のリストで、行または列のデータを上書きします。この例では、3行目は最初okra(オクラ)の情報を含んでいましたが、updateRow()呼び出しによりpumpkins(かぼちゃ)のデータに置き換えました。sheet.getRow(3)をもう一度呼び出すと、3行目の新しい値を確認できます。
たくさんのセルを更新するときに、セルを一つずつ更新するのは遅いです。列または行をリストとして取得し、リストを更新して、そのリストで列全体または行全体を更新すれば、ずっと速いです。すべての変更をGoogle Cloudのサービスへの一度のリクエストでできるからです。
getRows()メソッドを呼び出すと、リストのリストが返され、すべての行を一度で取得できます。外側のリストの中に入っている内側のリストはシートの一つの行を表します。このデータ構造中の、農産物の種類、販売ポンド数、総売上の一部の値を変更します。そして、それをupdateRows()メソッドに渡します。以下の対話型シェルの内容を実行してください。
>>> rows = sheet.getRows() # スプレッドシートのすべての行を取得
>>> rows[0] # 最初の行の値
['PRODUCE', 'COST PER POUND', 'POUNDS SOLD', 'TOTAL', '', '']
>>> rows[1]
['POTATOES', '0.86', '21.6', '18.58', '', '']
>>> rows[1][0] = 'PUMPKIN' # 農産物の種類を変更
>>> rows[1]
['PUMPKIN', '0.86', '21.6', '18.58', '', '']
>>> rows[10]
['OKRA', '2.26', '40', '90.4', '', '']
>>> rows[10][2] = '400' # 販売ポンド数を変更
>>> rows[10][3] = '904' # 総売上を変更
>>> rows[10]
['OKRA', '2.26', '400', '904', '', '']
>>> sheet.updateRows(rows) # 変更点についてオンラインのスプレッドシートを更新
getRows()から返されたリストのリストの1行目と10行目を修正して、updateRows()にそのリストのリストを渡すことで、シート全体を一回のリクエストで更新しています。
このGoogleスプレッドシートには最後に空白の列があることに注意してください。アップロードしたシートには6列ありますが、データは4列しかありません。rowCount属性とcolumnCount属性でシートの行数と列数を読み取れます。これらの属性に値を設定すると、シートのサイズを変えられます。
>>> sheet.rowCount # シートの行数
23758
>>> sheet.columnCount # シートの列数
6
>>> sheet.columnCount = 4 # 列数を4に変更
>>> sheet.columnCount # シートの列数は4
4
この指示によりproduceSales3.xlsxの5列目と6列目を削除します。図15-3にその様子を示しました。
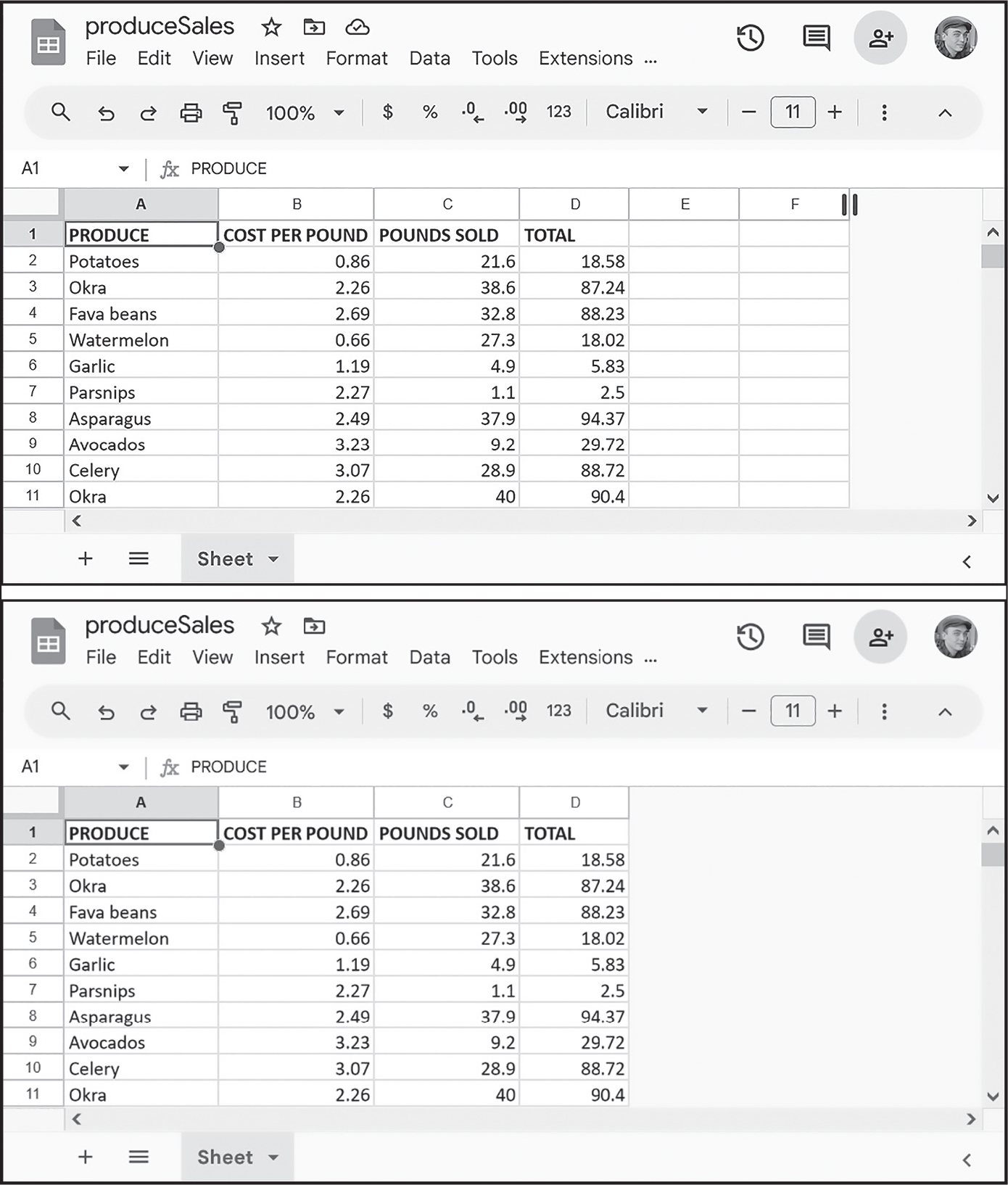
図 15-3:列数を4に変更する前(上)と後(下)
Googleのドキュメントによると、Googleスプレッドシートは1000万セルまで収納できます。しかし、データの更新にかかる時間を短くするためにシートを必要なだけの大きさにするのがよいでしょう。
シートの作成、移動、削除
Googleスプレッドシートは、Sheet1という名前の一つのシートだけがある状態で始まります。Sheet()メソッドでシートのリストの末尾にシートを追加できます。文字列を渡して新しいシート名を指定することもできます。オプションの第二引数には、新しいシートを作成するインデックスを整数で指定します。対話型シェルで以下の内容を実行して、スプレッドシートを作成して新しいシートを追加してみだくさい。
>>> import ezsheets
>>> ss = ezsheets.Spreadsheet()
>>> ss.title = 'Multiple Sheets'
>>> ss.sheetTitles
('Sheet1',)
>>> ss.Sheet('Spam') # シートのリストの末尾に新しいシートを作成
<Sheet sheetId=2032744541, title='Spam', rowCount=1000, columnCount=26>
>>> ss.Sheet('Eggs') # さらに新しいシートを作成
<Sheet sheetId=417452987, title='Eggs', rowCount=1000, columnCount=26>
>>> ss.sheetTitles
('Sheet1', 'Spam', 'Eggs')
>>> ss.Sheet('Bacon', 0) # シートのリストのインデックス0に新しいシートを作成
<Sheet sheetId=814694991, title='Bacon', rowCount=1000, columnCount=26>
>>> ss.sheetTitles
('Bacon', 'Sheet1', 'Spam', 'Eggs')
この指示では、デフォルトのSheet1に加えて、Bacon、Spam、Eggsという3つの新しいシートをスプレッドシートに追加しています。スプレッドシートのシートには順序があり、Sheet()の第二引数で追加するシートのインデックスを指定しない限り新しいシートはリストの末尾に追加されます。Baconという名前のシートをインデックス0に追加したので、Baconはこのスプレッドシートの最初に来ています。他の3つのシートは一つずつ位置がずれます。この挙動はinsert()リストメソッドに似ています。
図15-4に示すように、新しいシートが画面下部のタブで確認できます。
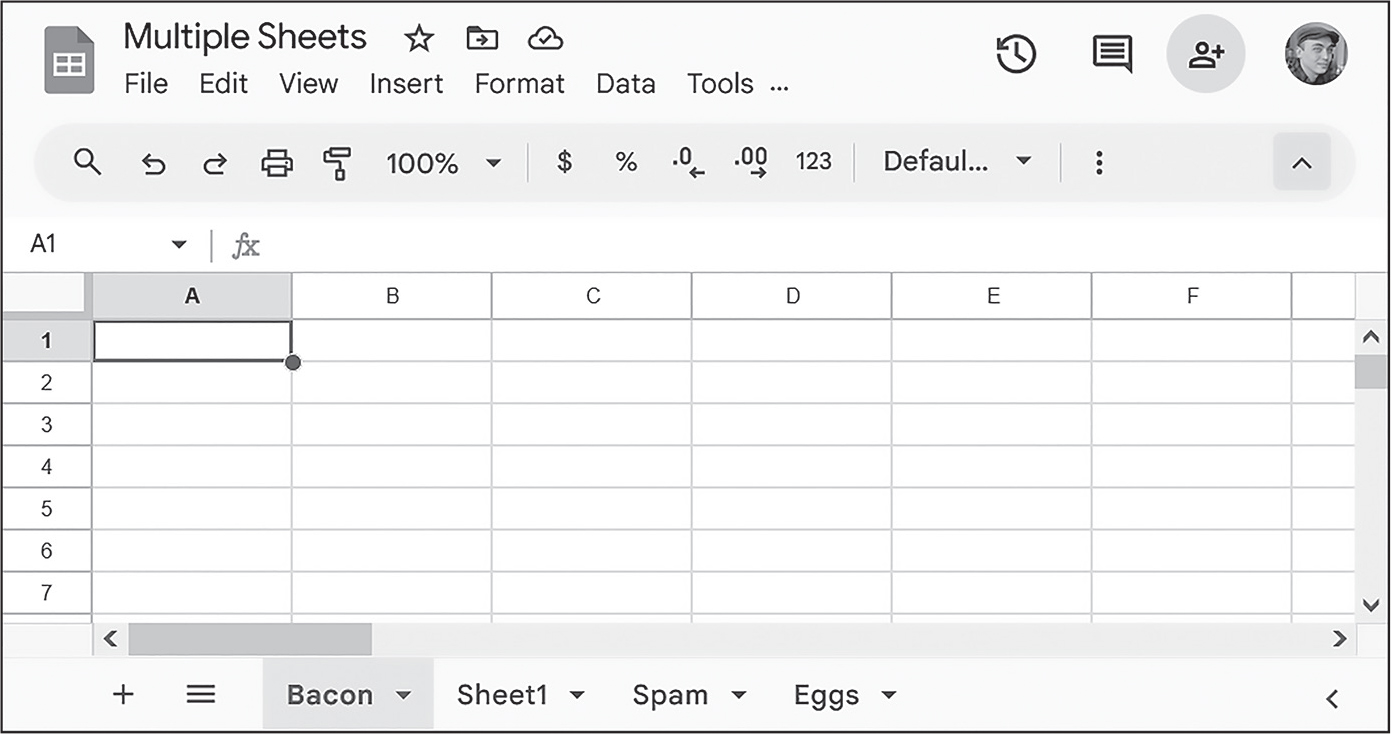
図 15-4:スプレッドシートにSpam、Eggs、Baconシートを追加して複数のシートがあるスプレッドシート
シートの順序はindex属性からわかり、index属性に新しい値を代入するとシートの順序を変えられます。
>>> ss.sheetTitles
('Bacon', 'Sheet1', 'Spam', 'Eggs')
>>> ss.sheets[0].index
0
>>> ss.sheets[0].index = 2 # シートのインデックスを0から2に移動
>>> ss.sheetTitles
('Sheet1', 'Spam', 'Bacon', 'Eggs')
>>> ss.sheets[2].index = 0 # シートのインデックスを2から0に移動
>>> ss.sheetTitles
('Bacon', 'Sheet1', 'Spam', 'Eggs')
Sheetオブジェクトのdelete()メソッドは、スプレッドシートからシートを削除します。シートを残してそのシートのデータを削除したければ、clear()メソッドを呼び出してすべてのセルをクリアして空白のシートにします。以下の式を対話型シェルに入力してみてください。
>>> ss.sheetTitles
('Bacon', 'Sheet1', 'Spam', 'Eggs')
>>> ss.sheets[0].delete() # インデックス0の"Bacon"シートを削除
>>> ss.sheetTitles
('Sheet1', 'Spam', 'Eggs')
>>> ss['Spam'].delete() # "Spam"シートを削除
>>> ss.sheetTitles
('Sheet1', 'Eggs')
>>> sheet = ss['Eggs'] # "Eggs"シートを変数に代入
>>> sheet.delete() # "Eggs"シートを削除
>>> ss.sheetTitles
('Sheet1',)
>>> ss.sheets[0].clear() # "Sheet1"シートのセルをすべてクリア
>>> ss.sheetTitles # "Sheet1"シートは空白だが存在
('Sheet1',)
シートは完全に削除されます。データを回復する方法はありません。copyTo()メソッドで別のスプレッドシートにコピーすれば、バックアップできます。次の節ではコピーについて説明します。
シートのコピー
SpreadsheetオブジェクトにはSheetオブジェクトのリストがあります。(前の節で説明したように)このリストの順序を変えればシートの順序を変えられます。このリストを別のスプレッドシートにコピーすることもできます。Sheetオブジェクトを別のSpreadsheetオブジェクトにコピーするには、copyTo()メソッドを呼び出します。コピー先のスプレッドシートのSpreadsheetオブジェクトを引数として渡します。スプレッドシートを2つ作成し、1つ目のスプレッドシートのデータを2つ目のスプレッドシートにコピーします。対話型シェルに以下の内容を入力してください。
>>> import ezsheets
>>> ss1 = ezsheets.Spreadsheet()
>>> ss1.title = 'First Spreadsheet'
>>> ss1.sheets[0].title = 'Spam' # ss1にSpamという名前のシートを持たせる
>>> ss2 = ezsheets.Spreadsheet()
>>> ss2.title = 'Second Spreadsheet'
>>> ss2.sheets[0].title = 'Eggs' # ss2にEggsという名前のシートを持たせる
>>> ss1[0]
<Sheet sheetId=0, title='Spam', rowCount=1000, columnCount=26>
>>> ss1[0].updateRow(1, ['Some', 'data', 'in', 'the', 'first', 'row'])
>>> ss1[0].copyTo(ss2) # ss1の1番目のシートをss2スプレッドシートにコピー
>>> ss2.sheetTitles # ss2にはss1の1番目のシートのコピーがある
('Eggs', 'Copy of Spam')
コピーしたシートは、コピー先のスプレッドシートのシートのリストの末尾にCopy ofという接頭辞つきで現れます。新しいスプレッドシートのindex属性を変更すればシートの順序を変えられます。
Googleフォーム
Googleアカウントがあれば、https://
第19章でPythonプログラムを指定した時間に定期実行するスケジュール方法を説明します。定期的にGoogleフォームの回答スプレッドシートをチェックして、新しい回答がないかを確認するプログラムを書けます。第20章で説明する内容を活用すれば、プログラムに通知をさせて、フォーム提出のリアルタイム通知を受けることができます。
ここまで見てきたように、Pythonは複数の既存のソフトウェアシステムをつなげて、全体が部分の総和よりも強力になるような自動化プロセスを作成できるので、グルー(糊)言語としてよく知られています。
プロジェクト11:うそのブロックチェーン暗号資産詐欺
このプロジェクトでは、Googleスプレッドシートをうそのブロックチェーンとして用いて、ボーリングコインの取引を追跡します。ボーリングコインは筆者が考え出した暗号資産詐欺です。(投資家も利用者も、ブロックチェーンが本物のブロックチェーンのデータ構造であるかどうかなんて気にしないでお金を出しているとわかりました。)
https://
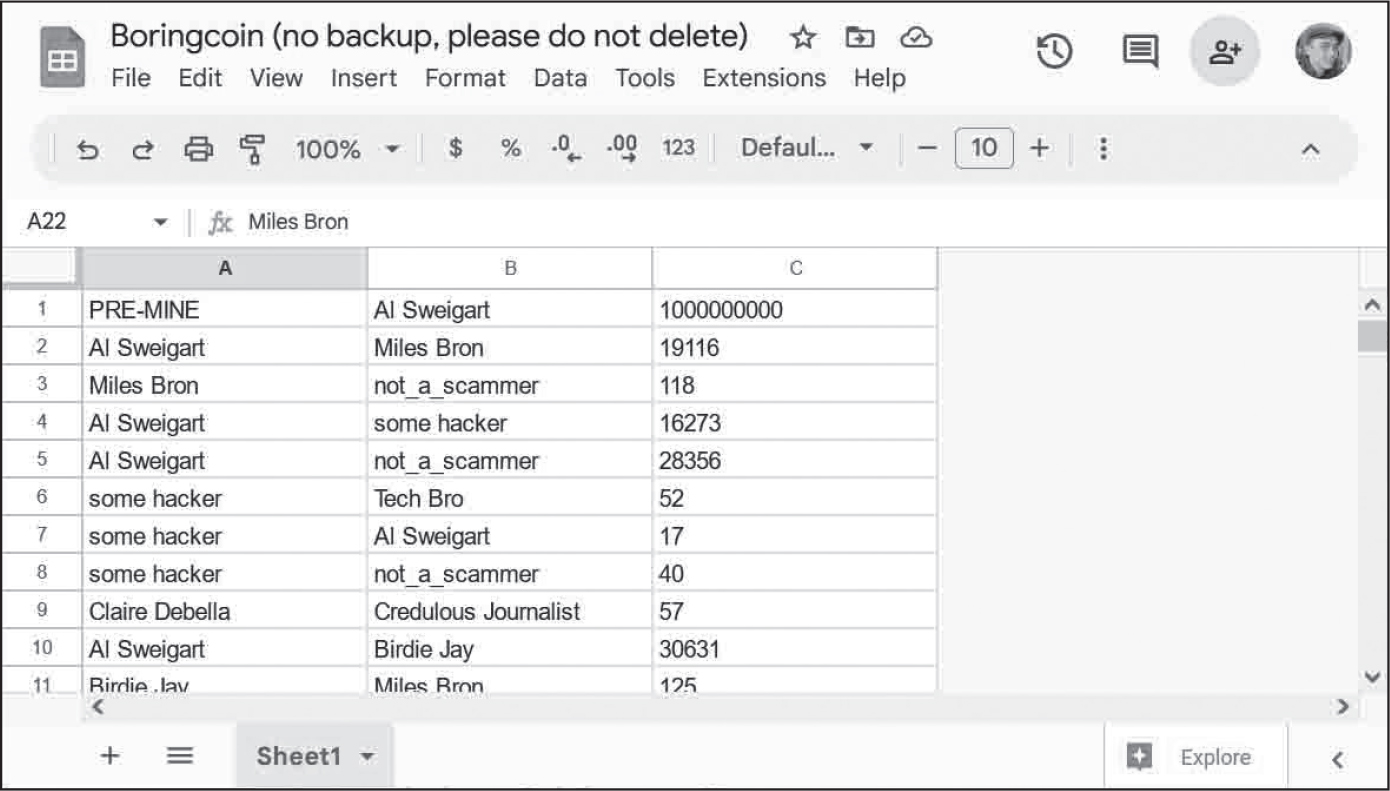
図 15-5:Googleスプレッドシートに格納されたボーリングコインのうそのブロックチェーン
最初の取引は送信者が'PRE-MINE'で受信者が'Al Sweigart'です。取引量はたったの1000000000です。'Al Sweigart'アカウントは19116ボーリングコインを'Miles Bron'に送信し、'Miles Bron'は118ボーリングコインを'not_a_scammer'に送信しました。4番目の取引では16273ボーリングコインを'Al Sweigart'から'some hacker'に送信しました。(私はこの取引を承認しておらず、それ以来python12345を自分のGoogleアカウントのパスワードに使うのをやめました。)
2つのプログラムを書きます。1つは、すべての取引を精査し、すべてのアカウントとその現在残高の辞書を作成するauditBoringcoin.pyプログラムです。もう1つは、Googleスプレッドシートの末尾に新しい取引の行を追加するaddBoringcoinTransaction.pyプログラムです。このブロックチェーンプログラムはただのお遊びで現実のものではありません(NFTやweb3といった「現実の」ブロックチェーンも空想的なものではありますが)。
ステップ1:うそのブロックチェーン監査
「ブロックチェーン」全体を精査し、すべてのアカウントの現在残高を判定するプログラムを書きます。このデータを保持するのに辞書を使います。キーはアカウント名で値はボーリングコインの保有量です。このプログラムでは暗号資産ネットワークに存在するボーリングコインの総量も表示します。EZSheetsをインポートして辞書を設定するところから始めます。
import ezsheets
ss = ezsheets.Spreadsheet('https://autbor.com/boringcoin')
accounts = {} # キーはアカウント名、値は保有量
次に、スプレッドシートの各行を反復処理します。送信者と受信者と取引量を把握します。Googleスプレッドシートはデータを常に文字列として返しますから、amountの値で計算を行うために整数値に変換する必要があります。
# 各行は取引であり、一行ずつ反復処理する
for row in ss.sheets[0].getRows():
sender, recipient, amount = row[0], row[1], int(row[2])
送信者が'PRE-MINE'という特別なアカウントであれば、これは無限のお金の源です。暗号資産詐欺のいいところは事前に採掘されたコインを使えることで、ボーリングコインも例に漏れません。取引量をaccountsの受信者のアカウントに追加します。辞書に受信者が存在しなければ、setdefault()メソッドでそのアカウントの保有量として0という値を設定します。
if sender == 'PRE-MINE':
# 送信者'PRE-MINE'は何もないところからお金を作り出す
accounts.setdefault(recipient, 0)
accounts[recipient] += amount
それ以外の場合は、その取引量を、送信者のアカウントから差し引き、受信者のアカウントに追加します。
else:
# 送信者から受信者に資金移動
accounts.setdefault(sender, 0)
accounts.setdefault(recipient, 0)
accounts[sender] -= amount
accounts[recipient] += amount
ループが終われば、辞書accountsを表示すれば現在残高がわかります。
print(accounts)この監査の一部として、この辞書の全員の残高を足し合わせてネットワーク全体におけるボーリングコインの総量を計算します。変数totalを0で始めて、forループで辞書accountsのキーと値のペアを反復処理します。すべての値をtotalに足し合わせてから、ボーリングコインの総量を表示します。
total = 0
for amount in accounts.values():
total += amount
print('Total Boringcoins:', total)
このプログラムを実行すると、出力は次のようになります。
{'Al Sweigart': 999058553, 'Miles Bron': 38283, 'not_a_scammer': 48441,
'some hacker': 44429, 'Tech Bro': 53424, 'Claire Debella': 54443,
'Credulous Journalist': 50408, 'Birdie Jay': 36832, 'Carol': 82867, 'Mark Z.':
68650, 'Bob': 37920, 'Andi Brand': 57218, 'Eve': 88296, 'Al Sweigart sock
#27': 78080, 'Tax evader': 40937, 'Duke Cody': 17544, 'Lionel Toussaint':
54650, 'some scammer': 2694, 'Alice': 44503, 'David': 41828}
Total Boringcoins: 1000000000
総量は1000000000で、事前採掘されたボーリングコインと一致します。
ステップ2:取引の実行
次のプログラムは、新たな取引を追加するためにブロックチェーンGoogleスプレッドシートに行を追加する、addBoringcoinTransaction.pyです。sys.argvから、送信者、受信者、取引量という、コマンドライン引数を3つ読み取ります。例えば、ターミナルで次のように実行します。
python addBoringcoinTransaction.py "Al Sweigart" Eve 2000このプログラムはGoogleスプレッドシートにアクセスして、最終行に空行を追加してから、'Al Sweigart'、'Eve'、'2000'という値を埋めます。ターミナルではスペースを含むコマンドライン引数は、"Al Sweigart"のようにダブルクォートで囲まなければなりません。そうしないと、ターミナルはこれらを2つの別の引数であると解釈してしまいます。
addBoringcoinTransactions.pyはまずコマンドライン引数をチェックし、コマンドライン引数に基づいて送信者、受信者、取引量の変数を代入します。
import sys, ezsheets
if len(sys.argv) < 4:
print('Usage: python addBoringcoinTransaction.py sender recipient amount')
sys.exit()
# コマンドライン引数から取引情報を取得
sender, recipient, amount = sys.argv[1:]
スプレッドシートには文字列として書き込みますから、amountを文字列から整数に変換する必要はありません。
次に、EZSheetsが、うそのブロックチェーンを記録したGoogleスプレッドシートに接続して、インデックス0の最初のシートを選択します。読者のみなさんはボーリングコインGoogleスプレッドシートの編集権限がありませんから、Googleアカウントにログインした状態でウェブブラウザでURLを開いて、ファイルコピーを作成で自分のGoogleアカウントにコピーしてください。それから、'https://autbor.com/boringcoin'を、ブラウザのアドレスバーに表示されている自分のGoogleスプレッドシートのURLに置き換えてください。
# URLを自分のGoogleスプレッドシートのURLに変更
# そうしないと"The caller does not have permission"エラーが発生
ss = ezsheets.Spreadsheet('https://autbor.com/boringcoin')
sheet = ss.sheets[0]
最後に、シートの行数を取得して、それを1増やし、その行を送信者、受信者、取引量のデータで埋めます。
# シートに新しい取引の1行追加
sheet.rowCount += 1
sheet[1, sheet.rowCount] = sender
sheet[2, sheet.rowCount] = recipient
sheet[3, sheet.rowCount] = amount
ターミナルからpython addBoringcoinTransaction.py "Al Sweigart" Eve 2000を実行すると、Googleスプレッドシートの最終行にAl Sweigart、Eve、2000の新しい行が追加されます。auditBoringcoin.pyプログラムをもう一度実行すると、暗号資産ネットワーク内の最新の全員のアカウントの残高がわかります。
このGoogleスプレッドシートでのブロックチェーンデータ構造は無責任なものです。エラー処理をしていませんから、大惨事が起こるでしょう。これは大部分の市場化されているブロックチェーン製品も同じようなものです。ネズミ講が破綻する前にボーリングコインを購入するこの機会を見逃さずご連絡ください。
Googleスプレッドシートのサービス割り当て
Googleスプレッドシートはオンライン上にありますから、簡単にシートを複数人で共有し、同時にアクセスできます。しかし、シートの読み取りと更新が、ハードドライブに保存したExcelファイルと比べると遅いです。さらに、Googleスプレッドシートには、実行できる読み書き操作の回数に制限があります。
Googleの開発者ガイドラインによると、1日に新しく作成できるスプレッドシートは250までで、無料のGoogleアカウントでは1分あたり数百リクエストまでしかできません。Googleの使用制限はhttps://
つまり、EZSheetsのメソッド呼び出しは数秒かかる可能性があるということです。API使用量を確認してサービス割り当てを増やしたければ、https://
まとめ
Googleスプレッドシートは、ブラウザで実行する人気のあるオンラインのスプレッドシートアプリケーションです。EZSheetsサードパーティパッケージを使うと、スプレッドシートのダウンロード、作成、読み取り、変更ができます。EZSheetsはスプレッドシートをSpreadsheetオブジェクトとして表し、そこにはSheetオブジェクトのリストが含まれます。各シートにはデータの列と行があり、いくつかの方法で読み取りと更新ができます。
Googleスプレッドシートはデータの共有と共同編集が簡単にできますが、遅いという欠点があります。ウェブリクエストを通じてスプレッドシートの更新をしなければならず、実行に数秒かかります。とはいえ、たいていの場合、この遅さはPythonスクリプトでEZSheetsを使う際に問題とはならないでしょう。Googleスプレッドシートには変更を行う頻度の制限もあります。
EZSheetsの機能の完全なドキュメントは、https://
練習問題
1. EZSheetsがGoogleスプレッドシートにアクセスするのに必要な3つのファイルは何ですか?
2. EZSheetsにある2種類のオブジェクトは何ですか?
3. GoogleスプレッドシートからExcelファイルを作成するにはどのようにしますか?
4. ExcelファイルからGoogleスプレッドシートを作成するにはどのようにしますか?
5. 変数ssにSpreadsheetオブジェクトが格納されているとします。Studentsという名前のシートのB2セルからデータを読み取るコードを書いてください。
6. 列番号999を表すアルファベットの文字はどのようにすればわかりますか?
7. シートの行数と列数はどのようにすればわかりますか?
8. スプレッドシートはどのように削除しますか? 完全に削除されますか?
9. 新しいSpreadsheetオブジェクトを作成する関数と、新しいSheetオブジェクトを作成する関数を、それぞれ挙げてください。
10. EZSheetsで頻繁に読み書きのリクエストを行いGoogleアカウントのサービス割り当てを超過すると、どうなりますか?
練習プログラム
以下の練習プログラムを書いてください。
Googleフォームのデータダウンロード
先に触れたように、Googleフォームを使うと、人々から情報を簡単に集められるシンプルなオンラインフォームを作成できます。フォームに入力された情報はGoogleスプレッドシートに蓄積されます。このプロジェクトでは、ユーザーが入力したフォームの情報を自動的にダウンロードするプログラムを書きます。https://
フォームの回答タブで、「スプレッドシートにリンク」ボタンをクリックして、ユーザーが送信した回答を蓄積するGoogleスプレッドシートを作成します。回答例がスプレッドシートの最初の行に表示されているはずです。EZSheetsを使ってこのスプレッドシートのメールアドレスのリストを収集するPythonのスクリプトを書いてください。
スプレッドシートを別の形式に変換する
Googleスプレッドシートでは、スプレッドシートを別の形式に変換できます。アップロードするファイルをupload()に渡すスクリプトを書いてください。Googleスプレッドシートにアップロードされたら、downloadAsExcel()やdownloadAsODS()などの関数を使って別の形式でそのスプレッドシートのコピーをダウンロードしてください。
スプレッドシートの誤りを発見する
丸一日かけて豆を数える仕事をして、豆の合計をスプレッドシートにまとめてGoogleスプレッドシートにアップロードしました。このスプレッドシートは誰でも閲覧可能です(編集はできません)。このスプレッドシートは以下のコードで取得できます。
>>> import ezsheets
>>> ss = ezsheets.Spreadsheet('1jDZEdvSIh4TmZxccyy0ZXrH-ELlrwq8_YYiZrEOB4jg')
https://
ヒントとして、ss.sheets[0].getRow(rowNum)で行内の各セルにアクセスします。ssはSpreadsheetオブジェクトで、rowNumは行番号です。Googleスプレッドシートの行番号は0ではなく1から始まることに注意してください。セルの値は文字列ですから、計算をする前に整数に変換する必要があります。int(ss.sheets[0].getRow(2)[0]) * int(ss.sheets[0].getRow(2)[1]) == int(ss.sheets[0].getRow(2)[2])という式は2行目の合計が正しければTrueを返します。このコードをループ内で用いて合計が誤っている行を特定してください。