14 Excelファイル

スプレッドシートをプログラミングツールだと考えることはあまりありませんが、情報を2次元のデータ構造に整理したり、数式で計算を行ったり、グラフを出力したりと、ほとんど誰もがスプレッドシートを使っています。本章と次章では、2つのよく使われるスプレッドシートアプリケーションであるMicrosoft ExcelとGoogleスプレッドシートを、Pythonで操作します。
Excelは人気のある強力なスプレッドシートアプリケーションです。openpyxlモジュールを使うと、PythonプログラムからExcelのファイルを読み取って変更できます。例えば、あるExcelファイルから別のExcelファイルにデータをコピーして貼り付ける退屈な作業をすることがあるかもしれません。あるいは、何らかの基準に従って数千行の中から数行を選んで少し編集をすることがあるかもしれません。あるいは、部門の予算の数百あるExcelファイルから赤字の部分を探すことがあるかもしれません。これらは頭を使わない退屈なExcelの作業であり、Pythonで自動化できます。
ExcelはMicrosoftのプロプライエタリソフトウェアです。Windows、macOS、Linuxで動くLibreOfficeという代替のフリーソフトウェアがあります。LibreOfficeのCalcはExcelの.xlsxファイルフォーマットを利用できます。よって、openpyxlモジュールは、LibreOfficeのCalcでも使えます。https://
openpyxlモジュールはExcelファイルを直接操作するのであって、デスクトップのExcelアプリケーションやクラウドベースのExcelウェブアプリを操作するのではありません。クラウドベースのOffice 365をお使いでしたら、ファイルコピーを作成するコピーのダウンロードをクリックしてExcelファイルをダウンロードしてください。Pythonスクリプトを実行してExcelファイルを編集してから、そのExcelファイルをもう一度Office 365にアップロードして変更点を確認します。デスクトップのExcelアプリケーションをお持ちでしたら、Excelファイルを閉じてからPythonスクリプトを実行してExcelファイルを編集して、そのファイルをもう一度Excelで開いて変更点を確認します。
openpyxlモジュールはPythonに付属していませんから、インストールする必要があります。付録AでPythonのpipツールでサードパーティーパッケージをインストールする方法を説明しています。https://
本章ではいくつかのExcelファイルを例として使用します。https://
Excelファイルの読み取り
最初に基本的な用語の定義を確認します。Excelのスプレッドシート文書はワークブックと呼ばれます。一つのワークブックは拡張子.xlsxの一つのファイルです。
各ワークブックは複数のシート(ワークシート)を持つことができます。ユーザーが現在見ているシート(またはExcelを閉じる前に見ていたシート)は、アクティブシートと呼ばれます。各シートには列(Aで始まるアルファベットで表されます)と行(1で始まる数字で表されます)があります。列と行で定まる箱はセルと呼ばれます。各セルには数値やテキスト値を入れられます。格子状のセルとデータがシートを構成します。
本章の例では、現在の作業ディレクトリにあるexample3.xlsxという名前のExcelファイルを使います。そのExcelファイルを自分で作っても構いませんし、本書のオンライン素材からダウンロードしても構いません。図14-1は、Sheet1、Sheet2、Sheet3という名前の3つのシートのタブを示しています。
図 14-1:ワークブックのシートのタブはExcelの左下にあります
この例のファイルのSheet1は図14-1のようになっています。(example3.xlsxをダウンロードしていなければ、このデータを自分で作成したシートに入力してください。)
A |
B |
C |
|
|---|---|---|---|
1 |
4/5/2035 1:34:02 PM |
Apples |
73 |
2 |
4/5/2035 3:41:23 AM |
Cherries |
85 |
3 |
4/6/2035 12:46:51 PM |
Pears |
14 |
4 |
4/8/2035 8:59:43 AM |
Oranges |
52 |
5 |
4/10/2035 2:07:00 AM |
Apples |
152 |
6 |
4/10/2035 6:10:37 PM |
Bananas |
23 |
7 |
4/10/2035 2:40:46 AM |
Strawberries |
98 |
Excelファイルの例が用意できましたから、openpyxlモジュールで操作してみましょう。
ワークブックを開く
openpyxlモジュールをインポートしたら、openpyxl.load_workbook()関数で.xlsxファイルを開けます。以下の式を対話型シェルに入力してみてください。
>>> import openpyxl
>>> wb = openpyxl.load_workbook('example3.xlsx')
>>> type(wb)
<class 'openpyxl.workbook.workbook.Workbook'>
openpyxl.load_workbook()関数はファイル名を取り、Workbookデータ型の値を返します。このWorkbookオブジェクトはExcelファイルを表します。Fileオブジェクトが開いたテキストファイルを表すのと少し似ています。
ワークブックからシートを取得する
sheetnames属性にアクセスすることでワークブックに含まれるすべてのシート名を取得できます。以下の式を対話型シェルに入力してみてください。
>>> import openpyxl
>>> wb = openpyxl.load_workbook('example3.xlsx')
>>> wb.sheetnames # ワークブックのシート名
['Sheet1', 'Sheet2', 'Sheet3']
>>> sheet = wb['Sheet3'] # ワークブックからシートを取得
>>> sheet
<Worksheet "Sheet3">
>>> type(sheet)
<class 'openpyxl.worksheet.worksheet.Worksheet'>
>>> sheet.title # シート名を文字列として取得
'Sheet3'
>>> another_sheet = wb.active # アクティブシートを取得
>>> another_sheet
<Worksheet "Sheet1">
各シートはWorksheetオブジェクトで表されます。Worksheetオブジェクトは、シート名を辞書のキーのように角かっこ内に指定することで取得できます。このコードの最後では、Workbookオブジェクトのactive属性でそのワークブックのアクティブシートを取得しています。アクティブシートはExcelで開いたときに表示されるシートです。Worksheetオブジェクトのtitle属性からシート名を取得できます。
シートからセルを取得する
Worksheetオブジェクトでセル番地を指定すると、Cellオブジェクトを取得できます。以下の式を対話型シェルに入力してみてください。
>>> import openpyxl
>>> wb = openpyxl.load_workbook('example3.xlsx')
>>> sheet = wb['Sheet1'] # ワークブックからシートを取得
>>> sheet['A1'] # シートからセルを取得
<Cell 'Sheet1'.A1>
>>> sheet['A1'].value # セルから値を取得
datetime.datetime(2035, 4, 5, 13, 34, 2)
>>> c = sheet['B1'] # シートから別のセルを取得
>>> c.value
'Apples'
>>> # セルから行番号、列番号、値を取得
>>> f'Row {c.row}, Column {c.column} is {c.value}'
'Row 1, Column 2 is Apples'
>>> f'Cell {c.coordinate} is {c.value}'
'Cell B1 is Apples'
>>> sheet['C1'].value
73
Cellオブジェクトには、そのセルに入っている値を含むvalue属性があります。そのセルの位置情報を示すrow、column、coordinateの属性もあります。B1セルのCellオブジェクトのvalue属性にアクセスすると、文字列'Apples'を取得できます。row属性は整数の1、column属性は2、coordinate属性は'B1'です。
openpyxlモジュールは自動的にA列の日付を解釈し、文字列ではなくdatetime値として返します。第19章でdatetimeデータ型について詳しく説明します。
プログラムで列をアルファベットで指定するのはややこしいです。特にZ列以降はAA、AB、ACのように2文字になるので余計にややこしいです。アルファベットで指定しなくても、シートのcell()メソッドにrowとcolumnのキーワード引数で整数を渡せば、セルを取得できます。最初の列も最初の行も0ではなく1です。対話型シェルで続けて以下のように入力してください。
>>> sheet.cell(row=1, column=2)
<Cell 'Sheet1'.B1>
>>> sheet.cell(row=1, column=2).value
'Apples'
>>> for i in range(1, 8, 2): # 1行おきに反復処理
... print(i, sheet.cell(row=i, column=2).value)
...
1 Apples
3 Pears
5 Apples
7 Strawberries
シートのcell()メソッドにrow=1とcolumn=2を渡して、sheet['B1']と同じようにB1セルのCellオブジェクトを取得しています。
このcell()メソッドとキーワード引数を使うと、forループで一連のセルの値を表示できます。例えば、B列の奇数行のすべてのセルの値を表示したいとします。range()関数のstepパラメータに2を渡すと、1行おき(この場合は奇数行)のセルを取得できます。この例では、forループの変数iをcell()メソッドのrowキーワード引数に渡し、columnキーワード引数には2を渡して、メソッドを呼び出しています。このメソッドは文字列の'B'ではなく整数の2を受け入れます。
シートのサイズは、Worksheetオブジェクトのmax_row属性とmax_column属性で判断できます。以下の式を対話型シェルに入力してみてください。
>>> import openpyxl
>>> wb = openpyxl.load_workbook('example3.xlsx')
>>> sheet = wb['Sheet1']
>>> sheet.max_row # 最大行番号を取得
7
>>> sheet.max_column # 最大列番号を取得
3
max_column属性はExcelで見えるアルファベットの文字ではなく整数であることに注意してください。
列のアルファベットと数値を相互に変換する
数値から文字に変換するには、openpyxl.utils.get_column_letter()関数を呼び出します。文字から数値に変換するには、openpyxl.utils.column_index_from_string()関数を呼び出します。以下の式を対話型シェルに入力してみてください。
>>> import openpyxl
>>> from openpyxl.utils import get_column_letter, column_index_from_string
>>> get_column_letter(1) # 1列目を表すアルファベット文字を取得
'A'
>>> get_column_letter(2)
'B'
>>> get_column_letter(27)
'AA'
>>> get_column_letter(900)
'AHP'
>>> wb = openpyxl.load_workbook('example3.xlsx')
>>> sheet = wb['Sheet1']
>>> get_column_letter(sheet.max_column)
'C'
>>> column_index_from_string('A') # A列の列番号を取得
1
>>> column_index_from_string('AA')
27
openpyxl.utilsモジュールからこれら2つの関数をインポートしたら、27のような整数を渡してget_column_letter()を呼び出すと27列目の文字がわかります。column_index_from_string()は逆のことを行います。 列を表すアルファベット文字を渡して呼び出すと、その列が何列目かを返します。これらの関数を使うためにワークブックを読み込む必要はありません。
行と列を取得する
Worksheetオブジェクトをスライスして、行、列、行と列の範囲のCellオブジェクトを取得できます。その複数セルをすべてループで反復処理できます。以下の式を対話型シェルに入力してみてください。
>>> import openpyxl
>>> wb = openpyxl.load_workbook('example3.xlsx')
>>> sheet = wb['Sheet1']
>>> sheet['A1':'C3'] # A1からC3までのセルを取得
((<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>), (<Cell 'Sheet1'.A2>, <Cell
'Sheet1'.B2>, <Cell 'Sheet1'.C2>), (<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell
'Sheet1'.C3>))
>>> for row_of_cell_objects in sheet['A1':'C3']: ❶
... for cell_obj in row_of_cell_objects: ❷
... print(cell_obj.coordinate, cell_obj.value)
... print('--- END OF ROW ---')
...
A1 2035-04-05 13:34:02
B1 Apples
C1 73
--- END OF ROW ---
A2 2035-04-05 03:41:23
B2 Cherries
C2 85
--- END OF ROW ---
A3 2035-04-06 12:46:51
B3 Pears
C3 14
--- END OF ROW ---
A1からC3までの行と列の範囲のCellオブジェクトを取得するためにスライスに['A1':'C3']と指定して、その範囲のCellオブジェクトを含むタプルを取得しています。
このタプルは、指定した範囲の上から下までの各行を表す3つのタプルを含んでいます。この3つの内側のタプルは、それぞれ、指定した範囲の左から右までの列のCellオブジェクトを含んでいます。まとめると、このシートのスライスは、左上のセルから右下のセルにかけて、A1からC3までの範囲のCellオブジェクトをすべて含んでいます。
この範囲の各セルの値を表示するためには、2つのforループを使います。外側のforループはスライスの各行を反復処理します(❶)。各行について、内側のforループがその行の各セルを反復処理します(❷)。
特定の行または列のセルの値にアクセスするのに、Worksheetオブジェクトのrows属性とcolumns属性を利用することもできます。これらの属性は、角かっことインデックスを使えるようにするために、list()関数でリストに変換しなければなりません。以下の式を対話型シェルに入力してみてください。
>>> import openpyxl
>>> wb = openpyxl.load_workbook('example3.xlsx')
>>> sheet = wb['Sheet1']
>>> list(sheet.columns)[1] # 2列目のセルを取得
(<Cell 'Sheet1'.B1>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.B4>, <Cell
'Sheet1'.B5>, <Cell 'Sheet1'.B6>, <Cell 'Sheet1'.B7>)
>>> for cell_obj in list(sheet.columns)[1]:
... print(cell_obj.value)
...
Apples
Cherries
Pears
Oranges
Apples
Bananas
Strawberries
Worksheetオブジェクトのrows属性を使い、list()に渡せば、タプルのリストが得られます。このタプルはそれぞれの行を表し、その行のCellオブジェクトを含んでいます。columns属性をlist()に渡すと、タプルのリストが得られ、そのタプルにはその列のCellオブジェクトが含まれます。example3.xlsxは7行3列あり、list(sheet.rows)で7つのタプル(各タプルには3つのCellオブジェクトが含まれています)が得られ、list(sheet.columns)で3つのタプル(各タプルには7つのCellオブジェクトが含まれています)が得られます。
一つのタプルにアクセスするには、外側のタプルにインデックスを指定します。例えば、B列を表すタプルを取得するには、list(sheet.columns)[1]とします。A列のCellオブジェクトを含むタプルを取得するには、list(sheet.columns)[0]とします。一つの行または列を表すタプルを取得できれば、ループでCellオブジェクトを反復処理してその値を表示できます。
プロジェクト9:国勢調査統計データを集計する
2010年の合衆国の国勢調査のデータが入っている数千行のExcelファイルがあるとして、各郡について人口と国勢統計区を集計するという退屈な作業をすることになったとします(国勢統計区とは、国勢調査のために区画された地理的単位です)。各行は一つの国勢統計区を表しています。censuspopdata.xlsxという名前のファイルで本書のオンライン素材に含まれています。図14-2のような内容になっています。
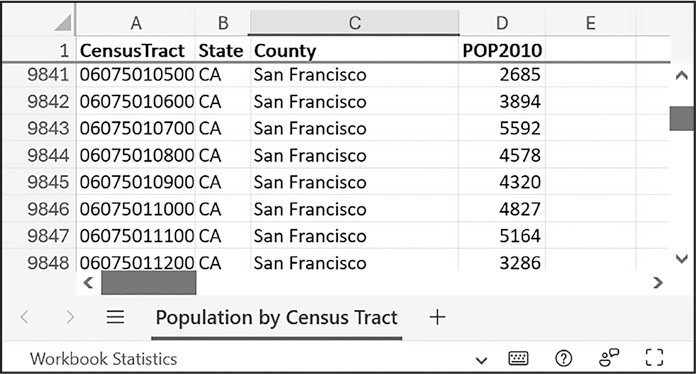
図 14-2:censuspopdata.xlsxのExcelファイル
Excelは選択したセルの合計を自動的に計算してくれますが、それでも手動で3000以上の郡のセルを選択しなければなりません。手動で一つの郡の集計をするのは数秒だとしても、ファイル全体のすべての郡の集計をするには何時間もかかります。
このプロジェクトでは、国勢調査のExcelファイルから読み取って各郡の集計を数秒で行うスクリプトを書きます。
このプログラムには以下の内容が必要です。
- Excelファイルからデータを読み取る
- 各郡の国勢統計区の数を集計する
- 各郡の人口を集計する
- 結果を表示する
コードには以下の内容が必要になります。
- openpyxlモジュールでExcelファイルを開いてセルを読み取る
- すべての国勢統計区と人口を集計し、データ構造に格納する
- あとでインポートできるように、pprintモジュールを使って、データ構造を拡張子.pyのテキストファイルに書き出す
ステップ1:Excelファイルのデータを読み取る
censuspopdata.xlsxファイルには、'Population by Census Tract'という名前の一つのシートしかありません。そのシートの各行には、一つの国勢統計区のデータが入っています。列は、国勢統計区(A)、州の略称(B)、郡の名前(C)、その国勢統計区の人口(D)です。
新しいファイルエディタタブを開いて、以下のコードをreadCensusExcel.pyという名前で保存してください。
# readCensusExcel.py - 郡の人口と国勢統計区を集計する
❶ import openpyxl, pprint
print('Opening workbook...')
❷ wb = openpyxl.load_workbook('censuspopdata.xlsx')
❸ sheet = wb['Population by Census Tract']
county_data = {}
# TODO: county_dataを各郡の人口と国勢統計区で埋める
print('Reading rows...')
❹ for row in range(2, sheet.max_row + 1):
# Excelファイルの各行は一つの国勢統計区のデータ
state = sheet['B' + str(row)].value
county = sheet['C' + str(row)].value
pop = sheet['D' + str(row)].value
# TODO: 新しいテキストファイルにcounty_dataの内容を書き込む
このコードは、openpyxlモジュールと、最終的な郡のデータを出力するのに使うpprintモジュールをインポートしています(❶)。次に、censuspopdata.xlsxファイルを開き(❷)、国勢調査データが入ったシートを取得します(❸)。そして、各行を反復処理します(❹)。
county_dataという名前の変数を作成していることに注目してください。この変数に郡ごとに集計する人口と国勢統計区数を格納します。変数にデータを格納する前に、どのようなデータ構造にするかを決める必要があります。
ステップ2:データ構造にデータを投入する
合衆国では、州には2文字の略称があり、州はさらに郡へと細分化されます。county_dataに格納されるデータ構造は、州の略称をキーとする辞書です。州の略称は、その州の郡の名前をキーとする別の辞書へと対応づけられます。各郡の名前は、'tracts'と'pop'という2つのキーを持つ辞書へと対応づけられます。これらのキーは、その郡の国勢統計区数と人口へと対応づけられます。この辞書は次のような構造をしています。
{'AK': {'Aleutians East': {'pop': 3141, 'tracts': 1},
'Aleutians West': {'pop': 5561, 'tracts': 2},
'Anchorage': {'pop': 291826, 'tracts': 55},
'Bethel': {'pop': 17013, 'tracts': 3},
'Bristol Bay': {'pop': 997, 'tracts': 1},
--snip--
この辞書がcounty_dataに格納されているとすると、以下の式はこのように評価されます。
>>> county_data['AK']['Anchorage']['pop']
291826
>>> county_data['AK']['Anchorage']['tracts']
55
一般化すると、辞書county_dataのキーは次のとおりです。
county_data[state abbrev][county]['tracts']
county_data[state abbrev][county]['pop']
county_dataの構造がわかったので、郡のデータでこの変数を埋めていくコードを書けます。プログラムの末尾に以下のコードを追加してください。
# readCensusExcel.py - 郡の人口と国勢統計区を集計する
--snip--
for row in range(2, sheet.max_row + 1):
# Excelファイルの各行は一つの国勢統計区のデータ
state = sheet['B' + str(row)].value
county = sheet['C' + str(row)].value
pop = sheet['D' + str(row)].value
# 州のキーが存在することを保証する
❶ county_data.setdefault(state, {})
# 郡のキーが存在することを保証する
❷ county_data[state].setdefault(county, {'tracts': 0, 'pop': 0})
# 各行は一つの国勢統計区のデータなので1増やす
❸ county_data[state][county]['tracts'] += 1
# この国勢統計区の人口分だけ郡の人口を増やす
❹ county_data[state][county]['pop'] += int(pop)
# TODO: 新しいテキストファイルにcounty_dataの内容を書き込む
コードの最後の2行で実際の集計作業を行っています。forループの反復ごとに、その郡について、tractsの値を1増やし(❸)、popの値を加算しています(❹)。
コードのその他の部分は、州の略称のキーがcounty_dataに存在していなければ、その州の値として郡の辞書を追加できないという問題に対応するためのものです('AK'キーが存在しなければcounty_data['AK']['Anchorage']['tracts'] += 1がエラーを引き起こします)。データ構造に州の略称のキーが存在することを保証するために、stateが存在しなければ値を設定するsetdefault()メソッドを呼び出す必要があります(❶)。
辞書county_dataには各州の略称をキーとする値として辞書が必要なのと同じように、その辞書にはそれぞれ郡をキーとする値としての辞書が必要です(❷)。そして、今度はその辞書に関して、'tracts'と'pop'のキーが0で始まる値が必要になります。(この説明の辞書の構造を追えなかったら、本節の冒頭に示した例に戻って考えてください。)
キーがすでに存在する場合に、setdefault()は何もしないので、forループの反復ごとに呼び出しても問題ありません。
ステップ3:結果をファイルに書き込む
forループが終わったら、辞書county_dataには、郡と州をキーとする、すべての人口と国勢統計区情報が含まれています。このデータをテキストファイルや別のExcelファイルに書き出すコードを書くこともできますが、今はpprint.pformat()関数で辞書county_dataの値をcensus2010.pyという名前のファイルに大きな文字列として書き込みましょう。以下のコードをプログラムの末尾に追加してください(forループの外側になるようにインデントしないことに注意してください)。
# readCensusExcel.py - 郡の人口と国勢統計区を集計する
--snip--
# 新しいテキストファイルにcounty_dataの内容を書き込む
print('Writing results...')
result_file = open('census2010.py', 'w')
result_file.write('allData = ' + pprint.pformat(county_data))
result_file.close()
print('Done.')
pprint.pformat()関数は、Pythonコードとして使えるように文字列をフォーマットします。それをcensus2010.pyという名前のテキストファイルに出力することにより、PythonプログラムがらPythonプログラムを生成しました。これは複雑に思われるかもしれませんが、こうすれば他のPythonモジュールと同じようにcensus2010.pyをインポートできます。対話型シェルで現在の作業ディレクトリを新しく作成したcensus2010.pyファイルがあるフォルダに移動してインポートしてください。
>>> import census2010
>>> census2010.allData['AK']['Anchorage']
{'pop': 291826, 'tracts': 55}
>>> anchorage_pop = census2010.allData['AK']['Anchorage']['pop']
>>> print('The 2010 population of Anchorage was ' + str(anchorage_pop))
The 2010 population of Anchorage was 291826
readCensusExcel.pyプログラムは使い捨てのコードです。結果をcensus2010.pyに保存すれば、プログラムを二度と実行する必要がありません。郡のデータが必要になれば、import census2010を実行するだけでよいです。
手動でこのデータを集計すると何時間もかかります。このプログラムなら数秒で集計できます。openpyxlを使うと、苦もなくExcelファイルに保存されている情報を抽出して計算できます。本書のオンライン素材からこのプログラム全体をダウンロードできます。
似たようなプログラムのアイデア
仕事でExcelを使ってさまざまなデータを保存することは多く、Excelファイルが大きくなりすぎて手に負えなくなることも珍しくありません。Excelファイルを解析するプログラムはどれも似たような構成になります。Excelファイルを読み込み、変数やデータ構造を用意して、Excelファイルの各行をループするという構成です。そうしたプログラムで以下のような作業を行えます。
- Excelファイルの複数の行のデータを比較する
- 複数のExcelファイルを開いてファイル間のデータを比較する
- Excelファイルに空行など不適切なデータがあるかどうかを確認し、あれば警告を発する
- Excelファイルからデータを読み取り、Pythonプログラムの入力として使う
Excelファイルの書き込み
openpyxlモジュールを使うとデータの書き込みもできます。プログラムからExcelファイルを作成したり編集したりできるということです。Pythonでは、数千行のデータがあるExcelファイルでも簡単に作成できます。
Excelファイルの作成と保存
openpyxl.Workbook()関数を呼び出すと、新しい空白のWorkbookオブジェクトを作成します。以下の式を対話型シェルに入力してみてください。
>>> import openpyxl
>>> wb = openpyxl.Workbook() # 空白のワークブックを作成
>>> wb.sheetnames # ワークブックには1シートある
['Sheet']
>>> sheet = wb.active
>>> sheet.title
'Sheet'
>>> sheet.title = 'Spam Bacon Eggs Sheet' # シート名の変更
>>> wb.sheetnames
['Spam Bacon Eggs Sheet']
ワークブックにはSheetという名前の1シートがあります。title属性に文字列を格納すると、そのシートの名前を変更できます。
Workbookオブジェクトやそのシートまたはセルを変更しても、save()ワークブックメソッドを呼び出すまではExcelファイルが保存されません。以下の式を対話型シェルに入力してみてください。(example3.xlsxが現在の作業ディレクトリにあることを前提としています。)
>>> import openpyxl
>>> wb = openpyxl.load_workbook('example3.xlsx')
>>> sheet = wb['Sheet1']
>>> sheet.title = 'Spam Spam Spam'
>>> wb.save('example3_copy.xlsx') # ワークブックの保存
ここではシート名を変更しています。ファイル名を文字列でsave()メソッドに渡して、その変更を保存しています。'example3_copy.xlsx'のような、元のファイル名とは異なるファイル名を渡すと、変更したファイルを別のExcelファイルに保存します。
ファイルから読み込んだExcelファイルを編集するときは、常に元ファイルとは別の名前で新しい編集後のExcelファイルを保存するようにしてください。そうすれば、コードにバグがあって新しく保存したファイルのデータを破損していたとしても、元のExcelファイルから作業をやり直せます。また、save()メソッドはExcelファイルがデスクトップアプリケーションで開かれていると機能しません。Excelファイルを閉じてからPythonプログラムを実行してください。
シートの作成と削除
create_sheet()メソッドでワークブックからシートを作成し、del演算子でシートを削除します。以下の式を対話型シェルに入力してみてください。
>>> import openpyxl
>>> wb = openpyxl.Workbook()
>>> wb.sheetnames
['Sheet']
>>> wb.create_sheet() # 新しいシートの追加
<Worksheet "Sheet1">
>>> wb.sheetnames
['Sheet', 'Sheet1']
>>> # インデックス0に新しいシートを作成
>>> wb.create_sheet(index=0, title='First Sheet')
<Worksheet "First Sheet">
>>> wb.sheetnames
['First Sheet', 'Sheet', 'Sheet1']
>>> wb.create_sheet(index=2, title='Middle Sheet')
<Worksheet "Middle Sheet">
>>> wb.sheetnames
['First Sheet', 'Sheet', 'Middle Sheet', 'Sheet1']
create_sheet()メソッドは、SheetX(Xにはそのワークブックで最後の番号が入ります)という名前の新しいWorksheetオブジェクトを返します。新しいシートのインデックスと名前をそれぞれindexとtitleのキーワード引数で指定することもできます。
前の例から続けて以下の内容を入力してください。
>>> wb.sheetnames
['First Sheet', 'Sheet', 'Middle Sheet', 'Sheet1']
>>> del wb['Middle Sheet']
>>> del wb['Sheet1']
>>> wb.sheetnames
['First Sheet', 'Sheet']
del演算子でワークブックからシートを削除できます。辞書からキーと値のペアを削除するのと同じ要領です。
ワークブックでシートの作成や削除をしたら、save()メソッドを呼び出してその変更を保存します。
セルへの値の書き込み
セルへの値の書き込みは、辞書のキーに値を書き込むのと同じです。以下の式を対話型シェルに入力してみてください。
>>> import openpyxl
>>> wb = openpyxl.Workbook()
>>> sheet = wb['Sheet']
>>> sheet['A1'] = 'Hello, world!' # セルの値を編集
>>> sheet['A1'].value
'Hello, world!'
セル座標の文字列をWorksheetオブジェクトの辞書のキーのように用いることで、セルを指定して値を書き込めます。
プロジェクト10:Excelファイルの更新
このプロジェクトでは、農産物売上Excelファイル中のセルを更新するプログラムを書きます。Excelファイルから特定の種類の農産物を見つけ出して、その価格を更新します。本書のオンライン素材からこのproduceSales3.xlsxのExcelファイルをダウンロードしてください。図14-3はそのExcelファイルを示しています。
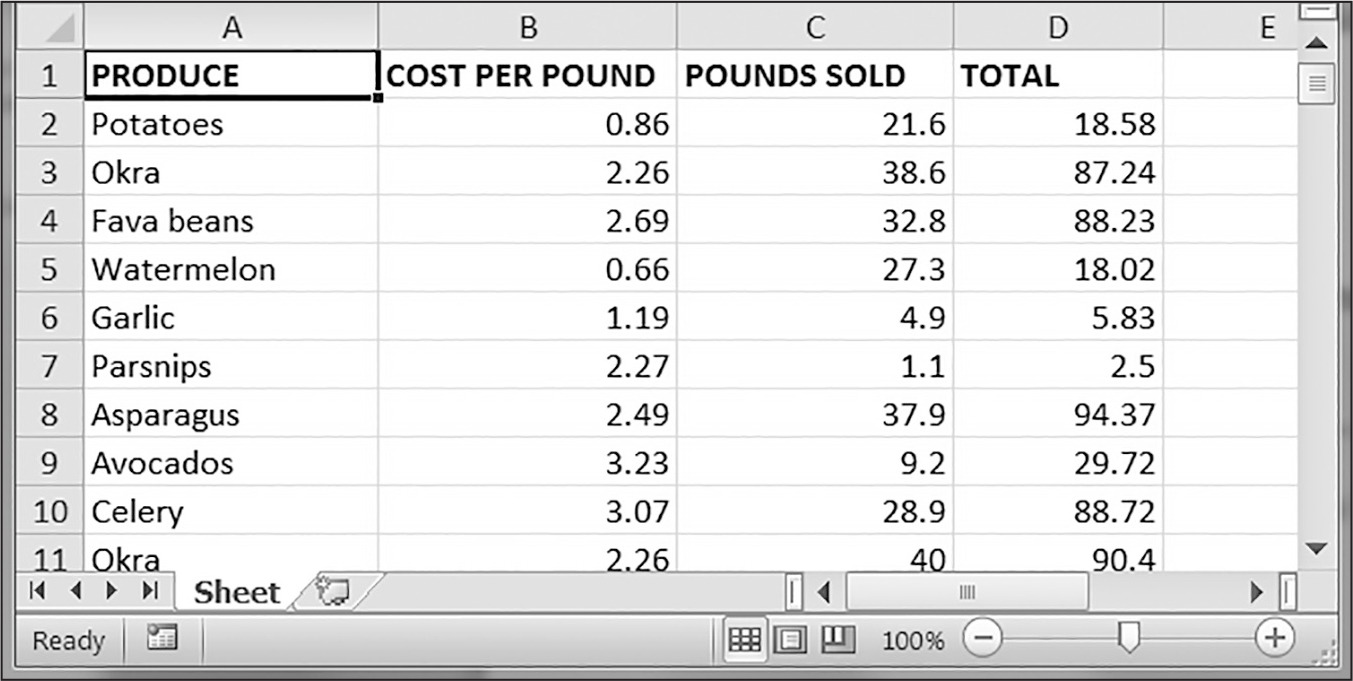
図 14-3:農産物売上のExcelファイル
各行がそれぞれの売上を表しています。列は、農産物の種類(A)、1ポンドあたりの価格(B)、販売ポンド数(C)、総売上(D)です。総売上の列には、=ROUND(B2*C2, 2)のような、その行の1ポンドあたりの価格と販売ポンド数をかけ算して小数第2位で丸めるExcelの数式が設定されています。この数式により、総売上列のセルは、1ポンドあたりの価格(B)列と販売ポンド数(C)列に変更があれば自動的に更新されます。
garlic(にんにく)、celery(セロリ)、lemons(レモン)の価格を誤って入力してしまっていたことに気づきました。このExcelファイルの数千行に目を通してgarlic、celery、lemonsの行の価格を更新するという退屈な作業をしなければなりません。価格を単純に置換することはできません。というのも、同じ価格の別の農産物があるかもしれず、これを更新したくはないからです。数千行もあれば手動だと数時間はかかるでしょう。しかしプログラムを書けば数秒でその作業を実行できます。
このプログラムには以下の内容が必要です。
- 各行をループ処理する
- garlic、celery、lemonsの行であれば、価格を更新する
コードには以下の内容が必要になります。
- Excelファイルを開く
- 各行について、A列の値がCelery、Garlic、Lemonであるかどうかを確認する
- 該当すればB列の価格を更新する
- Excelファイルを新しいファイルに保存する(万一の場合に元ファイルの情報を保持できるように)
ステップ1:更新する情報のデータ構造を定める
更新する必要のある価格は次のとおりです。
- Celery: 1.19
- Garlic: 3.07
- Lemon: 1.27
この新しい(正しい)価格を、次のようにコードに書くことができます。
if produce_name == 'Celery':
cell_obj = 1.19
if produce_name == 'Garlic':
cell_obj = 3.07
if produce_name == 'Lemon':
cell_obj = 1.27
しかし、このように農産物の更新後の価格をハードコードするのは美しくありません。別の農産物について別の価格でExcelファイルをまた更新する必要が生じたときに、コードを何箇所も変更しなければなりません。コードを変更する箇所が多ければ多いほど、バグの可能性が高くなります。
正しい価格情報を辞書に保存し、コードでそのデータ構造を使うと、もっと柔軟に解決できます。新しいファイルエディタのタブで次のコードを入力してください。
# updateProduce.py - 農産物売上Excelファイルの価格を修正
import openpyxl
wb = openpyxl.load_workbook('produceSales3.xlsx')
sheet = wb['Sheet']
# 農産物の種類と更新後の価格
PRICE_UPDATES = {'Garlic': 3.07,
'Celery': 1.19,
'Lemon': 1.27}
# TODO: 行をループして価格を更新
これをupdateProduce.pyという名前で保存してください。Excelファイルをまた更新する必要が生じても、辞書PRICE_UPDATESを更新するだけですみ、コードの他の部分はそのままで大丈夫です。
ステップ2:すべての行を確認して誤った価格を更新する
プログラムの次の部分では、Excelファイルのすべての行をループで反復処理します。updateProduce.pyの末尾に次のコードを追加してください。
# updateProduce.py - 農産物売上Excelファイルの価格を修正
--snip--
# 行をループして価格を更新
❶ for row_num in range(2, sheet.max_row + 1): # 最初の行は飛ばす
❷ produce_name = sheet.cell(row=row_num, column=1).value
❸ if produce_name in PRICE_UPDATES:
sheet.cell(row=row_num, column=2).value = PRICE_UPDATES[produce_name]
❹ wb.save('updatedProduceSales3.xlsx')
1行目はヘッダー(見出し)なので、2行目からループを開始します(❶)。1列目(A列)のセルの値を変数produce _nameに格納します(❷)。produce_nameが辞書PRICE_UPDATESのキーに存在すれば(❸)、この行は価格を更新する必要があるとわかります。正しい価格はPRICE _UPDATES[produce_name]です。
PRICE_UPDATESを使うとコードがとてもクリーンになったことがおわかりでしょう。if produce_name == 'Garlic':のように更新する農産物ごとにifの行を書くのではなく、if文は1つだけになります。そして、ソースコードでは農産物の種類と正しい価格をforループにハードコードせずに辞書PRICE_UPDATESを使っているため、価格をさらに変更する必要が生じたとしても、辞書PRICE_UPDATESを修正するだけですみ、コードの残りの部分は変更する必要がありません。
Excelファイル全体の処理が終われば、WorkbookオブジェクトをupdatedProduceSales3.xlsxに保存します(❹)。万一プログラムにバグがあり更新後のExcelファイルがおかしくなっているといけないので、古いExcelファイルを上書きしないようにしています。更新後のExcelファイルを確認して正しく作成されていれば、古いExcelファイルを削除できます。
似たようなプログラムのアイデア
事務関係の仕事をする人はExcelファイルをしょっちゅう使いますから、自動的にExcelファイルを編集して書き込めるプログラムは大いに役立つでしょう。そうしたプログラムで以下のような作業を行えます。
- 一つのExcelファイルからデータを読み取り、別のExcelファイルに書き込む
- ウェブサイト、テキストファイル、クリップボードからデータを読み取り、Excelファイルに書き込む
- 自動的にExcelファイルのデータを整理する。例えば、正規表現を使って電話番号の複数のフォーマットを読み取り、標準的なフォーマットに統一する。
セルのフォントスタイルを設定する
特定のセルや行や列のスタイルを設定できれば、Excelファイルで重要な箇所を強調するのに役立ちます。例えば、先ほどの農産物Excelファイルで、potato(じゃがいも)、garlic(にんにく)、parsnip(白ニンジン)の行を太字にすることができます。あるいは、1ポンドあたりの価格が5ドルよりも大きい行をすべて斜体にしたいことがあるかもしれません。大きなExcelファイルの一部を手動でスタイル設定するのは面倒ですが、プログラムなら一瞬でその作業をしてくれます。
セルのフォントスタイルを調整するには、openpyxl.stylesモジュールからFont()関数をインポートします。
from openpyxl.styles import Fontこの関数をこのようにインポートすると、openpyxl.styles.Font()ではなくFont()と書けます(詳しくは第3章の「モジュールのインポート」を参照してください)。
以下の例では、新しいワークブックを作成し、A1セルを24ポイントの斜体に設定しています。
>>> import openpyxl
>>> from openpyxl.styles import Font
>>> wb = openpyxl.Workbook()
>>> sheet = wb['Sheet']
❶ >>> italic_24_font = Font(size=24, italic=True)
❷ >>> sheet['A1'].font = italic_24_font
>>> sheet['A1'] = 'Hello, world!'
>>> wb.save('styles3.xlsx')
この例で、Font(size=24, italic=True)はFontオブジェクトを返します。それを italic_24_fontに格納しています(❶)。Font()のキーワード引数でこのオブジェクトのスタイル情報を設定でき、sheet['A1'].fontにitalic _24_fontオブジェクトを代入しています(❷)。これにより、フォントスタイルの情報がすべてA1セルに適用されます。
font属性を設定するには、Font()にキーワード引数を渡します。表14-2はFont()関数に渡せるキーワード引数を示しています。
キーワード引数 |
データ型 |
説明 |
|---|---|---|
name |
文字列 |
'Calibri'や'Times New Roman'のようなフォント名 |
size |
整数 |
フォントサイズ |
bold |
ブール |
Trueで太字に |
italic |
ブール |
Trueで斜体に |
Font()を呼び出してFontオブジェクトを作成し、そのFontオブジェクトを変数に格納します。その変数をCellオブジェクトのfont属性に代入します。以下のコードではさまざまなフォントスタイルを作成しています。
>>> import openpyxl
>>> from openpyxl.styles import Font
>>> wb = openpyxl.Workbook()
>>> sheet = wb['Sheet']
>>> bold_font = Font(name='Times New Roman', bold=True)
>>> sheet['A1'].font = bold_font
>>> sheet['A1'] = 'Bold Times New Roman'
>>> italic_font = Font(size=24, italic=True)
>>> sheet['B3'].font = italic_font
>>> sheet['B3'] = '24 pt Italic'
>>> wb.save('styles3.xlsx')
bold_fontにFontオブジェクトを格納して、A1のCellオブジェクトのfont属性にbold_fontを設定しています。別のFontオブジェクトで同じことを繰り返し、2つ目のセルにフォントを設定しています。このコードを実行すると、ExcelファイルのA1セルとB3セルのスタイルは、図14-4のように調整されています。

図 14-4:フォントスタイルを調整したExcelファイル
A1セルには'Times New Roman'という名前のフォントでboldをtrueに設定しました。よって、テキストは太字のTimes New Romanになっています。サイズは指定しなかったので、openpyxlのデフォルトの11です。B3セルは、テキストが斜体でサイズが24になっています。フォント名は指定しませんでしたから、openpyxlのデフォルトのCalibriになっています。
数式
Excelの数式は、イコール記号で始まり、別のセルを参照した計算結果の値を設定できます。この節では、openpyxlモジュールをプログラムで使用してセルに数式を書き込みます。通常の値を書き込むのと同じ要領です。例を示します。
>>> sheet['B9'] = '=SUM(B1:B8)'このコードはB9に=SUM(B1:B8)という数式を入れます。このセルの値はB1セルからB8セルまでの値の合計値になります。図14-5にその様子を示します。
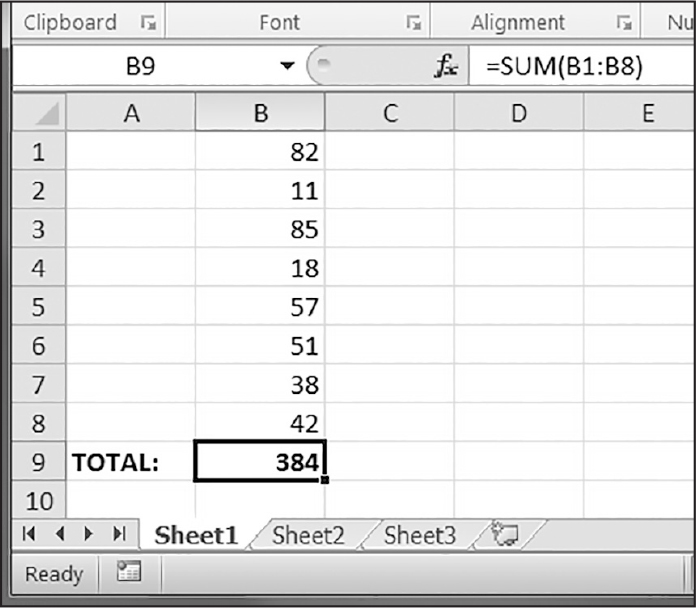
図 14-5:B9セルにはB1セルからB8セルまでを合計する数式が入っている
Excelの数式をほかのテキスト値と同じようにセルに入れられます。例えば、次のように対話型シェルに入力してください。
>>> import openpyxl
>>> wb = openpyxl.Workbook()
>>> sheet = wb['Sheet']
>>> sheet['A1'] = 200
>>> sheet['A2'] = 300
>>> sheet['A3'] = '=SUM(A1:A2)' # 数式を設定
>>> wb.save('writeFormula3.xlsx')
A1セルには200、A2セルには300を入れます。A3セルにはA1セルとA2セルの値を合計する数式を入れます。Excelファイルを開くと、A3には500という値が表示されます。
openpyxlモジュールにはExcelの数式を計算してその結果をセルに入れる機能はありません。しかし、writeFormula3.xlsxファイルをExcelで開くと、Excelが数式の計算結果を入れてくれます。Excelファイルを保存し、data_only=Trueキーワード引数をopenpyxl.load_workbook()に渡してそのExcelファイルを開けば、セルの値は数式を表す文字列ではなく計算結果になります。
>>> # 先にwriteFormula3.xlsxをExcelで開いて保存してから以下のコードを実行する
>>> import openpyxl
>>> wb = openpyxl.load_workbook('writeFormula3.xlsx') # data_onlyなしで開く
>>> wb.active['A3'].value # 数式の文字列を取得
'=SUM(A1:A2)'
>>> wb = openpyxl.load_workbook('writeFormula3.xlsx', data_only=True) # data_onlyありで開く
>>> wb.active['A3'].value # 数式の計算結果を取得
500
このExcelファイルをExcelで開いて保存してからでないと、500 という結果は表示されません。Excelは数式を計算してその結果をExcelファイルに保存します。openpyxl.load_workbook()にdata_only=Trueを渡すと、openpyxlがその値を読み取ります。
Excelの数式を使うと一定程度のプログラミングができますが、複雑な作業になるとすぐに扱いきれなくなります。例えば、Excelの数式の熟練者でも、=IFERROR(TRIM(IF(LEN(VLOOKUP(F7, Sheet2!$A$1:$B$10000, 2, FALSE))>0,SUBSTITUTE(VLOOKUP(F7, Sheet2!$A$1:$B$10000, 2, FALSE), " ", ""),"")), "")を解読するのに苦労するでしょう。Pythonのコードははるかに読みやすいです。
行と列を調整する
Excelでは、行や列の見出し部分をクリックしてドラッグすれば簡単に行や列のサイズを調整できます。しかしセルの内容に基づいて行や列のサイズを設定する必要がある場合や、多数のExcelファイルの行や列のサイズを調整する必要がある場合は、Pythonのプログラムを書いたほうが早いです。
行や列を非表示にしたり、常に画面に表示して印刷の各ページに表示されるようにその場所に固定したりすることもできます(見出しに使えます)。
行の高さと列の幅を設定する
Worksheetオブジェクトには、行の高さを制御するrow_dimensions属性と、列の幅を制御するcolumn_dimensions属性があります。対話型シェルで次のように入力してみてください。
>>> import openpyxl
>>> wb = openpyxl.Workbook()
>>> sheet = wb['Sheet']
>>> sheet['A1'] = 'Tall row'
>>> sheet['B2'] = 'Wide column'
>>> sheet.row_dimensions[1].height = 70
>>> sheet.column_dimensions['B'].width = 20
>>> wb.save('dimensions3.xlsx')
シートのrow_dimensionsとcolumn_dimensionsは辞書のような値です。row_dimensionsはRowDimensionオブジェクトを含み、column_dimensionsはColumnDimensionオブジェクトを含みます。row_dimensionsでは、行番号(この例では1や2)でそのオブジェクトにアクセスできます。column_dimensionsでは、列を表す文字(この例ではAやB)でそのオブジェクトにアクセスできます。
dimensions3.xlsxのExcelファイルは、図14-6のように見えます。

図 14-6:1行目の高さとB列の幅を広げた様子
デフォルトの高さと幅はExcelやopenpyxlのバージョンによって異なります。
セルの結合と結合の解除
merge _cells()シートメソッドで長方形の範囲のセルを一つのセルに結合できます。以下の式を対話型シェルに入力してみてください。
>>> import openpyxl
>>> wb = openpyxl.Workbook()
>>> sheet = wb['Sheet']
>>> sheet.merge_cells('A1:D3') # この範囲のセルを結合
>>> sheet['A1'] = 'Twelve cells merged together.'
>>> sheet.merge_cells('C5:D5') # 2つのセルを結合
>>> sheet['C5'] = 'Two merged cells.'
>>> wb.save('merged3.xlsx')
merge_cells()の引数は、結合する長方形の範囲の左上から右下のセルを表す一つの文字列です。'A1:D3'だと12個のセルを一つのセルに結合します。この結合したセルに値を入れるときは、結合したセルの左上のセルに値を入れます。
このコードを実行すると、merged.xlsxは図14-7のように見えます。

図 14-7:結合したセル
unmerge_cells()シートメソッドを呼び出すと、セルの結合を解除します。
>>> import openpyxl
>>> wb = openpyxl.load_workbook('merged3.xlsx')
>>> sheet = wb['Sheet']
>>> sheet.unmerge_cells('A1:D3') # セルの結合を解除
>>> sheet.unmerge_cells('C5:D5')
>>> wb.save('unmerged3.xlsx')
この変更を保存してExcelファイルを確認すると、結合したセルが元のセルに分割されていることがわかります。
ウィンドウ枠の固定
一画面に収まらないほど大きなExcelファイルでは、一番上の行や一番左の列を「固定」すると見やすくなります。固定した列や行の見出しは、Excelファイルをスクロールしても常に表示されたままです。これはウィンドウ枠の固定と呼ばれます。
openpyxlでは、各Worksheetオブジェクトにfreeze_panes属性があり、この属性にCellオブジェクトまたはセルの座標を表す文字列を設定します。この属性はそのセルより上の行と左の列をすべて固定しますが、指定したセル自体は固定されません。freeze _panesにNoneまたは'A1'を設定すると、ウィンドウ枠の固定を解除します。表14-3は、どの行と列が固定されるかのfreeze_panesの設定例を示しています。
freeze_panesの設定 |
固定される行と列 |
|---|---|
sheet.freeze_panes = 'A2' |
1行目(列は固定されない) |
sheet.freeze_panes = 'B1' |
A列(行は固定されない) |
sheet.freeze_panes = 'C1' |
A列とB列(業は固定されない) |
sheet.freeze_panes = 'C2' |
1行目とA列とB列 |
sheet.freeze_panes = 'A1' or sheet.freeze_panes = None |
行と列の固定なし |
produceSales3.xlsxをダウンロードして、対話型シェルに次のように入力してください。
>>> import openpyxl
>>> wb = openpyxl.load_workbook('produceSales3.xlsx')
>>> sheet = wb.active
>>> sheet.freeze_panes = 'A2' # A2より上の行を固定
>>> wb.save('freezeExample3.xlsx')
図14-8に結果を示します。
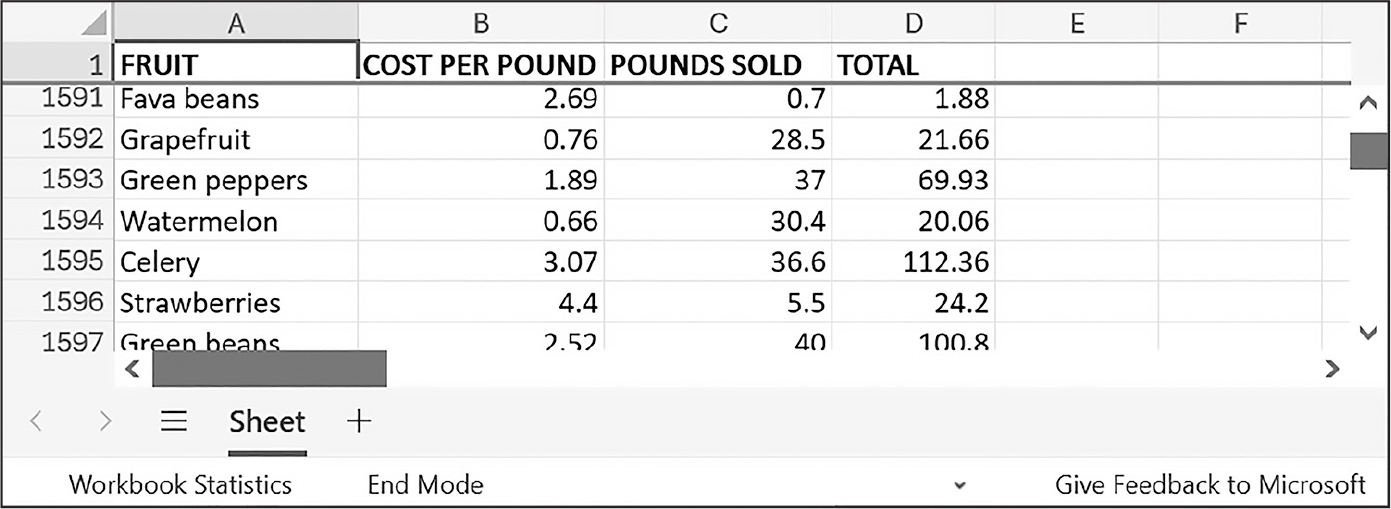
図 14-8:1行目を固定
freeze_panes属性を'A2'に設定したので、Excelファイルをどこまでスクロールしても1行目が常に表示されます。
グラフ
openpyxlモジュールは、シートのセルに入ったデータを使った、棒グラフ、折れ線グラフ、散布図、円グラフの作成に対応しています。以下の手順でグラフを作成できます。
1. セルの長方形の範囲を選択してReferenceオブジェクトを作成する
2. Referenceオブジェクトを渡してSeriesオブジェクトを作成する
3. Chartオブジェクトを作成する
4. ChartオブジェクトにSeriesオブジェクトを追加する
5. WorksheetオブジェクトにChartオブジェクトを追加する(オプションでグラフの左上が位置するセルを指定する)
Referenceオブジェクトについては説明が必要でしょう。openpyxl.chart.Reference()関数に以下の5つの引数を渡してReferenceオブジェクトを作成します。
- グラフのデータを含むWorksheetオブジェクト
- グラフのデータを含む長方形の範囲のセルの左上のセルの行番号と列番号(行番号、列番号という順番で、0ではなく1始まり)
- グラフのデータを含む長方形の範囲のセルの右下のセルの行番号と列番号(行番号、列番号という順番で、0ではなく1始まり)
対話型シェルに以下の内容を入力して、棒グラフをExcelファイルに作成してみましょう。
>>> import openpyxl
>>> wb = openpyxl.Workbook()
>>> sheet = wb.active
>>> for i in range(1, 11): # A列にデータを作成
... sheet['A' + str(i)] = i * i
...
>>> ref_obj = openpyxl.chart.Reference(sheet, 1, 1, 1, 10)
>>> series_obj = openpyxl.chart.Series(ref_obj, title='First series')
>>> chart_obj = openpyxl.chart.BarChart()
>>> chart_obj.title = 'My Chart'
>>> chart_obj.append(series_obj)
>>> sheet.add_chart(chart_obj, 'C5')
>>> wb.save('sampleChart3.xlsx')
このコードを実行すると、図14-9のようなExcelファイルが作成されます。
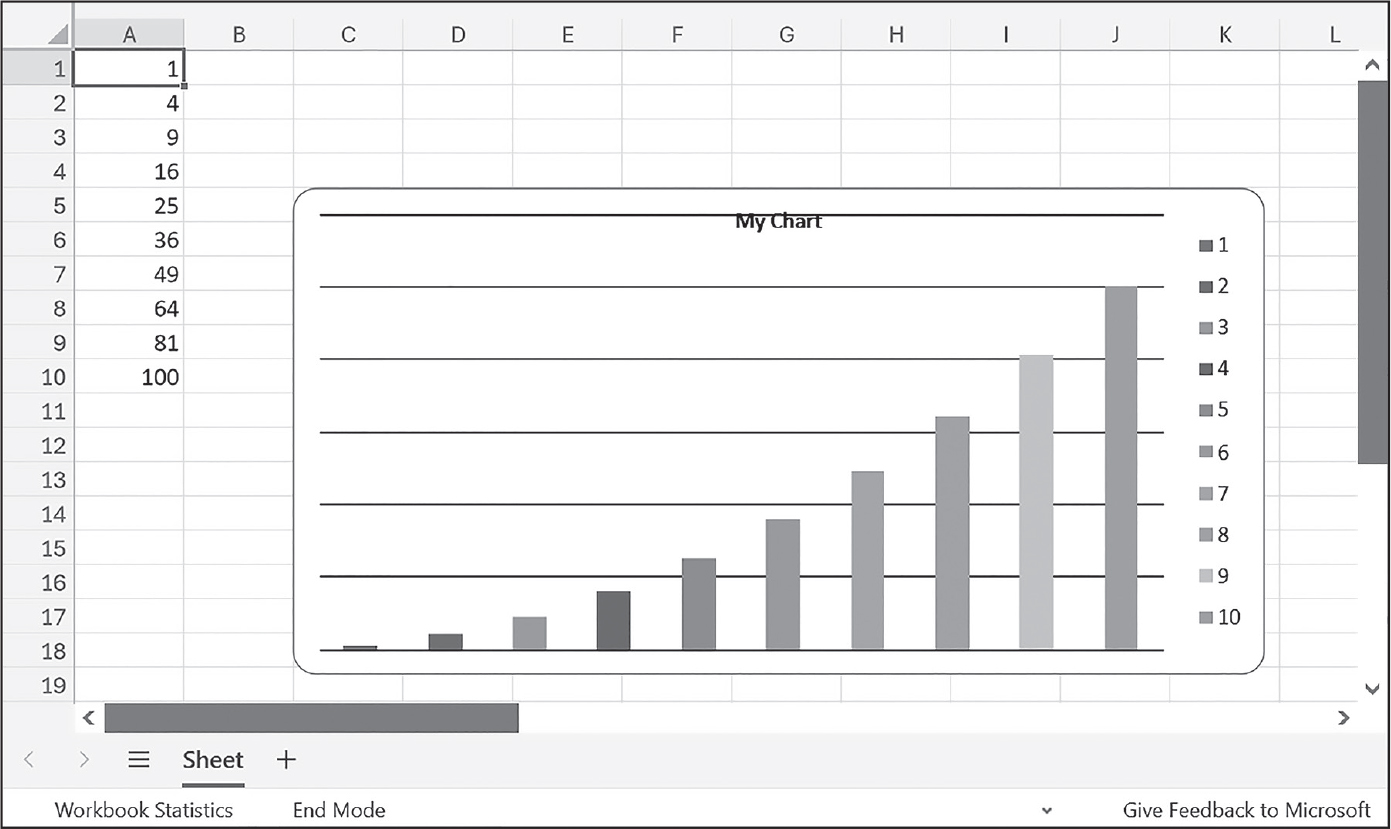
図 14-9:グラフを追加したExcelファイル
openpyxl.chart.BarChart()を呼び出して棒グラフを作成しました。openpyxl.chart .LineChart()で折れ線グラフ、openpyxl.chart.ScatterChart()で散布図、openpyxl.chart.PieChart()で円グラフを作成できます。
まとめ
情報処理の難しい部分は、情報処理そのものではなく、データの正しい形式での入手であることが多いです。ExcelファイルをPythonで読み込めば、手動で行うよりもずっと速くデータを抽出して操作できます。
プログラムの出力としてもExcelファイルを使うことができます。テキストファイルやPDFファイルから何千もの連絡先をExcelファイルに移す必要があったとしても、退屈なコピーアンドペーストなどしなくてよいです。openpyxlモジュールとプログラミングの知識がいくらかあれば、もっと大きなExcelファイルの処理でも朝飯前です。
次章では、Pythonを使って、Googleスプレッドシートという、もう一つのスプレッドシートプログラムを扱います。
練習問題
以下の練習問題では、変数wbにWorkbookオブジェクトが、変数sheetにWorksheetオブジェクトが格納されていることを前提にしてください。
1. openpyxl.load_workbook()関数は何を返しますか?
2. wb.sheetnamesワークブック属性には何が含まれていますか?
3. 'Sheet1'という名前のシートのWorksheetオブジェクトはどのように取得しますか?
4. ワークブックのアクティブシートのWorksheetオブジェクトはどのように取得しますか?
5. C5セルの値はどのように取得しますか?
6. C5セルに"Hello"という値をどのように設定しますか?
7. セルの行番号と列番号をどのように取得しますか?
8. sheet.max_columnとsheet.max_rowのシート属性には何が入っていて、そのデータ型は何ですか?
9. 'M'列の列番号が知りたいときに、どの関数を呼び出しますか?
10. 14列目のアルファベットが知りたいときに、どの関数を呼び出しますか?
11. A1からF1のCellオブジェクトをすべてタプルで取得するにはどうしますか?
12. ワークブックをexample3.xlsxという名前で保存するにはどうしますか?
13. セルに数式を設定するにはどうしますか?
14. セルの数式ではなく数式の計算結果を取得したいときに、まずどうしますか?
15. 5行目の高さを100に設定するにはどうしますか?
16. C列を非表示にするにはどうしますか?
17. ウィンドウ枠の固定とは何ですか?
18. 棒グラフを作成するのに呼び出す5つの関数とメソッドを挙げてください。
練習プログラム
以下の練習プログラムを書いてください。
かけ算表の作成
コマンドラインから数値Nを取り、N×Nのかけ算表をExcelファイルで作成するmultiplicationTable.pyというプログラムを作成してください。例えば、このように呼び出すと、
py multiplicationTable.py 6図14-10のようなExcelファイルを作成します。
図 14-10:かけ算表が作成されたExcelファイル
1行目とA列はラベルなので太字にしてください。
空行挿入
2つの整数とファイル名の文字列を取る、blankRowInserter.pyという名前のプログラムを作成してください。最初の整数をN、2番目の整数をMとします。このプログラムは、ExcelファイルのN行目からM行分空行を挿入します。例えば、このように呼び出すと、
python blankRowInserter.py 3 2 myProduce.xlsx実行前と実行後のExcelファイルは図14-11のようになります。
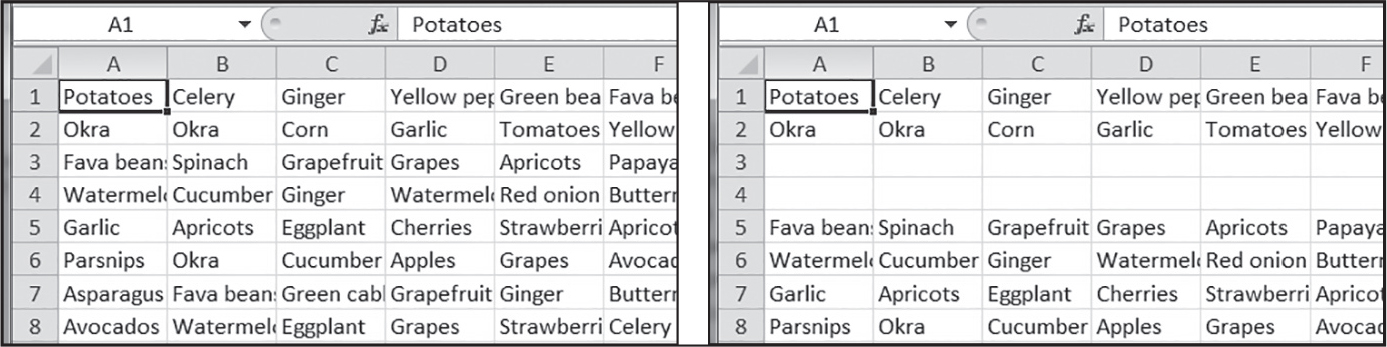
図 14-11:3行目に2行分の空行挿入の実行前(左)と実行後(右)
指定されたExcelファイルを読み取り、新しいExcelファイルに書き込みます。forループで最初のN行をコピーして、残りの行はM行分だけ繰り下げて書き込みます。