10 ファイルの読み書き

プログラムの実行中にデータを保存するには変数で事足りますが、プログラムの終了後もデータを保存しておく必要があるなら、ファイルに保存する必要があります。ファイルの内容は、ギガバイト単位のサイズになる可能性もありますが、一つの文字列だと考えることができます。本章では、Pythonでハードドライブ上のファイルを作成、読み取り、保存(書き込み)する方法を説明します。
ファイルとファイルパス
ファイルには2つの主要なプロパティがあります。ファイル名(通常は1単語)とパスです。パスはそのファイルがコンピュータ上に存在する場所です。例えば、私のWindowsノートPCには、パスC:\Users\Al\Documentsにproject.docxという名前のファイルがあります。ファイル名のドット以下の部分は拡張子と呼ばれ、ファイルの種類を示します。project.docxというファイル名からWordの文書ファイルであることがわかり、Users、Al、 Documentsはすべてフォルダ(ディレクトリとも呼ばれます)です。フォルダにはファイルとフォルダ(サブフォルダ)を入れることができます。例えば、project.docxは、Usersフォルダの中にあるAlフォルダの中にあるDocumentsフォルダの中にあります。図10-1はこのフォルダの階層構造を示しています。
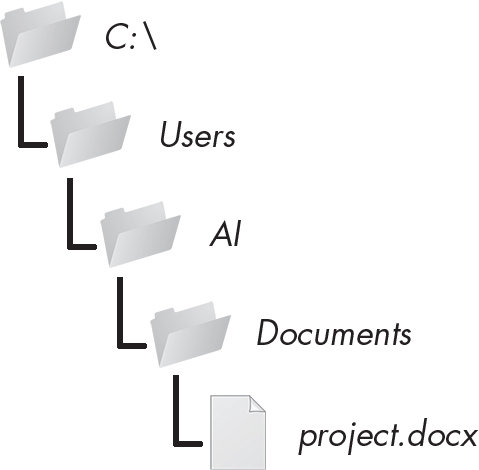
図 10-1:フォルダの階層構造
パスのC:\という部分は、すべてのフォルダを含むルートフォルダです。Windowsでは、ルートフォルダはC:\という名前で、C: ドライブと呼ばれることもあります。macOSとLinuxでは、ルートフォルダは/です。本書では、WindowsスタイルのルートフォルダC:\で表記します。macOSやLinuxで対話型シェルを実行する場合は、/と読み替えてください。
DVDドライブやUSBフラッシュドライブのような追加ボリュームの見え方はOSによって異なります。Windowsでは、D:\やE:\のような、新しいアルファベットのドライブが出現します。macOSでは、/Volumesフォルダ以下に新しいフォルダが出現します。Linuxでは、/mntフォルダ以下に新しいフォルダが出現します。WindowsとmacOSではフォルダ名とファイル名の大文字と小文字を区別しませんが、Linuxでは区別します。
注記
お使いのシステムでは筆者のシステムのファイルやフォルダと違っているでしょうから、本章の例を正確に再現することはできないと思います。お使いのシステムに存在するフォルダで再現するようにしてください。
パス区切りの標準化
フォルダ名の間のパス区切りに、Windowsではバックスラッシュ(\)を使いますが、macOSとLinuxではスラッシュ(/)を使います。
pathlibモジュールのPath()関数はすべてのOSに対応していますので、Pythonのコードではスラッシュに統一するのがベストプラクティスです。ファイル名やフォルダ名の文字列値を渡すと、Path()は正しいパス区切りのファイルパスを文字列で返してくれます。以下の式を対話型シェルに入力してみてください。
>>> from pathlib import Path
>>> Path('spam', 'bacon', 'eggs')
WindowsPath('spam/bacon/eggs')
>>> str(Path('spam', 'bacon', 'eggs'))
'spam\\bacon\\eggs'
WindowsPathオブジェクトではスラッシュ(/)を使っていても、str()関数で文字列に変換するとバックスラッシュ(\)を使うようになります。pathlibをインポートする際にはfrom pathlib import Pathとするのが慣習になっています。そうすればpathlib.Pathの代わりにPathと書くことができます。書くのも読むのも楽になります。
本章の対話型シェルの例はWindowsで実行しているので、WindowsPath('spam/bacon/eggs')と表示されているように、Path('spam', 'bacon', 'eggs')はWindowsPathオブジェクトを返します。Windowsではバックスラッシュを使いますが、対話型シェルでのWindowsPathの表記ではスラッシュが使われています。オープンソースソフトウェアの開発者は歴史的にLinuxを好むためにそうなっています。
このパスのテキストがほしければ、str()関数に渡します。先の例では'spam\\bacon\\eggs'が返されています(バックスラッシュをエスケープするためにバックスラッシュが2つになっている点に注意してください)。この関数をmacOSやLinuxで呼び出したとしたら、Path()はPosixPathオブジェクトを返し、str()関数に渡したら'spam/bacon/eggs'が返されていたはずです(POSIXはUnix系OSの標準規格です)。
Pathオブジェクトを扱うとしても、WindowsPathとPosixPathがソースコードに直接現れることは決してありません。これらのPathオブジェクトは本章で紹介するファイル関連の関数に渡されます。例えば、以下のコードはファイル名のリストをフォルダ名の末尾に連結しています。
>>> from pathlib import Path
>>> my_files = ['accounts.txt', 'details.csv', 'invite.docx']
>>> for filename in my_files:
... print(Path(r'C:\Users\Al', filename))
...
C:\Users\Al\accounts.txt
C:\Users\Al\details.csv
C:\Users\Al\invite.docx
Windowsではバックスラッシュでディレクトリを区切りますから、ファイル名にバックスラッシュを使うことはできません。しかし、macOSとLinuxではバックスラッシュをファイル名に使えます。よって、Path(r'spam\eggs')はWindowsでは2つの別々のフォルダ(あるいはspamフォルダ内のeggsファイル)を指しますが、macOSとLinuxではspam\eggsという名前の一つのフォルダ(またはファイル)を指します。そのため、Pythonのコードでは常にスラッシュを使うのが望ましいです(本書のこのあとの部分もそうしています)。pathlibモジュールはすべてのOSで動作することを保証します。
パスの連結
+演算子は2つの整数または浮動小数点数の足し算に使うのが普通ですが(例えば2 + 2という式は4という整数値に評価されます)、+演算子を2つの文字列値を結合するにも使えます(例えば'Hello' + 'World'という式は'HelloWorld'という文字列値に評価されます)。同様に、/演算子は、割り算に使うのが普通ですが、Pathオブジェクトと文字列を結合することもできます。Path()関数でPathオブジェクトを作成してから調整するのに便利です。
対話型シェルで次のように入力してみてください。
>>> from pathlib import Path
>>> Path('spam') / 'bacon' / 'eggs'
WindowsPath('spam/bacon/eggs')
>>> Path('spam') / Path('bacon/eggs')
WindowsPath('spam/bacon/eggs')
>>> Path('spam') / Path('bacon', 'eggs')
WindowsPath('spam/bacon/eggs')
パスの連結に/演算子を使う際に一つ覚えておく必要のあることがあります。式中の最初の2つの値のうち1つはPathオブジェクトでなければなりません。式は左から右へと評価されていき、/演算子は2つのPathオブジェクトか1つのPathオブジェクトと1つの文字列に使えるのですけれども、2つの文字列には使えません。対話型シェルで以下の内容を実行しようとするとエラーになります。
>>> 'spam' / 'bacon'
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
TypeError: unsupported operand type(s) for /: 'str' and 'str'
式全体がPathオブジェクトに評価されるには、1番目か2番目の値のどちらかがPathオブジェクトでなければなりません。/演算子とPathオブジェクトがPathオブジェクトに評価される様子を以下に示します。
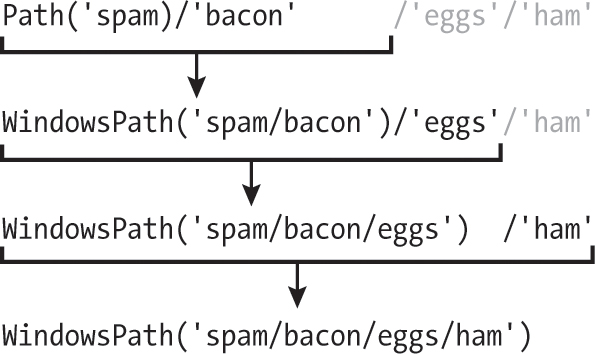
先ほど紹介したTypeError: unsupported operand type(s) for /: 'str' and 'str'エラーメッセージを目にしたら、文字列ではなくPathオブジェクトを式の左側に配置する必要があります。
/演算子は古いos.path.join()関数の代わりに使えます。https://
現在の作業ディレクトリにアクセスする
コンピュータ上で実行されているすべてのプログラムには現在の作業ディレクトリがあります。ルートフォルダで始まらないファイル名やパスは、現在の作業ディレクトリ以下にあるとみなされます。
注記
フォルダはディレクトリよりも新しい呼び方ですが、現在の作業ディレクトリ(あるいは単に 作業ディレクトリ)という用語が標準的で、現在の作業フォルダとはあまり言いません。
Path.cwd()関数で現在の作業ディレクトリの文字列値を取得でき、os.chdir()で現在の作業ディレクトリを変更できます。以下の式を対話型シェルに入力してみてください。
>>> from pathlib import Path
>>> import os
>>> Path.cwd()
WindowsPath('C:/Users/Al/AppData/Local/Programs/Python/Python313')
>>> os.chdir('C:\\Windows\\System32')
>>> Path.cwd()
WindowsPath('C:/Windows/System32')
現在の作業ディレクトリはC:\Users\Al\AppData\Local\Programs\Python\Python313ですから、project.docxというファイル名はC:\Users\Al\AppData\Local\Programs\Python\Python313\project.docxを指します。現在の作業ディレクトリをC:\Windows\System32に変更すると、project.docxというファイル名がC:\Windows\System32\project.docxだと解釈されます。
存在しないディレクトリに変更しようとするとエラーになります。
>>> import os
>>> os.chdir('C:/ThisFolderDoesNotExist')
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
FileNotFoundError: [WinError 2] The system cannot find the file specified:
'C:/ThisFolderDoesNotExist'
pathlibには現在の作業ディレクトリを変更する関数がないので、os.chdir()を使ってください。
os.getcwd()関数は現在の作業ディレクトリの文字列を取得する古い方法です。https://
ホームディレクトリにアクセスする
コンピュータ上には、ホームディレクトリないしホームフォルダと呼ばれる、ユーザー用のフォルダがあります。Path.home()を呼び出すとホームフォルダのPathオブジェクトを取得できます。
>>> from pathlib import Path
>>> Path.home()
WindowsPath('C:/Users/Al')
ホームディレクトリはOSに応じて決まった場所にあります。
- Windowsでは、ホームディレクトリがC:\Users以下にあります。
- macOSでは、ホームディレクトリが/Users以下にあります。
- Linuxでは、ホームディレクトリが/home以下にあります。
自分が書いたスクリプトにはホームディレクトリ以下のファイルを読み書きできるパーミッション(権限)があるはずですから、Pythonプログラムで操作する対象のファイルをホームディレクトリ以下に置くのが望ましいです。
絶対パス指定と相対パス指定
ファイルパスを指定するには、2つの方法があります。
- ルートフォルダ(WindowsではC:\、macOSとLinuxでは/)で始まる絶対パス
- プログラムの現在の作業ディレクトリから相対的に場所が決まる相対パス
Windowsでは、C:\がメインハードドライブのルートです。1960年代にはコンピュータにA:\とB:\という2つのフロッピーディスクドライブがあったことに由来します。Windowsでは、USBメモリとDVDドライブにはD:\以降の文字が割り当てられます。そのストレージメディアのファイルにアクセスするには、そのドライブ文字をルートフォルダとして使います。
ドット(.)とドットドット(..)というフォルダもあります。これらは実際のフォルダではなく、ファイルパスで用いられる特別な名前です。ドットはこのフォルダを表し、ドットドットは親フォルダを表します。
図10-2はフォルダとファイルの例です。現在の作業ディレクトリがC:\baconだと仮定して、相対パスを図に書きました。

図 10-2:現在の作業ディレクトリがC:\baconである場合のフォルダとファイルの相対パス
相対パスの最初の.\はあってもなくてもいいです。例えば、.\spam.txtとspam.txtは同じファイルを指します。
新しいフォルダを作成する
os.makedirs()関数で新しいフォルダを作成できます。以下の式を対話型シェルに入力してみてください。
>>> import os
>>> os.makedirs('C:\\delicious\\walnut\\waffles')
C:\deliciousフォルダだけでなくC:\deliciousの内部にあるwalnutフォルダと、C:\delicious\walnutフォルダの内部にあるwafflesフォルダも作成されます。つまり、os.makedirs()は必要となる中間的なフォルダを作成し、指定したフルパスが存在することを保証します。図10-3はこのフォルダの階層構造を示しています。
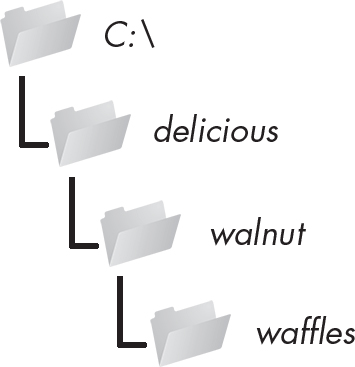
図 10-3:os.makedirs('C:\\delicious\\ walnut\\waffles')の結果
mkdir()メソッドを呼び出すとPathオブジェクトからディレクトリを作成できます。例えば、このコードは私のホームフォルダ以下にspamフォルダを作成します。
>>> from pathlib import Path
>>> Path(r'C:\Users\Al\spam').mkdir()
mkdir()は一度に一つのディレクトリしか作成できないことに注意してください。parents=Trueを渡せば、必要となる親フォルダも同時に作成できるようになります。
絶対パスと相対パスを扱う
Pathオブジェクトのis_absolute()メソッドを呼び出すと、絶対パスを表していればTrueが返され、相対パスを表していればFalseが返されます。例えば、お手元のフォルダで以下のコードを試してみてください。
>>> from pathlib import Path
>>> Path.cwd()
WindowsPath('C:/Users/Al/AppData/Local/Programs/Python/Python312')
>>> Path.cwd().is_absolute()
True
>>> Path('spam/bacon/eggs').is_absolute()
False
相対パスから絶対パスを得たければ、相対パスのPathオブジェクトの前にPath.cwd() /を置きます。「相対パス」というのは現在の作業ディレクトリから相対的に見たパスのことです。absolute()メソッドを呼び出しても絶対パスのPathオブジェクトを取得できます。以下の式を対話型シェルに入力してみてください。
>>> from pathlib import Path
>>> Path('my/relative/path')
WindowsPath('my/relative/path')
>>> Path.cwd() / Path('my/relative/path')
WindowsPath('C:/Users/Al/Desktop/my/relative/path')
>>> Path('my/relative/path').absolute()
WindowsPath('C:/Users/Al/Desktop/my/relative/path')
相対パスが現在の作業ディレクトリ以外のパスから見た相対パスである場合には、Path.cwd()をその起点となるパスに置き換えてください。以下の例は現在の作業ディレクトリではなくホームディレクトリを使って絶対パスを取得しています。
>>> from pathlib import Path
>>> Path('my/relative/path')
WindowsPath('my/relative/path')
>>> Path.home() / Path('my/relative/path')
WindowsPath('C:/Users/Al/my/relative/path')
Pathオブジェクトは絶対パスも相対パスも表せます。Pathオブジェクトがルートフォルダで始まるかどうかという点だけが違います。
ファイルパスの一部を取得する
Pathオブジェクトがあれば、その属性からファイルパスの一部を文字列として抽出できます。既存のファイルパスから新しいファイルパスを組み立てる際に便利です。図10-4に属性を示します。
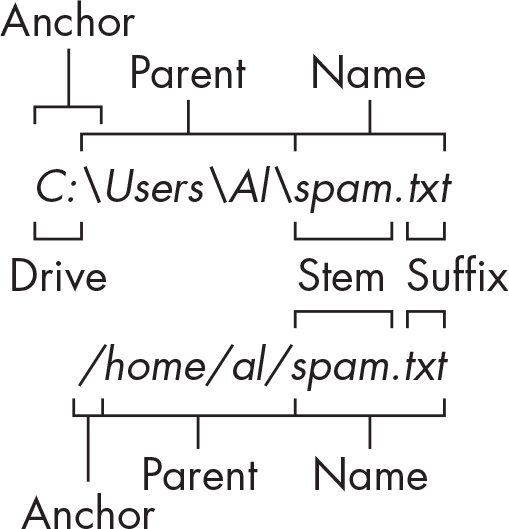
図 10-4:Windowsのファイルパス(上側)とmacOSまたはLinuxのファイルパス(下側)の属性
ファイルパスには次のような部分があります。
- anchorはルートフォルダです。
- Windowsで、driveは、物理ハードドライブその他のストレージデバイスを示すアルファベット1文字です。
- parentは、そのファイルを含むフォルダです。
- ファイルのnameは、stemとsuffixから成り立っています。
WindowsのPathオブジェクトには属性driveがありますが、macOSとLinuxのPathオブジェクトにはありません。属性driveは最初のバックスラッシュを含みません。
対話型シェルでファイルパスからそれぞれの属性を取り出してみましょう。
>>> from pathlib import Path
>>> p = Path('C:/Users/Al/spam.txt')
>>> p.anchor
'C:\\'
>>> p.parent
WindowsPath('C:/Users/Al')
>>> p.name
'spam.txt'
>>> p.stem
'spam'
>>> p.suffix
'.txt'
>>> p.drive
'C:'
別のPathオブジェクトに評価されるparent以外の属性は文字列値に評価されます。パスを区切りたければ、タプルの中に文字列が入っている属性partsにアクセスします。
>>> from pathlib import Path
>>> p = Path('C:/Users/Al/spam.txt')
>>> p.parts
('C:\\', 'Users', 'Al', 'spam.txt')
>>> p.parts[3]
'spam.txt'
>>> p.parts[0:2]
('C:\\', 'Users')
Path()の呼び出しではスラッシュを含む文字列を使っているのに、Windowsのpartsのanchorでは'C:\\'(raw文字列ならエスケープしないr'C:\')と適切なバックスラッシュが使われていることに注意してください。
属性parents(parentと異なり複数形です)は、整数のインデックスでアクセスできるPathオブジェクトの祖先フォルダに評価されます。
>>> from pathlib import Path
>>> Path.cwd()
WindowsPath('C:/Users/Al/Desktop')
>>> Path.cwd().parents[0]
WindowsPath('C:/Users/Al')
>>> Path.cwd().parents[1]
WindowsPath('C:/Users')
>>> Path.cwd().parents[2]
WindowsPath('C:/')
祖先フォルダを追いかけていくと、ルートフォルダに行き着きます。
ファイルサイズとタイムスタンプを調べる
ファイルパスの扱い方がわかったので、ファイルやフォルダについての情報を集めてみましょう。stat()メソッドは、ファイルサイズやタイムスタンプなどを含むstat_resultオブジェクトを返します。
例として、対話型シェルに以下の内容を入力して、Windowsのcalc.exeについて調べてみましょう。
>>> from pathlib import Path
>>> calc_file = Path('C:/Windows/System32/calc.exe')
>>> calc_file.stat()
os.stat_result(st_mode=33279, st_ino=562949956525418, st_dev=3739257218,
st_nlink=2, st_uid=0, st_gid=0, st_size=27648, st_atime=1678984560,
st_mtime=1575709787, st_ctime=1575709787)
>>> calc_file.stat().st_size
27648
>>> calc_file.stat().st_mtime
1712627129.0906117
>>> import time
>>> time.asctime(time.localtime(calc_file.stat().st_mtime))
'Mon Apr 8 20:45:29 2024'
stat()メソッドで返されるstat_resultオブジェクトの属性st_sizeはファイルサイズのバイト数です。この数値を、1024、1024 ** 2、1024 ** 3で割ればそれぞれKB、MB、GB単位になります。
st_mtimeは「最終更新」タイムスタンプです。例えば、.docxWordファイルがいつ最後に変更されたかを知りたいときなどに使います。このタイムスタンプは、1970年1月1日からの経過秒数であるUnix時間です。timeモジュール(第19章で説明します)にはこの数値を人間にとって読みやすい形式に変換する関数があります。
stat_resultオブジェクトには便利な属性があります。
st_size ファイルのバイト単位でのサイズです。
st_mtime そのファイルが最後に変更された「最終更新」タイムスタンプです。
st_ctime 「作成」タイムスタンプです。Windowsではそのファイルが作成された日時です。macOSとLinuxではそのファイルのメタデータ(ファイル名など)が最後に変更された日時です。
st_atime そのファイルが最後に読み取られた「最終アクセス」タイムスタンプです。
更新、作成、アクセスのタイムスタンプは手動で変更することができるので、必ずしも正確とは限らないことに留意してください。
グロブパターンを利用してファイルを検索する
*と?はフォルダ名やファイル名にマッチさせるのに使えます。グロブパターンと呼ばれます。グロブパターンは簡易的な正規表現のようなものです。*はすべてのテキストにマッチし、?は1文字にマッチします。以下の例を見てください。
'*.txt'は.txtで終わるすべてのファイルにマッチします。
'project?.txt'は'project1.txt'や'project2.txt'や'projectX.txt'にマッチします。
'*project?.*'は'catproject5.txt'や'secret_project7.docx'にマッチします。
'*'はすべてのファイル名にマッチします。
フォルダのPathオブジェクトには、そのフォルダ内でグロブパターンにマッチするものを一覧で取得するglob()メソッドがあります。glob()メソッドはジェネレータオブジェクト(本書の範囲外です)を返すので、対話型シェルで確認するにはlist()に渡す必要があります。
>>> from pathlib import Path
>>> p = Path('C:/Users/Al/Desktop')
>>> p.glob('*')
<generator object Path.glob at 0x000002A6E389DED0>
>>> list(p.glob('*'))
[WindowsPath('C:/Users/Al/Desktop/1.png'), WindowsPath('C:/Users/Al/
Desktop/22-ap.pdf'), WindowsPath('C:/Users/Al/Desktop/cat.jpg'),
WindowsPath('C:/Users/Al/Desktop/zzz.txt')]
glob()が返すジェネレータオブジェクトをforループで使うこともできます。
>>> from pathlib import Path
>>> for name in Path('C:/Users/Al/Desktop').glob('*'):
>>> print(name)
C:\Users\Al\Desktop\1.png
C:\Users\Al\Desktop\22-ap.pdf
C:\Users\Al\Desktop\cat.jpg
C:\Users\Al\Desktop\zzz.txt
バックアップフォルダへのコピーや名前の変更など、フォルダ内のすべてのファイルに何らかの処理をする必要がある場合は、glob('*')メソッドを呼び出せばPathオブジェクト内のファイルとフォルダの一覧を取得できます。lsやdirなどのコマンドラインのコマンドでもグロブパターンはよく使われます。第12章でコマンドラインについて詳しく説明します。
有効なパスかどうかをチェックする
Pythonには、存在しないパスを渡すとエラーでクラッシュする関数がたくさんあります。幸い、Pathオブジェクトには、指定したパスが存在するかどうか、ファイルなのかフォルダなのかをチェックするメソッドがあります。pがPathオブジェクトだとすると、以下の挙動になります。
- p.exists()を呼び出すと、そのパスが存在すればTrueを、存在しなければFalseを返します。
- p.is_file()を呼び出すと、そのパスが存在してかつファイルであればTrueを、そうでなければFalseを返します。
- p.is_dir()を呼び出すと、そのパスが存在してかつディレクトリであればTrueを、そうでなければFalseを返します。
私のコンピュータの対話型シェルでこれらのメソッドを実行した結果を示します。
>>> from pathlib import Path
>>> win_dir = Path('C:/Windows')
>>> not_exists_dir = Path('C:/This/Folder/Does/Not/Exist')
>>> calc_file_path = Path('C:/Windows
/System32/calc.exe')
>>> win_dir.exists()
True
>>> win_dir.is_dir()
True
>>> not_exists_dir.exists()
False
>>> calc_file_path.is_file()
True
>>> calc_file_path.is_dir()
False
exists()メソッドでDVDやUSBドライブが取り付けられているかどうかを判定することができます。例えば、私のWindowsマシンにD:\という名前のUSBドライブのボリュームがあるかどうかを確認したければ、次のようにします。
>>> from pathlib import Path
>>> d_drive = Path('D:/')
>>> d_drive.exists()
False
おっと、USBドライブを差し込むのを忘れていたようです。
古いos.pathモジュールのos.path.exists(path)、os.path.isfile(path)、os.path.isdir(path)関数でも、Path関数と同じことができます。Python3.6以降では、これらの関数が、ファイルパスの文字列だけでなくPathオブジェクトも取ることができるようになりました。
ファイルの読み書き
フォルダと相対パスに慣れると、読み書きするファイルの場所を指定することができます。以下の数節ではプレーンテキストファイルに適用する関数を紹介します。プレーンテキストファイルは基本的なテキスト文字だけを含み、フォント、サイズ、色などの情報は含みません。.txt拡張子のテキストファイルや.py拡張子のPythonスクリプトファイルはプレーンテキストファイルです。れらのファイルはWindowsのメモ帳やmacOSのテキストエディットアプリケーションで開くことができ、プログラムから開いて内容を読み取って通常の文字列値のように扱うことが簡単にできます。
ワープロソフトのファイル、PDF、画像、スプレッドシート、実行ファイルなど、その他のファイルはすべてバイナリファイルです。バイナリファイルをメモ帳やテキストエディットで開くと、図10-5のようにぐちゃぐちゃで判読できません。
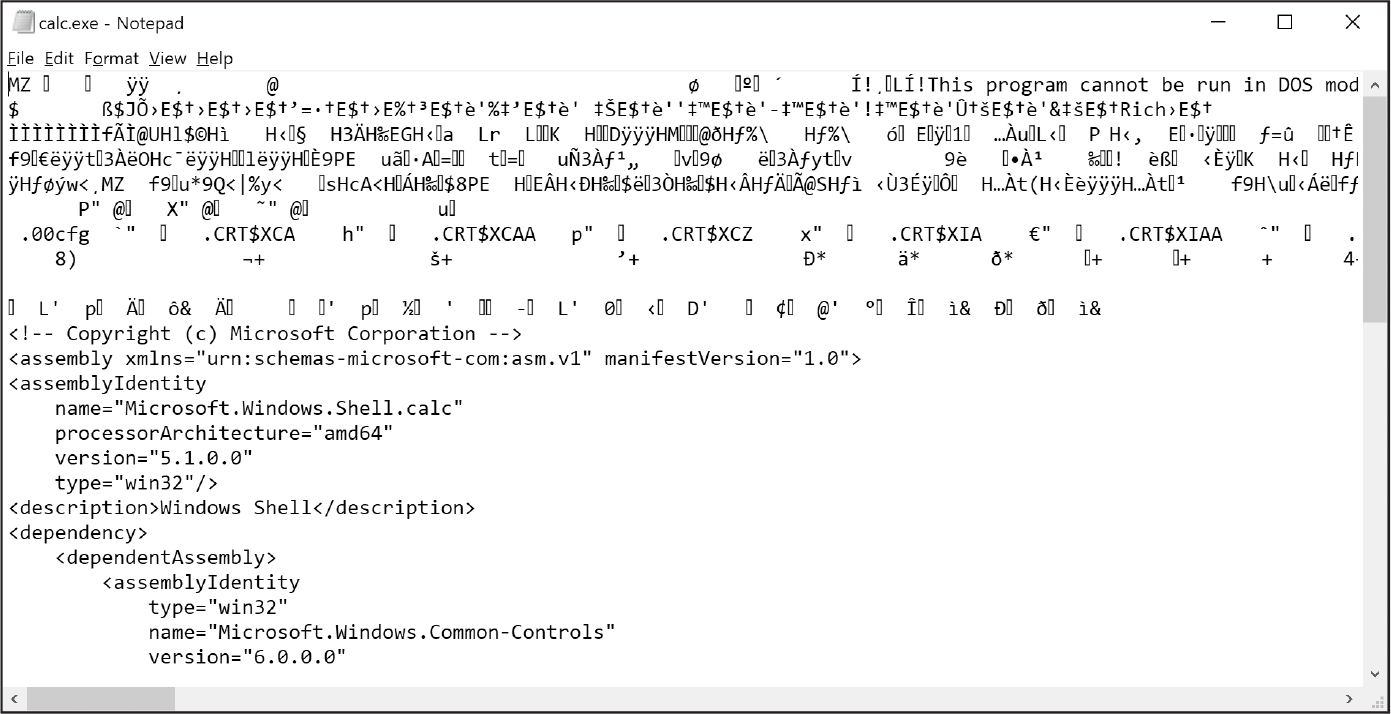
図 10-5:Windowsのcalc.exeプログラムをメモ帳で開いた状態
バイナリファイルはそのファイル固有の方法で処理しなければならず、本書では生のバイナリファイルを直接読み書きする方法は扱いません。バイナリファイルを扱いやすくしてくれるモジュールはたくさんあります。本章の後半では、その中の一つであるshelveモジュールを紹介します。
pathlibモジュールのread_text()メソッドは、テキストファイルの内容全体を一つの文字列として返します。write_text()メソッドは渡した文字列が書かれた新しいテキストファイルを作成します(あるいは既存のファイルを上書きします)。以下の式を対話型シェルに入力してみてください。
>>> from pathlib import Path
>>> p = Path('spam.txt')
>>> p.write_text('Hello, world!')
13
>>> p.read_text()
'Hello, world!'
このメソッドを呼び出すと、'Hello, world!'という内容のspam.txtというファイルを作成します。write_text()が返す13は、ファイルに13文字書き込まれたことを示します(この返り値は無視して差し支えありません)。read_text()を呼び出すとそのファイルの中身を読み取り、一つの文字列'Hello, world!'として返します。
これらのPathオブジェクトメソッドは、ファイルの基本的な読み書きしかサポートしていません。ファイルに書き込むには、open()関数を使ってファイルオブジェクトを操作するほうが一般的です。以下の3ステップでPythonでのファイルの読み書きができます。
1. open()関数を呼び出してFileオブジェクトを取得します。
2. Fileオブジェクトについてread()メソッドまたはwrite()メソッドを呼び出します。
3. Fileオブジェクトについてclose()メソッドを呼び出してファイルを閉じます。
以下の節ではこのステップを実践します。
ファイルを操作するときには、ファイル拡張子(.txt、.pdf、.jpgなど)を素早く確認できると便利です。WindowsとmacOSでは、ファイル拡張子がデフォルトでは非表示になっていることがあります。その場合は、spam.txtと表示されずにspamと表示されます。拡張子を表示するには、Windowsではファイルエクスプローラーの設定を開き、「ファイル名拡張子」のような欄にチェックを入れてください。macOSでは、Finderの設定を開き、「すべてのファイル名拡張子を表示」のような欄にチェックを入れてください。(この設定の場所や文言はOSのバージョンによって微妙に異なります。)
ファイルを開く
open()関数に開きたいファイルのパスを渡すとそのファイルを開くことができます。絶対パスでも相対パスでも構いません。open()関数はFileオブジェクトを返します。
メモ帳やテキストエディットを使ってhello.txtという名前のテキストファイルを作ってください。そのテキストファイルにHello, world!と入力して、ホームフォルダに保存してください。それから以下の対話型シェルの内容を実行してください。
>>> from pathlib import Path
>>> hello_file = open(Path.home() / 'hello.txt', encoding='UTF-8')
open()関数は指定したファイルを「プレーンテキスト読み取り」モード(「読み取り」モード)で開きます。ファイルを読み取りモードで開くと、そのファイルのデータを読み取ることはできますが、書き込んだり変更したりすることはできません。Pythonでファイルを開くときのデフォルトは読み取りモードです。デフォルトに頼らずopen()関数の第二引数に'r'という文字列を渡して明示的にモードを指定することもできます。例えば、open('/Users/Al/hello.txt', 'r')はopen('/Users/Al/hello.txt')と同じです。
名前付きパラメータencodingでは、ファイルのバイトをPythonのテキスト文字列に変換するときのエンコーディングを指定します。macOSやLinuxでデフォルトとして用いられている'utf-8'を指定すればほぼ間違いないです(macOSやLinuxではエンコーディングを指定しなくてもデフォルトのUTF-8が用いられますが、後述のようにWindowsではデフォルトで別のエンコーディングが用いられます)。しかし、Windowsでは'cp1252'(拡張ASCII)をデフォルトのエンコーディングとして用いているので、非英語文字のUTF-8でエンコードされたテキストをWindowsで読み取ろうとすると問題が発生するかもしれません。ですので、プレーンテキストファイルの読み書き追記モードでファイルを開く際にはopen()関数呼び出しにencoding='utf-8'を渡す習慣をつけるとよいです。(訳注:日本語のWindowsでは'cp1252'ではなく'cp932'をデフォルトのエンコーディングとして用いていますが、デフォルトがUTF-8でないことに変わりはないので、関数呼び出しにencoding='utf-8'を渡す習慣をつけるとよいことに変わりはありません。エンコーディングは常にUTF-8で統一すると間違いが少なくなります。)バイナリの読み書き追記モードにはencodingという名前付きパラメータはありません。
open()を呼び出すとFileオブジェクトが返されます。Fileオブジェクトはコンピュータ上のファイルを表しています。すでにおなじみのリストや辞書と同じようなPythonの型の一つです。先の例では、Fileオブジェクトを変数hello_fileに格納しました。ファイルの読み書きをするときは、hello_fileに格納されているFileオブジェクトのメソッドを呼び出します。
ファイルの内容を読み取る
Fileオブジェクトがあれば、その内容を読み取れます。ファイルの中身全体を一つの文字列として読み取るなら、Fileオブジェクトのread()メソッドを使います。hello_fileに格納したhello.txtのFileオブジェクトの例を続けましょう。以下の式を対話型シェルに入力してみてください。
>>> hello_content = hello_file.read()
>>> hello_content
'Hello, world!'
ファイルの中身は一つの大きな文字列値だと考えられます。read()メソッドはそのファイルに保存されている文字列を返します。
readlines()メソッドを使うと、ファイルから、一つの大きな文字列値ではなく、各行の文字列値のリストを取得できます。例えば、hello.txtと同じディレクトリ内にsonnet29.txtという名前のファイルを作成し、以下の内容を貼り付けてください。
When, in disgrace with fortune and men's eyes,
I all alone beweep my outcast state,
And trouble deaf heaven with my bootless cries,
And look upon myself and curse my fate,
4つの行を改行で区切ってください。そして、対話型シェルに次のように入力します。
>>> sonnet_file = open(Path.home() / 'sonnet29.txt', encoding='UTF-8')
>>> sonnet_file.readlines()
["When, in disgrace with fortune and men's eyes,\n", 'I all alone beweep
my outcast state,\n', 'And trouble deaf heaven with my bootless cries,\n',
'And look upon myself and curse my fate,']
最終行以外は改行文字\nが文字列の最後にあります。一つの大きな文字列値よりも文字列のリストのほうが扱いやすい場合が多いです。
ファイルへの書き込み
Pythonでは、print()関数が画面に文字列を書き込むのと同じように、ファイルに書き込むことができます。読み取りモードでファイルを開くと書き込みはできません。「プレーンテキスト書き込み」モード(「書き込み」モード)または「プレーンテキスト追記」モード(「追記」モード)でファイルを開く必要があります。
書き込みモードでは既存のファイルを上書きします。変数の値を新しい値で上書きするのと似ています。open()の第二引数に'w'を渡すと書き込みモードになります。追記モードは、既存のファイルの末尾にテキストを追記します。変数を上書きするのではなく変数に格納されているリストに値を追加するのと似ています。open()の第二引数に'a'を渡すと追記モードになります。
open()に渡された名前のファイルが存在しなければ、書き込みモードと追記モードでは新しいファイルを作成します。ファイルの読み書きが終われば、再びファイルを開く前にclose()メソッドを呼び出してください。
一連の流れを試してみましょう。以下の式を対話型シェルに入力してみてください。
>>> bacon_file = open('bacon.txt', 'w', encoding='UTF-8')
>>> bacon_file.write('Hello, world!\n')
14
>>> bacon_file.close()
>>> bacon_file = open('bacon.txt', 'a', encoding='UTF-8')
>>> bacon_file.write('Bacon is not a vegetable.')
25
>>> bacon_file.close()
>>> bacon_file = open('bacon.txt', encoding='UTF-8')
>>> content = bacon_file.read()
>>> bacon_file.close()
>>> print(content)
Hello, world!
Bacon is not a vegetable.
まず、bacon.txtを書き込みモードで開いています。bacon.txtファイルはまだ存在しませんから、Pythonがそのファイルを作成します。開いたファイルについてwrite()メソッドを呼び出し、write() に'Hello, world!\n'という文字列引数を渡しているので、その文字列がファイルに書き込まれ、改行文字を含めて書き込んだ文字数が返されます。それからそのファイルを閉じています。
先ほど書き込んだ文字列のファイルを上書きするのではなく追記するために、そのファイルを追記モードで開いています。そのファイルに'Bacon is not a vegetable.'と書き込んで閉じています。最後に、ファイルの内容を画面に表示するために、そのファイルをデフォルトの読み取りモードで開き、read()を呼び出して、Fileオブジェクトをcontentに格納してからそのファイルを閉じ、contentを出力しています。
write()メソッドは文字列の終わりに改行を自動的に追加しないことに注意してください。改行を自動的に追加するprint()関数とは異なり、自分で改行文字を入れなければなりません。
open()関数にはファイル名の文字列の代わりにPathオブジェクトを渡すこともできます。
with文
プログラムからopen()を呼び出して開いたファイルはすべてclose()を呼び出して閉じなければなりません。close()関数を入れ忘れることもあれば、状況によってはプログラムがclose()呼び出しを飛ばしてしまうこともあります。
Pythonのwith 文を使うと自動的にファイルを閉じてくれます。with文は、Pythonがリソース管理に利用するコンテキストマネージャを作成します。ファイル、ネットワーク接続、メモリのセグメントなどのリソースには、たいてい、プログラムから利用するために割り当てて解放する、開始段階と終了段階があります(with文はファイルを開くときに使うことが多いでしょう)。
with文では、リソースの割り当て時にコードブロックを追加し、プログラム実行がコードブロックを抜けたときにリソースを解放します。return文や処理されない例外が送出されたときなどにコードブロックを抜けてリソースが解放されます。
以下はファイルに書き込んでからその内容を読み取る典型的なコードです。
file_obj = open('data.txt', 'w', encoding='utf-8')
file_obj.write('Hello, world!')
file_obj.close()
file_obj = open('data.txt', encoding='utf-8')
content = file_obj.read()
file_obj.close()
with文を使うとこうなります。
with open('data.txt', 'w', encoding='UTF-8') as file_obj:
file_obj.write('Hello, world!')
with open('data.txt', encoding='UTF-8') as file_obj:
content = file_obj.read()
with文の例では、プログラム実行がブロックを抜けたときにwith文が自動的に呼び出してくれるので、close()を呼び出していないことに注意してください。with文はopen()関数から取得したコンテキストマネージャに基づいて動作します。コンテキストマネージャを自分で作成するのは本書の範囲外ですが、オンラインドキュメントのhttps://
shelveモジュールで変数を保存する
shelveモジュールを使うと、Pythonプログラム中の変数をバイナリ形式のshelfファイルに保存できます。そうすると別のプログラムを実行する際に保存したデータを復元できます。これによりプログラムに保存して開く機能を備えられます。例えば、プログラムを実行して何らかの設定を入力したとして、その設定をshelfファイルに保存し、次回実行時に読み込むことができます。
対話型シェルに次の内容を入力して、shelveを使う練習をしてみましょう。
>>> import shelve
>>> shelf_file = shelve.open('mydata')
>>> shelf_file['cats'] = ['Zophie', 'Pooka', 'Simon']
>>> shelf_file.close()
shelveモジュールでデータの読み書きをするには、最初にshelveをインポートします。次に、ファイル名を渡してshelve.open()を呼び出し、その返り値を変数に格納します。shelf値は辞書のように変更できます。変更が終わればshelf値についてclose()を呼び出します。これでshelf値がshelf_fileに保存されます。上記のプログラムでは、リストcatsを作成し、shelf_file['cats'] = ['Zophie', 'Pooka', 'Simon']と書いてそのリストを(辞書のように)'cats'というキーの値としてshelf_fileに格納し、shelf_fileについてclose()を呼び出しています。
Windowsでこのコードを実行すると、現在の作業ディレクトリにmydata.bak、mydata.dat、mydata.dirの3つの新しいファイルが見えるはずです。macOSでは、mydata.dbという1ファイルが、Linuxではmydataという1ファイルが見えるはずです。これらのバイナリファイルに保存したデータが含まれています。これらのバイナリファイルの形式は重要ではありません。shelveモジュールが何をしているかがわかればよいのであって、どのようにしているのかを知る必要はありません。プログラムのデータをどのようにしてファイルに保存するかはモジュールが面倒を見てくれます。
shelveモジュールを使うと、あとでshelfファイルを再び開いてデータを取得できます。shelf値には読み取りや書き込みといったモードは存在せず、開けば読み書きできます。以下の式を対話型シェルに入力してみてください。
>>> shelf_file = shelve.open('mydata')
>>> type(shelf_file)
<class 'shelve.DbfilenameShelf'>
>>> shelf_file['cats']
['Zophie', 'Pooka', 'Simon']
>>> shelf_file.close()
shelfファイルを開いてデータが正しく保存されるかを確かめます。shelf_file['cats']が先に作成したのと同じリストを返しています。リストが正しく保存されていることがわかったので、close()を呼び出します。
辞書と同様に、shelf値にはkeys()メソッドとvalues()メソッドがあります。shelfのキーと値をリストのような値で返します。これらの返り値は本物のリストではありませんから、リスト形式にするにはlist()関数に渡します。以下の式を対話型シェルに入力してみてください。
>>> shelf_file = shelve.open('mydata')
>>> list(shelf_file.keys())
['cats']
>>> list(shelf_file.values())
[['Zophie', 'Pooka', 'Simon']]
>>> shelf_file.close()
プレーンテキストはメモ帳やテキストエディットのようなテキストエディタで読めるファイルを作成できますが、Pythonプログラムのデータを保存したい場合にはshelveモジュールが使えます。
プロジェクト4:ランダムな設問ファイルの生成
35人の生徒がいるクラスの地理の先生が、アメリカ合衆国の州都のテストの設問を作ろうとしているとします。悪い生徒がいてカンニングするかもしれません。設問の順番をランダムにしてそれぞれ違うようにして、カンニングできないようにしたいです。これを手で行うのは大変で退屈な作業です。ここでPythonを活用します。
このプログラムには以下の内容が必要です。
- 35人分の設問を作成する
- 1人分につき50問の選択式の設問をランダムな順番で作成する
- 1つの正解と3つの不正解の選択肢をランダムな順番で用意する
- 設問を35個のファイルに書き込む
- 正解を35個のファイルに書き込む
コードには以下の内容が必要になります。
- 州と州都を辞書形式で保存する
- 設問テキストと解答テキストについてopen()、write()、close()を呼び出す
- 設問と選択肢の順番をrandom.shuffle()でランダムにする
それでは始めましょう。
ステップ1:設問のデータを辞書形式で保存する
まず骨組みのスクリプトを作成して、設問のデータを用意します。次のコードをrandomQuizGenerator.pyという名前で保存してください。
# randomQuizGenerator.py - 設問と選択肢を
# ランダムな順番で作成し、解答ファイルも作成する
❶ import random
# キーが州で値が州都の設問データ
❷ capitals = {'Alabama': 'Montgomery', 'Alaska': 'Juneau', 'Arizona':
'Phoenix', 'Arkansas': 'Little Rock', 'California': 'Sacramento', 'Colorado':
'Denver', 'Connecticut': 'Hartford', 'Delaware': 'Dover', 'Florida':
'Tallahassee', 'Georgia': 'Atlanta', 'Hawaii': 'Honolulu', 'Idaho': 'Boise',
'Illinois': 'Springfield', 'Indiana': 'Indianapolis', 'Iowa': 'Des Moines',
'Kansas': 'Topeka', 'Kentucky': 'Frankfort', 'Louisiana': 'Baton Rouge',
'Maine': 'Augusta', 'Maryland': 'Annapolis', 'Massachusetts': 'Boston',
'Michigan': 'Lansing', 'Minnesota': 'Saint Paul', 'Mississippi': 'Jackson',
'Missouri': 'Jefferson City', 'Montana': 'Helena', 'Nebraska': 'Lincoln',
'Nevada': 'Carson City', 'New Hampshire': 'Concord', 'New Jersey': 'Trenton',
'New Mexico': 'Santa Fe', 'New York': 'Albany', 'North Carolina': 'Raleigh',
'North Dakota': 'Bismarck', 'Ohio': 'Columbus', 'Oklahoma': 'Oklahoma City',
'Oregon': 'Salem', 'Pennsylvania': 'Harrisburg', 'Rhode Island': 'Providence',
'South Carolina': 'Columbia', 'South Dakota': 'Pierre', 'Tennessee':
'Nashville', 'Texas': 'Austin', 'Utah': 'Salt Lake City', 'Vermont':
'Montpelier', 'Virginia': 'Richmond', 'Washington': 'Olympia', 'West
Virginia':'Charleston', 'Wisconsin': 'Madison', 'Wyoming': 'Cheyenne'}
# 35人分の設問を作成
❸ for quiz_num in range(35):
# TODO:設問ファイルと解答ファイルを作成
# TODO:設問のヘッダーを書き込み
# TODO:州の順番をシャッフル
# TODO:50の州をループして各設問を作成
このプログラムは設問と選択肢の順番をランダムにしますから、randomモジュールの関数を使えるようにインポートします(❶)。変数capitalsはアメリカ合衆国の州をキー、州都の値とする辞書です(❷)。35人分の設問を作成しますから、このコードでは、35回ループするforループ内で35の設問ファイルと解答ファイルを作成します(❸)。今のところはTODOコメントを入れています。この数値を変えれば作成するファイル数を変えられます。
ステップ2:設問ファイルの作成
TODOの部分を埋めていきましょう。
ループ内のコードは35回実行され、1回のループで1つの設問ファイルを作成します。よって、ループ内では1つの設問ファイルを作成することに集中します。まず、設問ファイルを作成します。固有のファイル名と共通のヘッダー部分(生徒名、日付、授業時間の欄)が必要になります。次に、ランダムな順番の州のリストが必要です。これを使って設問と解答を作成します。
次の内容をrandomQuizGenerator.pyに追加してください。
# randomQuizGenerator.py - 設問と選択肢を
# ランダムな順番で作成し、解答ファイルも作成する
--snip--
# 35人分の設問を作成
for quiz_num in range(35):
# 設問ファイルと解答ファイルを作成
quiz_file = open(f'capitalsquiz{quiz_num + 1}.txt', 'w', encoding='UTF-8') ❶
answer_file = open(f'capitalsquiz_answers{quiz_num + 1}.txt', 'w', encoding='UTF-8') ❷
# 設問のヘッダーを書き込み
quiz_file.write('Name:\n\nDate:\n\nPeriod:\n\n') ❸
quiz_file.write((' ' * 20) + f'State Capitals Quiz (Form{quiz_num + 1})')
quiz_file.write('\n\n')
# 州の順番をシャッフル
states = list(capitals.keys())
random.shuffle(states) ❹
# TODO:50の州をループして各設問を作成
設問はcapitalsquiz<N>.txtというファイル名にします。<N>はforループのカウンターquiz_numに由来する固有の番号です。capitalsquiz<N>.txtという設問ファイルに対応する解答はcapitalsquiz_answers<N>.txtというファイル名にします。ループの反復ごとに、ファイル名中の{quiz _num + 1}というプレースホルダーを固有の番号で置き換えます。例えば、最初の設問ファイルと解答ファイルは、capitalsquiz1.txtとcapitalsquiz _answers1.txtになります。書き込みモードでファイルを開くためにopen()関数の第二引数に 'w'を渡して呼び出してこれらのファイルを作成します(❶❷)。
write()文で生徒が埋める設問のヘッダー部分を作成します(❸)。最後に、random.shuffle()関数を利用してランダムな順番に並べたアメリカ合衆国の州のリストを取得します(❹)。
ステップ3:選択肢を作成する
次は別のforループで各設問に対するAからDの選択肢を作成します。あとで入れ子のforループで選択肢をファイルに書き込みます。コードは次のようになります。
# randomQuizGenerator.py - 設問と選択肢を
# ランダムな順番で作成し、解答ファイルも作成する
--snip--
# 50の州をループして各設問を作成
for num in range(50):
# 正解と不正解を取得
correct_answer = capitals[states[num]]
wrong_answers = list(capitals.values())
del wrong_answers[wrong_answers.index(correct_answer)]
wrong_answers = random.sample(wrong_answers, 3)
answer_options = wrong_answers + [correct_answer]
random.shuffle(answer_options)
# TODO:設問と選択肢を設問ファイルに書き込み
# TODO:解答ファイルの書き込み
正解を作成するのは簡単です。辞書capitalsの値に格納されています。このループではシャッフルされたリストstatesの州を反復処理し、capitalsから州を探し、その州の州都をcorrect_answerに格納します。
不正解の選択肢のリストを作成するのは少しややこしいです。辞書capitalsの値を複製して、正解を削除し、random.sample()関数を使ってリストから3つの値をランダムに選びます。第一引数がリスト、第二引数が取得する個数です。これら3つの不正解の選択肢と正解の選択肢を結合して選択肢のリストを作成します。最後に、正解が常にDになってしまわないように、この選択肢の順番をランダムに並べ替えます。
ステップ4:ファイルへの書き込み
あとは設問と解答をファイルに書き込みます。コードは次のようになります。
# randomQuizGenerator.py - 設問と選択肢を
# ランダムな順番で作成し、解答ファイルも作成する
--snip--
# 50の州をループして各設問を作成
for num in range(50):
--snip--
# 設問と選択肢を設問ファイルに書き込み
quiz_file.write(f'{num + 1}. Capital of {states[num]}:\n')
❶ for i in range(4):
❷ quiz_file.write(f" {'ABCD'[i]}. {answer_options[i]}\n")
quiz_file.write('\n')
# 解答ファイルの書き込み
❸ answer_file.write(f"{num + 1}.{'ABCD'[answer_options.index(correct_answer)]}\n")
quiz_file.close()
answer_file.close()
forループは、answer_optionsリストの選択肢を0から3まで反復処理してファイルに書き込みます(❶)。'ABCD'[i]の部分では、文字列'ABCD'を配列として扱い、ループの反復ごとに'A'、'B'、'C'、'D'と評価します(❷)。
ループの最終行のanswer_options.index(correct_answer)では、ランダムに並べ替えられた選択肢の中から正解のインデックスを見つけて、正解ファイルに正解の選択肢のアルファベットを書き込みます(❸)。
このプログラムを実行すると、以下のようなcapitalsquiz1.txtファイルが作成されるはずです。もちろん、設問と解答は、random.shuffle()呼び出しの結果によって変わります。
Name:
Date:
Period:
State Capitals Quiz (Form 1)
1. What is the capital of West Virginia?
A. Hartford
B. Santa Fe
C. Harrisburg
D. Charleston
2. What is the capital of Colorado?
A. Raleigh
B. Harrisburg
C. Denver
D. Lincoln
--snip--
対応するcapitalsquiz_answers1.txtテキストファイルは次のようになっています。
1. D
2. C
--snip--
設問をランダムに並べて対応する解答を手動で作成するには何時間もかかりますが、少しプログラミングの知識があればその退屈な作業を自動化できます。州都の設問に限らず、どのような選択式の試験にでも使えます。
まとめ
OSはファイルをフォルダ(ディレクトリとも呼ばれます)にまとめて整理し、その場所をパスで表します。コンピュータ上で実行するプログラムにはすべて現在の作業ディレクトリがあり、ファイルパスをフルパス(絶対パス)で指定しなくても、そのディレクトリからの相対的な位置で指定できます。pathlibモジュールとos.pathモジュールにはファイルパスを操作する関数がたくさんあります。
プログラムがテキストファイルを直接扱うこともできます。open()関数でファイルを開くと、(read()メソッドで)ファイルの中身を一つの大きな文字列として読み取るか、(readlines()メソッドで)文字列のリストとして読み取ります。open()関数は書き込みモードや追記モードでファイルを開くこともでき、そうすれば新しいテキストファイルを作成したり既存のテキストファイルに追記したりできます。
前章では、大量のテキストをプログラムで使うために、手で入力するのではなくクリップボードを活用しました。本章ではハードドライブのファイルを読み取る方法を学びました。ファイルはクリップボードよりも安定しています。
次章では、コピー、削除、リネーム、移動など、ファイル自体を操作する方法を説明します。
練習問題
1. 相対パスは何に対して相対的ですか?
2. 絶対パスは何で始まりますか?
3. WindowsでPath('C:/Users') / 'Al'は何に評価されますか?
4. Windowsで'C:/Users' / 'Al'は何に評価されますか?
5. os.getcwd()関数とos.chdir()関数は何を行いますか?
6. .フォルダと..フォルダとは何ですか?
7. C:\bacon\eggs\spam.txtについて、どの部分がディレクトリ名で、どの部分がファイル名ですか?
8. プレーンテキストファイルについてopen()を呼び出すときの3つのモード引数は何ですか?
9. 既存のファイルを書き込みモードで開くとどうなりますか?
10. read()メソッドとreadlines()メソッドはどう違いますか?
11. shelf値はどのデータ構造と似ていますか?
練習プログラム
練習のために以下のプログラムを設計して書いてください。
Mad Libs(訳注:あらかじめ用意された物語の空欄に入れる適当な言葉を、一人が別の人にまとめて言ってもらい、完成した文章を読み上げる言葉遊び)
テキストファイルを読み取り、そのテキストファイル中のADJECTIVE、NOUN、ADVERB、VERBにユーザーがテキストを入力する、Mad Libsプログラムを作成してください。例えば、次のテキストが用意されているとします。
The ADJECTIVE panda walked to the NOUN and then VERB. A nearby NOUN was
unaffected by these events.
このプログラムは、ユーザーに置き換える言葉を尋ねます。
Enter an adjective:
silly
Enter a noun:
chandelier
Enter a verb:
screamed
Enter a noun:
pickup truck
次のようなテキストファイルが作成されます。
The silly panda walked to the chandelier and then screamed. A nearby
pickup truck was unaffected by these events.
このプログラムは、結果を新しいテキストファイルとして保存するとともに、画面にも表示します。
正規表現によるファイル内検索
フォルダ内のすべての.txtファイルを開き、ユーザーが入力した正規表現にマッチするすべての行を検索して表示するプログラムを書いてください。